

christuf
-
Posts
272 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by christuf
-
-
On 12/24/2020 at 10:10 PM, HarshReality said:
So, maybe Im loosing my mind as I just got to this docker plug.. but I cant even change the password. Ideas?
Password randomly created on install. Go to the docker page, click on the Pihole item and select "Console".
From that pop-up, run the following command:
pihole -a -pYou can then reset (or remove) the password.
-
20 minutes ago, schuu said:
Hi Binhex,
Just wondering when/if you will be updating sonarr to V3? like the radarr container was?
thanks.
See here: https://github.com/binhex/documentation/blob/master/docker/faq/sonarr.md
Easy flawless update
-
 3
3
-
-
Did a restart, and all still ok. No issues on any drives.
I have noticed that memory usage is creeping up - wondering if a docker I have has a leak or something. I'm going to keep the Dashboard and Logging window open, and will leave it for the day and see what's happened when I get home tonight.
Can't for the life of me seem to find any way to look at what processes are using memory. Can anyone point me to the right place in the GUI or on the terminal please?
Still a lot suspicious of the drive errors from yesterday too...
Thank you all!
-
Thank you all. After posting this, I moved the drives to different slots, and rebooted. When the Unraid management page came up, everything was normal.
So then I started parity check (as I'd had an unclean shutdown), which went off and started, then I went to bed. Woke up this morning, and the web interface on the sever is non-responsive (refresh the page and it says "Waiting for 10.0.1.21". Can't access via SMB either. Tried to go onto the actual terminal, but that has completely crashed too.
Something not right here... any guidance as to how to diagnose why the server is crashing? I'm thinking perhaps it's all connected to this issue, and I've either got faulty cable(s) or backplane gone bad.
Again, very much appreciated all!
-
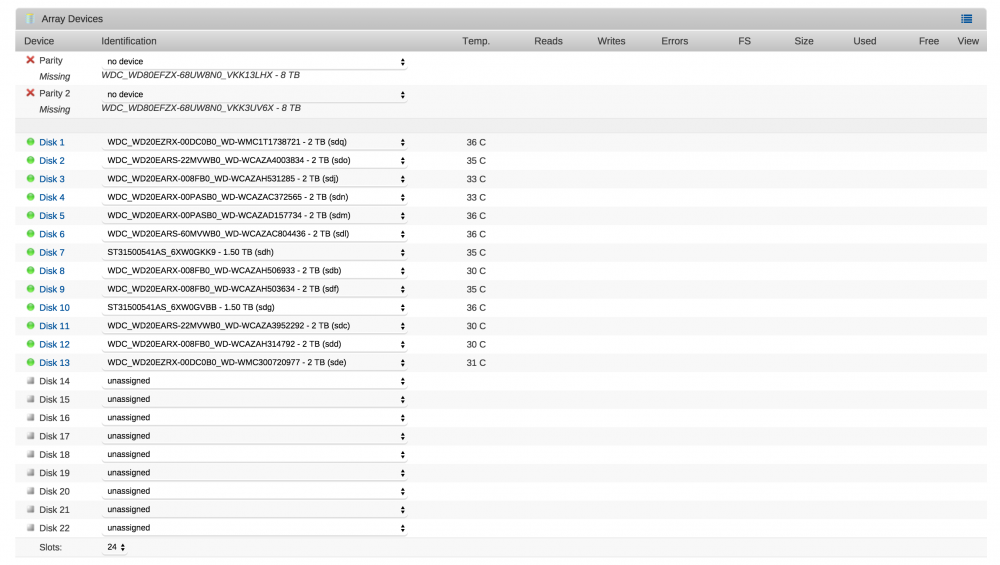
Hello - after many years of happy, broadly uninterrupted usage of my Unraid box, I rebooted tonight after finding the server had crashed. When it came back online, I found both of my dual parity drives are "missing" in the drive list.
Hmmmm... seems unlikely they would have both failed at exactly the same time, so restarted again, and took photos of the boot screen, and as expected, they are showing up as connected drives to the BIOS. But low and behold, still not showing up in the GUI.
Attached are screenshots of the GUI, the BIOS output, and log. I was going to try to run SMART test, but don't have a [sdx] designation I can see to run it against.
Thinking that perhaps it's a bad backplane? Just seems strange it's showing up ok on the BIOS screen if that's the case.Any assistance in diagnosing this would be very very gratefully appreciated. Please let me know if there's anything else I can share. Thank you!!
tower-syslog-20170502-2217.zip
.thumb.JPG.e5990e764ea15d68bfb43da3288c43c8.JPG)
.thumb.JPG.82174bb8cf26ed7af8a2339055d3e743.JPG)
-
I don't understand the fully filling up of your server. You can always add more hard drives, or upgrade your parity and other drives for increased capacity. If your case does not allow for more drives, upgrade the case.
Cannot say enough good things about being on latest 6.x version.
I'm at 23 drives, so not really much incremental capacity to add to that from new drives - true, they are all 2TB drives (back in the day when that was the limit), so guess I could go through and replace them with 3TB to get some extra space, but figure I might as well bite the bullet and just start with a new one. Is that irrational?
Upgrading to 6.x sounds appealing, but the thing just works now - does everything I want.
I've also got a few janky things that run - e.g., there's an autoencoder that runs every night that goes through and transcodes any new files down to a specified setting. I worked pretty extensively with someone on this forum to get it working how I wanted, and don't for the life of me remember how I set it up.
I'm not sure how I migrate all my existing Plex / Sickbeard data across with new dockers (if that's what they run in now).
Ultimately, I'm just nervous about breaking something in an upgrade for no real benefit (it just sits there and does its job)... but maybe I'm missing out on something I don't realize.
-
Sweet - thank you. I'll look at this when I procure my second server. Appreciate the assistance!
-
Awesome - thank you. Do both servers need to be on 6.1.x?
-
What version unRAID?
Currently 5.0-rc8a - really just a case of if it ain't broke, don't fix it... with a second server, I think I would use 6.x and migrate the Plex / SB / SAB onto that, then upgrade my current server to 6.x.
Long story short - old version, but would upgrade when everything is working on the new server.
Thank you!
-
Hi all, and happy New Year!
I'm starting to get near fully filling my present server, and thinking about how I tackle adding a second server to my set-up. I run Plex / Sickbeard / SAB, so would need to be able to run these services on one of the servers, with it being able to see directories on the other server.
I've had a dig through the forum, but couldn't find anything directly about this.
Very grateful for any thoughts and suggestions.
-
Sorry for the delay - got called out of town for a while.
Ran the memtest without issue. When I restarted, I noticed a command in the console relating to sdk... and then I remembered that I had a command in my go file to force a spindown on the hot spare. So my problem is solved!
Glad I noticed the output in the console as I suspect we'd have been going round and round on this... would have probably ended up changing hardware without success!
Thank you for the help @dgaschk.
-
Do an overnight memtest.
Thank you - will run tonight an post the results tomorrow am.
-
CORSAIR Enthusiast Series TX650 V2 650W. Currently powering 14xgreen drives + 1x7200
-
Thank you for the reponse @dgaschk
This is what it spits out:
smartctl 5.40 2010-10-16 r3189 [i486-slackware-linux-gnu] (local build) Copyright (C) 2002-10 by Bruce Allen, http://smartmontools.sourceforge.net Smartctl: Device Read Identity Failed (not an ATA/ATAPI device) A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options.
Like I say though, I don't think it's drive related - I have 2 disks outside the array... let's call them Disk 1 and 2. SMART previously gave this same error when disk 1 was on sdk, and I got a good SMART report on disk 2. When I rebooted disk 2 got put on sdk and now I get a good readout for disk 1. Am I making sense here?
-
Hi,
Happy New Year to everyone!
I've woken up to the monthly parity check, but found that there was (for the first time) an error (just the one). I have the monthly parity check set not to correct, so before committing the parity check error, started digging through the syslog to see if there was anything obviously amiss, and found a bunch of I/O errors (attached). The errors relate to /dev/sdk, which is a disk not used in the array (fortunately!) The particular drive in question is connected to a SAS2-AOC-LP with 7 other drives. It therefore seems as if the parity error and drive issue aren't connected.
I went into unmenu and tried to check the smart report for the drive, but got a message saying
I powered down, opened up and reseated all the cables. Powered back up, and restarted the array, and still getting the same error message in the syslog. Now the funny thing is that for some reason a different drive got assigned to sdk, but it is the same drive that has the error. The previous drive is now fully querable through unmenu's smart report.
I checked the SMART reports for all disks, and none have any errors so haven't bothered to post these here (although happy to do so of course)
Could someone be kind enough to give me some advice on this? Please let me know if there's any other information that would be helpful.
-
Thanks for everyone's help. I have it up and running, although it is very slow to add releases. Could be my group settings with minimum number of files and size to make a release.
I have ./newznab.sh start running from my crono_settings folder.
How to you stop newznab process? kill - 9 and the pid?
Should just be able to go:
./newznab.sh stop
-
Here is the group screen after I ran update binary / release. it wasn't newznab.sh, i ran the php file.
So, i guess it's accurate to say, it shows last time updated if the group actually has new binaries. (sorry 33weeks was last post lol)
cause as you can see, some show few seconds ago, but still some says 13 hours ago
so then my question is.. do you have multiple groups activated? which one do you expect to see the update?
--
Edit:
Actually, misunderstood your post a bit.
if you think there's a problem with the update script though, that newznab_screen.sh is probably better way to see what's going on.
Yes - have 8 groups activated. They're generally all very active groups so would expect to see updates across the board.
-
I think it does, because when I then manually run the update_binaries.php script, the dates (for the majority) refresh to 1 minute.
I have one group with an old date, but then again it has only 1 release. So in general I agree, but for active groups I think that this is a pretty reliable measure.
-
christuf,
newznab.sh under cron_script is actually not meant for cron jobs.. not sure why they call it cron_scripts. so it won't work with influence's cron script as i mentioned earlier.
you just have to run it after changing the path.
newznab.sh may not delete the pid file though... kill is suppsoed to delete that pid file but it doesn't really work sometimes.
one thing i want to ask you though, was your sabnzbd active at all? in order for newznab to update, i found out that it needs connection with the usenet server.
so for example, if your usenet server offer 30 connection and you have set up 30 connection in sabnzbd , and your sabnzbd was actively downloading something, newznab wont be able to get that connection it needs..
what i did was my usenet server offers like 50 connection, so i lowered it to 30 in sabnzbd so there will always be connection available for newznab script.
if this is not a problem, i would check the basic. are you able to run update_binary and update_release fine?
another thing i want to ask is how are you checking if it updated or not?
Thank you jangjong for the response.
OK - understand re: cronning the job. Have taken it out of my cron queue.
I'm actually using a different usenet server to avoid these problems... so not sure what is going on. Yes - I can run those files perfectly though the command line.
I've switched over to using the newzbnzb_screen.sh command. Seems to do the same thing, but displays the output verbosely. I don't mind tying up one of my screens with this command, so guess I'll just live with this for the time being. Pity as the other file was much cleaner.
You can check the last update of each of the groups by going to the newznab homepage and clicking on "Groups". It lists each of the activated groups and shows the time of last update [This is from memory, so please excuse any mistakes]
-
running
./newznab.sh start
should be enough to run update every 10 mins..
This will run the update_binaries & update_releases every 10 mins without need to setup a cron job?
Yep, you just need to change NEWZNAB_PATH in that file though. If you need to run it faster than every 10 mins, you can change NEWZNAB_SLEEP_TIME to less than 600. That's in seconds.
If you open up newznab.sh file, you will see what's going on.
It just uses While loop to go on and on until it stops.
This can probably be added to go file to run it everytime it boots, but i wonder what would be the best way to stop it when the array stops..
but that newznab.sh file should be good to use for now.
@jangjong:
I tried this last night - it appeared to have run once but then didn't update again. (Left configured at 600 seconds)
I then killed the process and used @influencer's cron script to load the newznab.sh script on a frequent basis, which caused another update but again hasn't updated the binaries in 10 hours.
The process still appears to be active. This line is listed in my active processes:
763 root 20 0 2564 656 520 S 0 0.0 0:00.00 newznab.sh
'
I also (unsurprisingly) found the PID file in /var/run/
This error is getting thrown out to the syslog every time the cron runs:
Dec 14 08:30:01 Tower crond[1392]: exit status 1 from user root /mnt/cache/.custom/www/newznab/misc/update_scripts/cron_scripts/newznab.sh start > /dev/null
I want it to run every 15 minutes and pull down and process the fresh binaries. Do you have any ideas what is going wrong here?
Thank you very much!!
Chris
-
running
./newznab.sh start
should be enough to run update every 10 mins..
This will run the update_binaries & update_releases every 10 mins without need to setup a cron job?
-
All,
Sorry for the delay - as Influencer knows, I spent a good deal of time fighting with my setup to get newznab working (all due to being on non-current releases of UnRAID and SimpleFeatures). Then I lost a HDD and was leaving my array carefully alone while it rebuilt the disk.
Once you're there, it really is a straightfoward process to get it installed and running - it seems that many of you have found this out already.
Is there anyone out there who would still like a detailed walkthrough of the process to get it working? I'm happy to do so, but there may be sufficient info in this thread already to do the install. Let me know your thoughts...
-
oh good..
i was trying to install it myself on my machine, but kept getting 404 errors after installing newznab.. only can access the main page of newznab.
probably doing something wrong lol
If you got there, then the webserver is installed which has been half my battle. Go to (webserver address, assuming that you put the newznab files in the root web directory):
xx.xx.xx.xx:81/install
I know. I did install it. It has the install lock and the main page works.
Edit:
I think it has to do with rewrite rules though.
I didnt want to put newznab in the web root, so put it in a directory.. so when i go xx.xx.xx.xx:81/newznab/www/ , it works, when i click login, it tries to go to xx.xx.xx.xx:81/newznab/www/login, but with the rewrite rule, it should actually go to xx.xx.xx.xx:81/newznab/www/index.php.php?page=$1.
i dont know how to add rewriterule for Lighttpd.. so i should wait for the instruction lol
Sorry - I misread your post. Great - think that should be easy. From Influencer:
Go to /mnt/cache/server/misc/urlrewriting/ [or wherever you installed the files] and open up lighttpd.txt. Copy everything inside the file. Then navigate to /boot/config/plugins/simplefeatures and open up the lighttpd.cfg, paste the copied text to the end of this file and save. Restart the webserver if it is started at this point so it picks up the new rules.
-
oh good..
i was trying to install it myself on my machine, but kept getting 404 errors after installing newznab.. only can access the main page of newznab.
probably doing something wrong lol
If you got there, then the webserver is installed which has been half my battle. Go to (webserver address, assuming that you put the newznab files in the root web directory):
xx.xx.xx.xx:81/install


.JPG.c33a228b0364aecd2bd2bb9236a3718c.JPG)
.JPG.7e530fbd5fa5eb544180a041e24c8302.JPG)
6.8.3 Docker locking up server, pegging core utilization every few days. Logs attached.
in General Support
Posted
@jonesy8485
I'm having similar issue - had a couple of questions
1) How did you track the container ID given to Plex? I can't find that string of gobbledygook anywhere in Unraid web interface to confirm
2) Did you resolve the issue? If so, please could you let me know what you did?
Many thanks!