




tdotr6
Members
-
Joined
-
Last visited
-
It's clear this is caused by the recent patch where unraid identifies they've resolved the macvlan issue.. I've been on macvlan for many years with this hardware and it's stable. Now that I've had issues after patch, and as you @JorgeBsuggested, I've changed to ipvlan and we're stable with 0 errors for 17 days. Unraid should be responding to this as I've not been the only one experiencing this since the recent patch.
-
Anything here to indicate he has potentially bad memory or this the go to suggestion around here?
-
This is posted above, yes that was indeed a screenshot showing he didn't even look at it yet continued to provide bad advice. @dirkinthedark already did that , and agreed issues with that as well. SEEMS for now, although I have ran macvlan for many years, 2 updates ago they did a big change around this, they clearly broke it for the ones that were working and cause some kernel panics and other issuues. since I have been on ipvlan for a few days, no issues. I very much do want to look at going to TrueNAS once coral support is avail, i'm jumping ship.
-
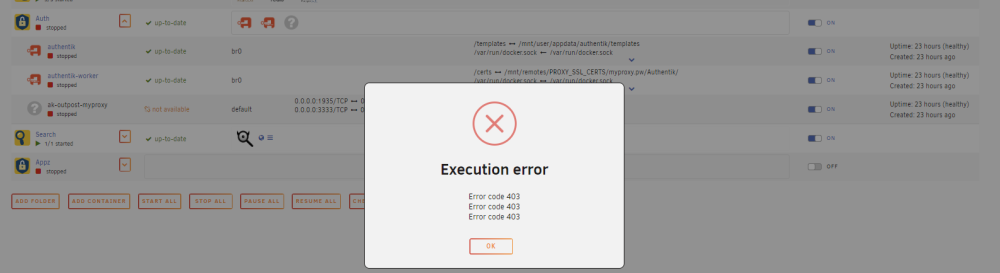
A moderator is indeed much a representative of Limetech my dude. What? Still haven't checked out the secondary Diag posted. Great support from the peers lol.. Thank mod's I am going to take this time and move myself to TrueNAS Scale. This was the push I needed. Thank you.
-
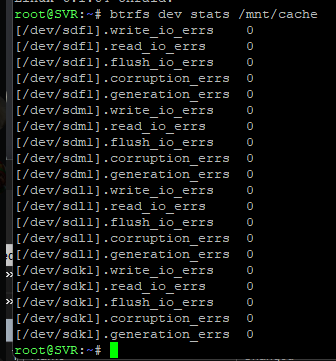
What's with the attituded? You've initially neglected to ignore I already did a mem test that PASSED before I came to this post. and I have as well posted diag dump from a few weeks prior when the system had the same issue and I remembered to get the dump before I rebooted. Why ignore it? Why ignore the extra logs I am giving you to make your product better? It is very interesting with the amount of logs I've provided you , you've yet to still review the diagnostics provided from the earlier crash. And I've provided logs back 30 days of all BTRFS errors /checksum and kernel .. Yet, you're going to reply with it's my right? I guess it's your right to not actually want to help people who have been a dedicated user, supporter and patron of this product for nearly a decade.. and the first time I come looking for help this is how i'm treated.. Maybe it's just time to look at unRAID alternatives.
-
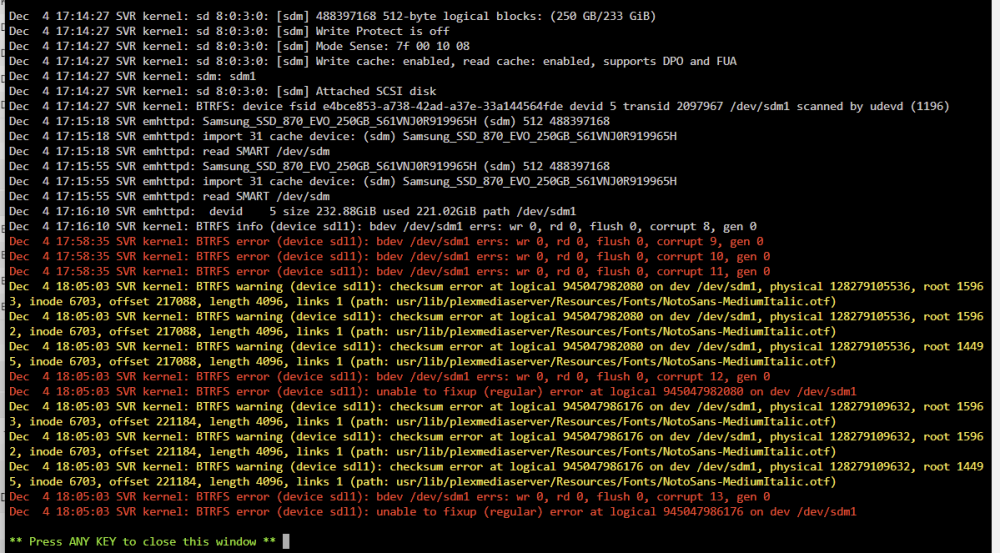
I think I will take 2 sticks of RAM from a machine i've had since 2017 and swap it out. That said, I have looked at some of my dashboards , it looks like the crash happens on the first svr-diagnostics-20231222-0956.zip @ 2:56 AM . Dec 22 02:56:31 SVR kernel: BTRFS critical (device sdf1): corrupt leaf: root=5 block=272887431168 slot=110 ino=5203363 file_offset=229376, invalid ram_bytes for file extent, have 65535, should be aligned to 4096 Dec 22 02:56:31 SVR kernel: BTRFS info (device sdf1): leaf 272887431168 gen 51281 total ptrs 194 free space 16 owner 5 Dec 22 02:56:31 SVR kernel: item 0 key (5203347 1 0) itemoff 16123 itemsize 160 Dec 22 02:56:31 SVR kernel: inode generation 40834 size 42 mode 40755 I must as as well, do you see a similarity in the crash in svr-diagnostics-20231222-0956.zip & svr-diagnostics-20231222-1126.zip both were taken before a reboot while experiencing the issue. such, container errors started and I was unable to start a stopped container again. I would suspect if its RAM I would see similar but I am not exp. looking at these logs like you are.. I don't see the similarity in the crashes to point to a RAM (or other hardware) issue. @JorgeB - https://pastebin.com/BKKBwb3a You ref the checksum errors as being the thing for me to focus on but I must disagree. I have syslogs I am exporting so I don't have any loss of details from the last 30 days... it just doesn't seem to be the smoking gun you've pointed it out to be?
-
Yes, I understand that I am just pointing out it's new as well as tested. Are you ref to these checkum errors? Any other tests you recommended to test board/cpu?

-
I've changed to ipvlan and will monitor.. thank you @itimpi and @JorgeB svr-diagnostics-20231222-1126.zip
-
mem test has been done and I don't have bad RAM , this is fairly new RAM as well. I've also rebuild the cache pool a few weeks ago. when I was first experiencing errors I rebuild and I replaced 2 SSD's with brand new ones in the cache pool because I thought maybe the SSD's were dying as they were 6 years old. Now all SSD's are very new in the pool of 4 . As well my friend is getting the very very similar ( corrupt 8 instead of 12 ) errors on his server and he is on totally different hardware. I can have him as well post his dumps to this post. Same thing with the containers errors in the AM etc. Server can run fine for a few days with no issues and then all of a sudden issues. Agian, system was VERY stable before upgrading from .4 is there a way we can just roll back to before .4? 2 upgrade versions before.. I only upgraded again as I thought it would fix the issues, I should have rolled back then. RE: First thing change docker network to ipvlan and reboot. Will do.
-
Hello unRAID Team! I have had nothing but stability with my system for the last several years, rock solid. Recently encountering errors every day, or every other day.. I can't figure out a pattern or trigger. I have another friend who is having almost identical issues and the only thing we have done recently is upgrade to 6.12.6. We run almost the same containers as well, and our hardware is different, he is on a later gen intel and ddr5 , I am still using ddr4. I have attached 2 dumps of 2 deferent times of when I have experienced the following. Check dashboard in AM and find a 1 or 2 containers stopped - Try to start them and unable to. They are never the same containers that are experiencing this. If I stop another container now, it wont' start and even thou it looks like the others are running they don't work correctly.. for instance, grafana is running but I can't get to the dashboard - I get {"traceID":""} , but I am able to get to Frigate and access all of my cameras and footage.. It's very strange! A reboot and it all seems to be fine again.. no ongoing errors, until the issue repeats. checking syslogs today I do see repeated svr-diagnostics-20231216-1719.zip svr-diagnostics-20231222-0956.zip

-
Can you PLEASE... add an option to not remove the recycle bin folder when it's empty.. This is causing issues with programs such as Sonarr that are not smart enough to just 'delete' , looks like it's doing more of a move function thus causing lots of errors when unraid recycle bin purges.. things only work well again when I delete a manual file so the ./recycle bin folder comes back..





