




cyberstyx
Members
-
Joined
-
Last visited
-
Hello @JorgeB, If I can add something to this, I didn't find any relevant information with the search I did to avoid double posting. As I installed this card to IT mode a few days ago, from my searching I found this among other info: Flashing firmware and BIOS on LSI SAS HBAs. sas2flash and sas3flash executables are used to upgrade the firmware to a newer version. sas2flsh and sas3flsh executables are used to downgrade firmware and change modes between IR and IT. I could only find the sas3flsh file needed for 9308 as a DOS .exe file. All other files are available for DOS / Linux / UEFI shell. I did find a ZIP file at Broadcom stating that it had the sas3flsh file for Linux, but when I opened it it had a sas3flash file in it and I didn't try it on unraid to see if they mixed up the filename. TIP: If anyone tries to make a bootable USB in DOS, you may want to prepare it as an MS-DOS bootable and not as a FreeDOS one; The FreeDOS one kept cutting the VGA signal to my monitor after 30" to 1' and putting it on power-saving without any means to get picture back expect from hard resetting, where as the MS-DOS one didn't. The timing of flashing a card and getting a black screen 3" after you run a command can be confusing.
-
Coming back to this issue, I ordered a "10Gtek LSI-3008-8I HBA Card" from Amazon for 94€ plus 2x "Internal HD Mini SAS (SFF-8643 Host) to 4 x SATA (Target) Hard Drive Cable" for 14€ each, which arrived last week. I flashed the card to IT mode on Saturday and took the expected ~15hours to rebuild a 6TB 5200rpm disk, it finished rebuilding yesterday night. The problem is now resolved, the array is up and running again. Looks like the MARVEL based cards are not suitable for unraid 6x and onwards I guess. Thanks again for your help @itimpi, @JorgeB and @trurl. PS: Flashing a card from IR mode (raid functionality) to IT mode (JBOD functionality) is mostly a pain as there is generic information around that may not suite the specific HBA card you may have and you may need to adapt. There 's quite some investigation you will have to do from generic guides and the manufacturer's info, and then you will have to self-improvise. Broadcom's info on this (who bought Avago who bought LSI) is for the lols, with very good generic info, guides and tools that don't work anymore (building a USB bootable with their suite of tools on it) and scattered to no existing links to the actual individual files you need.
-
I will then look for a suitable replacement card before retrying with the already given walkthrough. I will close this post, thank you for your help @itimpi, @JorgeB, @trurl
-
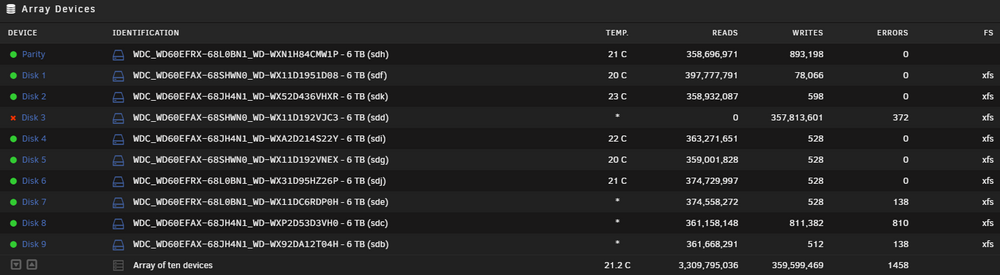
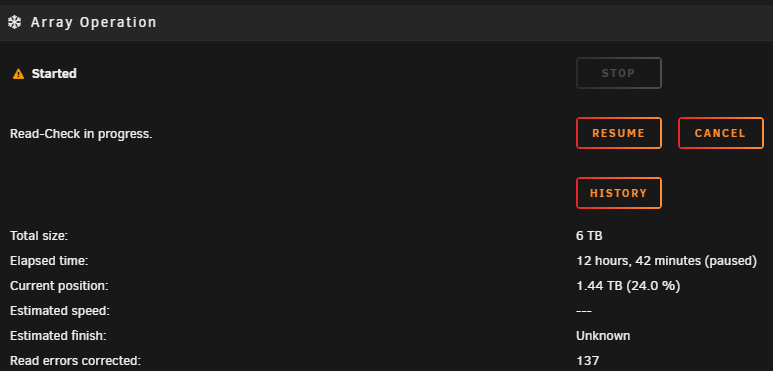
I checked its status today, the operation paused after 12 hours and at 24%, Disk 3 went to Disabled status. I will need to cancel the paused operation and try something new. I am attaching the latest info. I found out this thread Recommended controllers for Unraid suggesting to a void the MARVEL chipset and giving other viable options. Do you think the Digitus cards (chipset MARVELL 88SE9230) are giving all the issues? The two SATA expansion cards were bought in 2016 and worked fine, but then it was an older version of unraid too. tower-diagnostics-20250320-1026.zip
-
I replaced one cable that was old, the others had new cables (installed ~3 years ago). The PSU was also replaced ~3 years ago. Disks 3, 7 and 9 where on the same PCI SATA controller, I moved them all on the second PCI SATA controller that had Disk 8 connected on it and started over the rebuild. The controllers are 2x Digitus PCI SATA with 4 SATA connectors each, which I have them installed for many years now. There are no more free SATA connectors available except the non-used controller that had 3, 7 & 9 on it.
-
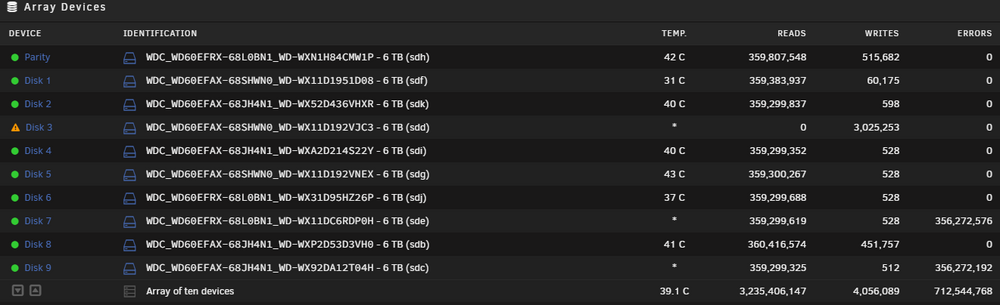
Yes, Disk 5 was an older issue (3 years ago?) that was tackled. I returned home, checked the progress, it looks like there are other issues now. Disk 3 stopped writing, Disks 7 & 9 (which also reported issues when I was trying to mount Disk 3 with the problematic FS but were ok after each array restart), are now showing errors while participating in the rebuild. Should I stop the rebuild and check Disks 7 & 9 FS status too? tower-diagnostics-20250319-2108.zip
-
The array started with Disk 3 enabled and is currently rebuilding. I will let you know as soon as it finishes (it will take many hours).
-
Hello @itimpi, I did a "Check Filesystem Status" without the "-n", got the following as a result: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 7 - agno = 3 - agno = 5 - agno = 2 - agno = 6 - agno = 4 - agno = 8 - agno = 9 - agno = 10 - agno = 11 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done After the results I started the array in Normal mode, Disk 3 is still disabled (with an "X"). Docker has some issues from a few years ago when I had this and some Windows VMs running on an SSD that I eventually replaced with an HDD. I will need to properly set it up again at a later day. tower-diagnostics-20250319-1208.zip
-
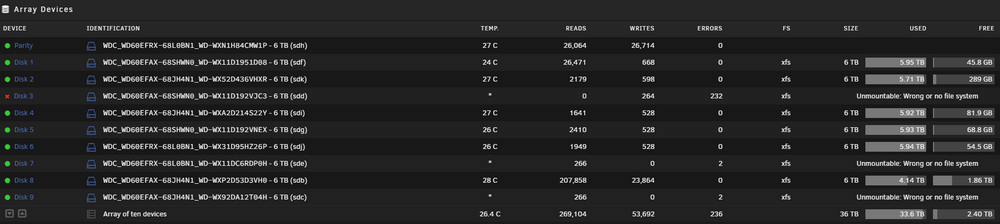
Hello all, I booted up by unraid server last week to find Disk 3 disabled. Upon stopping the array, removing the disk, rebooting the server, mounting again the missing disk and rebooting, the sever reports Disk 3 as "Unmountable: Wrong or missing file system", but now Disk 7 and 9, although mounted and running show the same info. After rebooting the server again, Disk 3 is again disabled and Disk 7 & 9 are again mounted and running without the previous error. At the time I can't re-mount Disk 3 and try to rebuild it. I 've uploaded the diagnostics when the server starts, as well as the diagnostics after trying to re-mount Disk 3 and getting some FS errors for Disks 7 & 9 too. Any help would be much appreciated. tower-diagnostics-20250319-0923.zip tower-diagnostics-20250319-0942.zip

-
The rebuild finished successfully with 0 errors. I also did a sample check on file structure, all files are there and all are working as should. I have also attached the diagnostics file if you think you want to have a look. I will start tackling the libvirt.img corruption issue probably tomorrow, I have some unraid OS backups if needed and the config of the VMs has not changed in a long time. I will also check the suggestion about the proper usage of SSD in unraid as suggested. Thank you all again for your help, especially JorgeB. Having 4+ hardware fails one after the other (one PSU and various SATA cables) and many errors due to that was something tackled only by experts. Christos. tower-diagnostics-20231002-1857.zip
-
Hello JorgeB, Replaced SATA cable, did a filesystem check -n on the disk and restarted the rebuild.
-
I stopped the operation, after 195,362,860 writes, Disk9 was giving Errors. I have attached the diagnostics file. While rebuilt was running, shared folders where not working properly. The configuration for them was there (in Shares tab), I could see the shared folders over the network but they were empty. When I checked a share folder from the console I got "/bin/ls: reading directory '.': Input/output error". Disk contents from /mnt disks were there. When I stopped rebuilding, the share folder contents where visible again. I started the Array in Maintenance Mode so I could do a file system check on Disk 9 (with flag -n). I got this: Phase 1 - find and verify superblock... superblock read failed, offset 0, size 524288, ag 0, rval -1 fatal error -- Input/output error I 've stopped for further instructions now. tower-diagnostics-20231001-0005.zip
-
After a week's delay from the shop to send me the bought PSU, I got the replacement a few days ago and had time today to remove the server PC from its installed location and swap the PSU. I followed the suggested steps again to make a new config and start the array and then replace the disk, the array is now being rebuilt. Hopefully it will finish tomorrow morning without any new surprises, and I will share my news then.
-
Thank you for that info. I will read more about this and ask you again when I restore the system
-
Since Disk1 was on MB controller and Disk5 was on PCI controller, it is probably a PSU issue. Will come back to this as soon as I get a new PSU and replace all power cabling. Thanks for you help JorgeB, have a nice Sunday.





