

nas_nerd
-
Posts
34 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by nas_nerd
-
-
41 minutes ago, muwahhid said:
This is just a disaster.
I've been using Unraid for almost a month now. I put btrfs raid1 in the cache without encryption. Two brand new samsung ssd 860 2tb. Just yesterday I paid for the Unraid pro license for $ 89.
Today I accidentally learned from a person that a forum is discussing this problem. I decided to check my SSD. And now I ask you, are you kidding me guys? My two new SSDs already have 90tbw, and 28 percent of my life. THAT is 1 percent life ssd for every day?And this problem has been known to you since the month of November, six months have passed and you still haven’t fixed it?
I'm just in shock. All impression spoiled about Unraid and Limetech.
How are you calculating 90TBW?
-
1 hour ago, nuhll said:
how to check if this is a problem for me?
one shows 934731420222 LBAS (2y6m)
the other 899487348326 LBAS (2y4m)if im right its about 500gb a day, which seems much (?!)
sadly iotop is not working for me (was already installed)
root@Unraid-Server:~# iotop
libffi.so.7: cannot open shared object file: No such file or directory
To run an uninstalled copy of iotop,
launch iotop.py in the top directoryroot@Unraid-Server:~# iotop -ao
libffi.so.7: cannot open shared object file: No such file or directory
To run an uninstalled copy of iotop,
launch iotop.py in the top directory
root@Unraid-Server:~# iotop.py
-bash: iotop.py: command not found
root@Unraid-Server:~# py iotop.py
-bash: py: command not found
root@Unraid-Server:~# python iotop.py
python: can't open file 'iotop.py': [Errno 2] No such file or directory/dev/sdd Power_On_Hours 22510 hours / 937 days / 2.57 years
/dev/sdd Wear_Leveling_Count 44 (% health)
/dev/sdd Total_LBAs_Written 445842.14 gb / 435.39 tb
/dev/sdd mean writes per hour: 19.806 gb / 0.019 tb/dev/sdc Power_On_Hours 20447 hours / 851 days / 2.33 years
/dev/sdc Wear_Leveling_Count 46 (% health)
/dev/sdc Total_LBAs_Written 428919.80 gb / 418.87 tb
/dev/sdc mean writes per hour: 20.977 gb / 0.020 tbis that normal?
Idle windows 10 VM + the usual linux iso download dockers and some light plex...
I also wonder why limetech isnt posting anymore here, i mean its 6 months after he read it, was it addressed in some RC?
Make sure you have libffi installed and updated to get iotop to work.
I'm sure limetech are aware of this issue, they are no doubt busy on 6.9 at the moment, hopefully after it is released they can turn their focus to this issue.
-
Bad news on my end, my writes have crept back up again, and arguably just as bad as it was before I switched my cache to XFS.
This suggests it is a docker issue again.
I need to do more testing but at this stage I am suspecting the Nextcloud/MariaDB dockers are causing the excessive writes.
I would be interested if other people are using these dockers and can test by stopping them and tracking writes?
I need to back-track from blaming BTRFS now too, at least in my case, the file system does not appear to be a factor in excessive writes.
-
Update from my end:
Converted my 500GB SSD BTRFS cache pool to a single XFS 500GB cache.
Writes to the cache have now dropped significantly. I am running the exact same dockers as previously.
This suggests a BTRFS + Docker combination is contributing to this excessive write problem.
Unfortunately now my cache is unprotected and I have a spare 500gb SSD (I'm sure I'll find a use for this :))
I agree with a few comments about this issue/bug being more significant than "minor".
-
Another update.
I stopped all my docker containers overnight (but docker was still enabled), and I barely had any writes to the cache.
This to me suggests potentially a rogue docker application, or having dockers running is causing an issue.
More testing is required on my behalf.
-
I suspect I am also experiencing this issue.

The iotop screenshot is from a 2 hour period where the server was idling for most of the time.
~11GB from loop2 in 2 hours....
2 Samsung 500gb Evo SSD in BTRFS pool, no encryption.
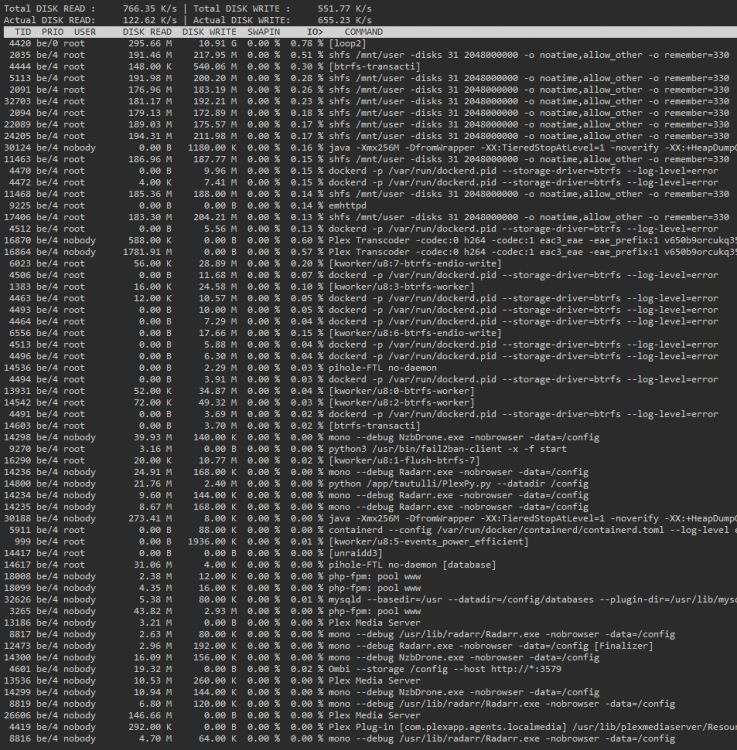
****update****
8 hours later it looks like almost 900gb in writes? I hope I am interpreting this incorrectly?
I need to fix this ASAP otherwise these SSDs will be cooked by the end of the month.

-
5 hours ago, Mex said:
So we have quite a bit of plugins in common.
I have had no issues since I removed mine. It was up for several days and then i upgraded to 6.6.6. And it has been up for 2 days now. The only logical conclusion is that one (or more) of the plugins had some issue. Maybe limited to certain types of hardware.
Ok I have uninstalled preclear, nerd pack, unassigned devices and a couple of dynamix plugins I wasn't using anyway. No issues for >24hours on 6.6.6
It would be great if someone from @limetech could have a look at the errors we both posted as it means little to me.
As I said before, everything was rock solid on 6.5.3
-
preclear, unassigned devices, nerd tools, system temp, s3 sleep, active streams, sad trim, clean up app data, controller, system statistics, ipmi support, speed test, tips and tweaks, unbalance, user scripts, CA applications and fix common problems.
-
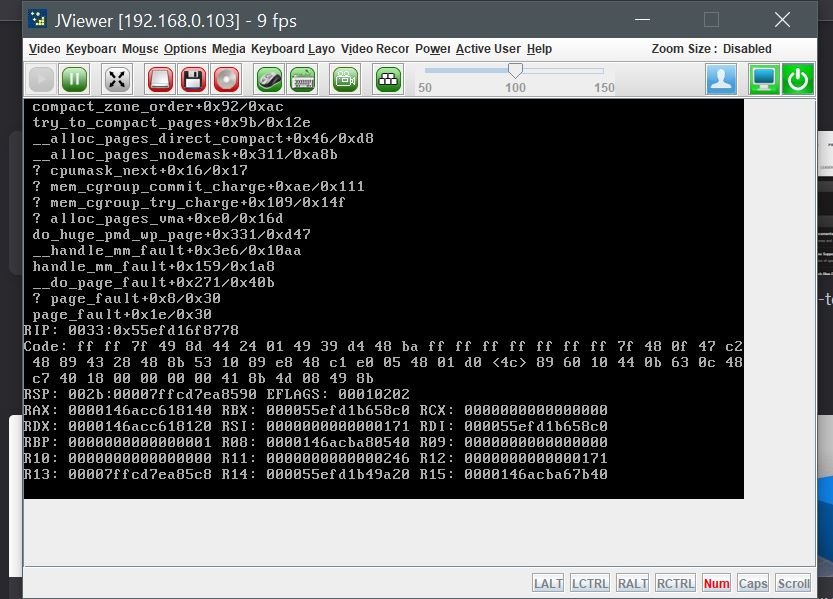
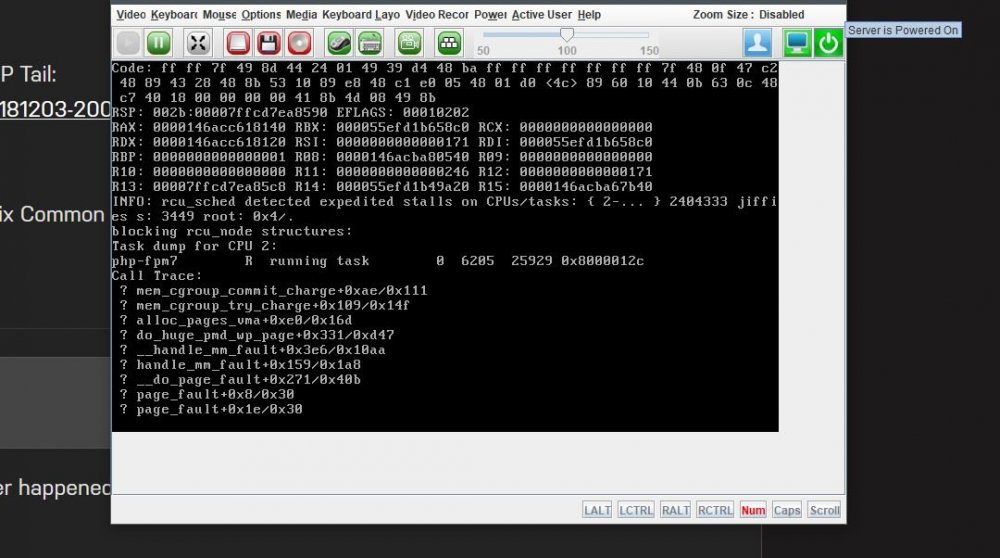
I finally upgraded from 6.5.3 to 6.6.5 around 20 to 30hrs ago.
Tonight I started playing a show on Plex and 1-2 mins into the episode the stream stops.
I try to check the unraid webui and it is unresponsive.
Eventually I login to the IPMI, and took these screenshots before I rebooted through the interface.
My specs:
Asrock rack E3C236D2I
Intel i3 6100
latest bios (2.60)
Never experienced this before on previous builds, it has been rock solid for over 18 months.






[6.8.3] docker image huge amount of unnecessary writes on cache
in Stable Releases
Posted
Thanks, my SSD smart attributes doesn't show the data written like some users above have posted screen caps of.