

-
Posts
208 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by JoeUnraidUser
-
-
Is there a documented process of converting the main cache from BTRFS to a ZFS cache?
Thanks for any help.
-
12 hours ago, Lordbye said:
Hi , i'm using yoru script, and for a little time it is ok, now i have a problem
log is growing anyway, but i don't know..where...or which file because:
root@MyNas:/var/log# df /var/log/ Filesystem 1K-blocks Used Available Use% Mounted on tmpfs 262144 18836 243308 8% /var/log ----------------------------------- root@MyNas:/var/log# du -mh -c 0 ./pwfail 152K ./unraid-api 0 ./swtpm/libvirt/qemu 0 ./swtpm/libvirt 0 ./swtpm 0 ./samba/cores/rpcd_lsad 0 ./samba/cores/samba-dcerpcd 0 ./samba/cores/winbindd 0 ./samba/cores/nmbd 0 ./samba/cores/smbd 0 ./samba/cores 212K ./samba 0 ./plugins 0 ./pkgtools/removed_uninstall_scripts 4.0K ./pkgtools/removed_scripts 12K ./pkgtools/removed_packages 16K ./pkgtools 4.0K ./nginx 0 ./nfsd 40K ./libvirt/qemu 0 ./libvirt/ch 76K ./libvirt 796K . 796K total --------------------- root@LordbyeNas:/var/log# ls -lha total 336K drwxr-xr-x 11 root root 740 May 2 16:21 ./ drwxr-xr-x 15 root root 360 Dec 31 2019 ../ -rw------- 1 root root 0 Nov 20 22:25 btmp -rw-r--r-- 1 root root 0 Apr 28 2021 cron -rw-r--r-- 1 root root 0 Apr 28 2021 debug -rw-r--r-- 1 root root 71K May 1 19:42 dmesg -rw-r--r-- 1 root root 20K May 3 07:02 docker.log -rw-r--r-- 1 root root 6.9K May 1 19:43 faillog -rw-r--r-- 1 root root 67 May 3 08:24 gitcount -rw-r--r-- 1 root root 12K May 3 08:24 gitflash -rw-r--r-- 1 root root 63K May 1 19:43 lastlog drwxr-xr-x 4 root root 140 May 1 19:44 libvirt/ -rw-r--r-- 1 root root 358 May 2 00:07 maillog -rw-r--r-- 1 root root 0 May 1 19:42 mcelog -rw-r--r-- 1 root root 0 Apr 28 2021 messages drwxr-xr-x 2 root root 40 Aug 10 2022 nfsd/ drwxr-x--- 2 nobody root 60 May 1 19:43 nginx/ lrwxrwxrwx 1 root root 24 Nov 20 22:24 packages -> ../lib/pkgtools/packages/ drwxr-xr-x 5 root root 100 May 1 19:43 pkgtools/ drwxr-xr-x 2 root root 980 May 3 08:00 plugins/ drwxr-xr-x 2 root root 40 May 3 16:24 pwfail/ lrwxrwxrwx 1 root root 25 Nov 20 22:26 removed_packages -> pkgtools/removed_packages/ lrwxrwxrwx 1 root root 24 Nov 20 22:26 removed_scripts -> pkgtools/removed_scripts/ lrwxrwxrwx 1 root root 34 May 1 19:43 removed_uninstall_scripts -> pkgtools/removed_uninstall_scripts/ drwxr-xr-x 3 root root 340 May 3 16:24 samba/ -rw-r--r-- 1 root root 33 Dec 31 2019 scan lrwxrwxrwx 1 root root 23 Nov 20 22:24 scripts -> ../lib/pkgtools/scripts/ -rw-r--r-- 1 root root 0 Apr 28 2021 secure lrwxrwxrwx 1 root root 21 Nov 20 22:24 setup -> ../lib/pkgtools/setup/ -rw-r--r-- 1 root root 0 Apr 28 2021 spooler drwxr-xr-x 3 root root 60 Sep 27 2022 swtpm/ -rw-r--r-- 1 root root 100K May 2 16:21 syslog -rw-r--r-- 1 root root 100K May 2 16:21 syslog.1 drwxr-xr-x 2 root root 80 May 2 16:21 unraid-api/ -rw-r--r-- 1 root root 0 May 1 19:42 vfio-pci -rw-r--r-- 1 root root 587 May 1 19:42 wg-quick.log -rw-rw-r-- 1 root utmp 6.8K May 1 19:43 wtmpi don't undestand where is the difference from 796k to 18836 K...
The script trims the Docker logs in the "/var/lib/docker/containers" directory.
The script doesn't trim any log files in the "/var/log" directory.
You could easily adapt the script to trim the logs in the "/var/log" directory.
I am not sure why you are seeing different usage numbers.
-
7 hours ago, PartyingChair said:
Hey,
I copy and pasted that, the copy and pasted the directory in that I want to finish with this:
#!/bin/bash
limit=10M
source="/mnt/user/Media/Ingress/Compressed"limit=$(echo $limit | cut -d 'M' -f 1)
for dir in "$source"/*/
do
size=$(du -sBM "$dir" | cut -d 'M' -f 1)if (( $limit > $size ))
then
echo remove: $dir
rm -rf "$dir"
fi
doneBut I get error
du: cannot access '/mnt/user/Media/Ingress/Compressed/*/': No such file or directory
/tmp/user.scripts/tmpScripts/Delete empty compressed folders/script: line 12: ((: 10000000 > : syntax error: operand expected (error token is "> ")This is what the folder looks like, I am trying to deleted the folder ".ISdr1c"
For more info, this is a temporary folder created by handbrake when it is compressing my files. it deletes it on it's own, but I want to automatically turn off handbrake in the morning and when I do that, it DOES leave those folders there.
Do you know if I need to mofify something in your script to make it work?
Thanks in advance!
".ISdr1c" is a dot file so the script would not see it. Try substituting the following line with the "." Infront of the "*":
for dir in "$source"/.*/
-
On 1/26/2023 at 5:44 AM, gandalf15 said:
Thank you very much. I actually found help on Reddit.
What I did was update, stopped all dockers and shut down docker service. I started then the docker safe new perms plugin. After 20 hours I canceld it and excluded 1 share (beside appdata), since it took too long and the docker had to get back online (glad it works).After that I run "sudo chown -Rc nobody:users /mnt/user/appdata"
When this was finished, I added to all docker the value PUID 99 and PGID 100 (some had it already).
Then my rclone mount made problems, since it was mounted as root:root. I then added PUID 99, PGID 100 AND UNMASK 000 to my mount script as an argument.
In the end it seems like all is working again.To be honest, I have no idea if this was secure or/and right. But it works again, this is what counts (now) for me.
Glad you got it fixed. I know some other people had some problems with PUID and PGID being set to 0 which is "root". A PUID of 99 is "nobody" and PGID of 100 is "users" which is the correct way to do it. I also like to set UMASK to 000. If you have any permission problems in the future and need to run the commands to fix them, you don't need to stop your dockers. Just let the commands run and use your dockers as normal.
-
Is there going to be an automated way to convert the encrypted XFS drive to an encrypted ZFS drive or will we have to move everything off that drive and then move it back again?
-
To fix the file ownership and permissions for my Dockers I do the following:
chown -cR nobody:users /mnt/user/appdata chmod -cR ug+rwX,o-rwx /mnt/user/appdata
I set the following settings in each of my dockers to fix ownership and permission problems:
PUID = 99 PGID = 100 UMASK = 000
PUID of 99 equates to "nobody", PGID of 100 equates to "users", and UMASK of 000 allows for full access.
To fix the ownership and permissions of my array I do the following:
chown -cR nobody:users /mnt/disk[0-9]* chmod -cR ug+rwX,o-rwx /mnt/disk[0-9]*
To fix the file ownership and permissions on my entire server I do the following:
chown -cR nobody:users /mnt/user/appdata /mnt/disk[0-9]* chmod -cR ug+rwX,o-rwx /mnt/user/appdata /mnt/disk[0-9]*
You do not have stop your Dockers during the process of fixing the ownership and permissions of the array or the entire server.
-
 3
3
-
-
11 hours ago, itimpi said:
I have not heard of it creating duplicate files unless you told it to do so (I.e used copy rather than move)when working normally.
I guess another possibility might be a system crash while attempting a move as it uses a copy/delete strategy so if the system crashed before the delete part you could end up with the source left behind.
I'm not sure why the move didn't work. I used the plugin back when it first came out. I know I did a move and the system didn't crash. I sat there and waited for the move to happen. Maybe something happened to the process. I think the process died in the background during the move. Some files were moved to the new drive, some files were duplicates, and some files were not moved.
I just tried the plugin again and I verified the plugin did move the files correctly. So, whatever problem I had back then did not occur again.
-
36 minutes ago, RogerTheBannister said:
Just learning my way around the terminal now. Ok, so most folders are showing:
drwxrwxrwx 1 nobody userswith the problem folder showing:
dr-xr-xr-x 1 nobody usersIf I look inside the problem folder, its contents are all over the place too:
drwxrwxrwx 1 myname users 4096 Jan 25 13:04 Folder 1/ drwxrwxrwx 1 root root 94208 Jan 25 13:03 Folder 2/ drwxr-xr-x 1 nobody users 183 Jan 25 01:35 Folder 3/ drwxr-xr-x 1 nobody users 162 Jan 24 17:31 Folder 4/ drwxr-xr-x 1 nobody users 48 Jan 24 18:24 Folder 5/In the example above, the folders 3 4 and 5 were created automatically by a docker app. Folder 1 was copied over from Windows - has it inhereted permissions from Windows?
I could use that New Permissions feature, but like you say I'd like to figure out what's going wrong.
Pretty sure I would have made the folder from within Windows after setting up the share. I have also been using Krusader.
It could be a permission setting in your docker configuration. If there is a setting for UMASK, set it to 007. The UMASK would only affect the files created by the docker application.
If you created the folders from Windows, I am not sure about why the permissions were set that way. Make sure in the share settings that SMB User Access is set to Read/Write.
I have not used Krusader before, however, I was looking at the documentation and it does have the ability to set permissions of files and folders that you create so maybe you could have accidently created them with those permissions.
-
3 minutes ago, itimpi said:
There had to be something else going on as the ‘mv’ command would not create files with the ‘conflicted’ added to the file names.
there should be no difference between using ‘mc’ or ‘mc’ commands as long as you make no mistake in the command line for ‘mv’.
if you are using any recent version of Unraid then the recommended tool to use is now the Dynamix File Manager (installed as a plugin) as this is Unraid aware and can protect the user from some common mistakes that can cause data loss.
I have actually had the problem of Dynamix File Manager producing duplicate files on disks in the past. So, I stopped trusting it a while ago. Does it work correctly now?
-
I am assuming your share is "/mnt/user/Media". If it is not, substitute the name of your share in the command.
Run the following from a terminal to fix your file ownership and permissions:
chown -cR nobody:users /mnt/user/Media chmod -cR ug+rw,ug+X,o-rwx /mnt/user/Media -
I'm not sure about the renaming of files to "[conflicted]", however, never use the "mv" command unless you are really sure what you are doing. It just causes problems. In the future use the program "mc" from the command line to move files between disks and it does not give these problems. You should check it out.
Just type "mc" from the command line and it will bring up a very intuitive interface to copy, move, or delete files. Hit tab to go from side to side. You can also right click on files or directories individually to select them instead of moving, copying, or deleting all of them.
If you do have problems of duplicate files on disks in the future, use the following script to check for duplicate files on your disks, however, I don't think that is your problem at this time since they do not have the exact same names.
At this point I would do the move again with "mc" and then after that is completed, I would get rid of the "[conflicted]" files or save them off to another directory until you feel comfortable that all your files have been moved.
-
Is there any advantage to converting the single array drives from XFS to ZFS? If we do convert them to ZFS, would they be faster, slower, or the same speed?
-
1 minute ago, trurl said:
Not enough detail in that description. At least, what little you did say there is not possible.
Parity would not be valid if you did it that way. And it wouldn't let you replace the disk without rebuilding anyway. Did you New Config and rebuild parity?
I can't remember but I must have done a New Config to remove the bad drive from that disk assignment and assigned the new disk to that disk assignment and I do remember doing a parity check after adding the disk.
-
-
2 minutes ago, trurl said:
Replace 6TB parity with 14TB and rebuild. Replace 3TB with 14TB and rebuild. Repeat as necessary until all 14TB drives are used. Replace another data drive with original 6TB parity and rebuild. With single parity you can only rebuild one disk at a time.
If you keep the original disks with their data, then you will still have their contents if there are any problems. All that rebuilding will be a good test of all the disks, since all disks are read to rebuild a disk. If they have already passed extended tests even better.
Might also consider dual parity with that many disks.
The problem is that I tried the method of rebuilding drives from parity twice over the years and both times after hours of waiting it got all the way near the end and failed. The only luck I have had with parity is when hard drives have failed, I was still able to copy the emulated data off to other drives.
-
15 minutes ago, trurl said:
First thing is to clear up the terminology. ADD means add a disk to a new slot. REMOVE means remove an assigned disk without replacing it.
If you ADD a data disk to an array that already has valid parity, Unraid will clear the disk if it hasn't been precleared, so parity will remain valid. This is the one and only scenario where Unraid requires a clear disk.
In order to REMOVE a disk from an array that already has valid parity, you must New Config without that disk and rebuild parity. Technically, it is possible to clear a disk to be removed while it is still in the array, then New Config without that disk and not rebuild parity, but it doesn't save any time and is a lot more complicated.
So, the answer to your question is basically YES, except it isn't a parity check, it is New Config and parity sync.
I would like to rearrange some of my disk assignments. If I were to do new New Config and assign disk to different disk numbers will it leave that data intact on those disks or will it clear them when I assign them?
-
I guess I could leave the 6TB as parity and just dump the data of 1 of the 3TB drives to a usb drive and replace that 3TB drive with a 14TB drive and run preclear on it. Then dump the data from the other 3 3TB drives to the 14 TB and replace those drives with the remaining 3 14TB drives and run preclear on them. Then as a final step unassign the 6TB drive from parity and assign 1 of the new 14TB drives to parity that way I will have parity the whole time. Do you know if it will try to do a parity check each time I remove and add hard drives?
-
Ii already took me about a week and a half to do the SMART tests on the 4 drives one at a time. But from what you are saying, I guess it is worth it to suck it up and take a couple more days to finish it off properly. Thanks for your advice. It just seems like it has been forever since I got the drives and haven't even been able to use them yet. The next step after that is going to be migrating all the terabytes of data which is going to take forever. It's going to be a juggling act to do that since I'm already maxed out in my case with 12 hard drives. So, I am going to have to remove and add drives back and forth to migrate the data. I was hoping to just add each drive one at a time. But then I would have to do the preclear on each drive one at a time.
-
-
Script to trim white space from the end of each line of text files.
#!/bin/bash # Trim white space from the end of each line of text files. if [ $# -eq 0 ] || [ "$1" == "--help" ] then printf "Usage: trimWhite <files>...\n" exit 0 fi for file in "${@}" do printf "$file\n" perl -pi -e 's/\s+$/\n/' "$file" done
-
Script to trim Docker logs to 1 Megabyte.
#!/bin/bash size=1M function trimLog { file=$1 temp="$file.$(date +%s%N).tmp" time=$(date --rfc-3339='seconds') before=$(du -sh "$file" | cut -f1) echo -n "$time: $file: $before=>" tail --bytes=$size "$file" > "$temp" chown $(stat -c '%U' "$file"):$(stat -c '%G' "$file") "$temp" chmod $(stat -c "%a" "$file") "$temp" mv "$temp" "$file" after=$(du -sh "$file" | cut -f1) echo "$after" } find "/var/lib/docker/containers" -name "*.log" -size +$size 2>/dev/null | sort -f |\ while read file; do trimLog "$file"; done
-
I use this script daily to backup my flash drive to a zip file and it deletes the backups that are over 30 days old.
#!/bin/bash source /root/.bash_profile backup="/mnt/user/Backup/Flash" mkdir -p "$backup" date=$(date +"%Y-%m-%d-%H-%M-%S-%Z") filename="flash.$date.zip" echo Compressing flash backup \"$filename\" cd /boot zip -r "$backup/$filename" .* * chown -R nobody:users "$backup" chmod -R ug+rw,ug+X,o-rwx "$backup" echo Removing backups over 30 days old find "$backup" -mtime +30 -type f -delete -print
Edit:
Added quotes around everything incase people wanted to add spaces in the backup directory name and/or the backup file name.
-
1 hour ago, JorgeB said:
Is that with Mac or PC?
PC running Windows 10 Pro 22H2
Here is an example of a 7.02 GB transfer of 3 files:
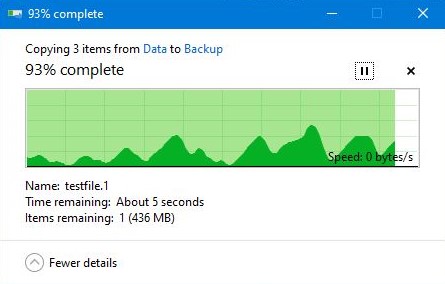
-
8 minutes ago, JorgeB said:
Performance has been similar for all v6.11.x releases, they all use Samba 4.7.x
I have also noticed that throughout the v6.11.x releases that Samba has gotten slower. Before I used to get a steady 100 MB/s. Now I get a roller coaster between 70 MB/s and 20 MB/s. Also, when I transfer over 5 GB in files, it will stall multiple times to 0 MB/s.


[Plugin] CA User Scripts
in Plugin Support
Posted · Edited by JoeUnraidUser
Try adding the "-l" option to bash and source the ".bash_profile".
Example:
Output:
test.log