

thither
-
Posts
51 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by thither
-
-
Hi. Unraid 6.12 has been nothing but frustration for me, and after enduring several weeks of needing to power-cycle it once a day I've downgraded my server back down to 6.11.5.
Some of the stuff I use unraid for is still working fine, notably the SMB shares and my Plex and Calibre docker images, but the majority of my docker images won't start; trying to run them from the docker panel gives me an error message "Execution error - Server error". (These were all working fine in 6.12.)
I get this block of logs in the unRaid logs when this happens:
Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered blocking state Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered disabled state Jan 24 10:48:33 Eurydice kernel: device vethc95c9cf entered promiscuous mode Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered blocking state Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered forwarding state Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered disabled state Jan 24 10:48:33 Eurydice kernel: cgroup: Unknown subsys name 'elogind' Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered disabled state Jan 24 10:48:33 Eurydice kernel: device vethc95c9cf left promiscuous mode Jan 24 10:48:33 Eurydice kernel: docker0: port 3(vethc95c9cf) entered disabled state
I'm not really sure what do here, the elogind error doesn't kick up anything for me in a web search. Should I uninstall and reinstall these images?
Fix Common Problems also gives me a warning about a docker patch that I need to download, but I can't download it, because Fix Common Problems sends me to the Community Apps page, which tells me I need to download 6.12 before I use it. Is there anywhere I can manually download and apply this patch?
-
On 12/23/2023 at 4:18 PM, Manni01 said:
One downside to the downgrade to 6.11.5, common problems reports an issue with an update needed for the docker patch, but when I click on the update button it sends me to the app tab and I'm told that I can't install the community apps plugin as it needs 6.12.0 minimum
Sorry to piggyback on the thread, but is there any solution for re-downloading the 6.11 version of community applications? I've also downgraded from 6.12 back to 6.11 (to fix some server crashes that started during 6.12) and I'm seeing the same thing.
-
It seems that the nzbget developers have gotten tired of working on it and archived all the github repos, so I'm guessing fixes for the VideoSort thing aren't likely from upstream (mine seems to have broken again, personally). Guess it's time to look into SABnzbd again...
-
I can confirm that 6.5.0 is broken for me with the same error, and rolling back to 6.4.0 fixed it. Don't see anything obvious about this on the linuxserver.io github page.
-
 1
1
-
-
I've noticed similar behavior where my unRaid (6.10.3) box will periodically seem to drop all inbound network traffic. This happens once every few weeks. Plugging in a monitor to it, I see the console still prompting me for a login, no kernel panic message or similar. (I wasn't able to hook up a keyboard to log in at the console, long story, and have wound up just cutting the power, though now I have a new keyboard ready for next time.)
Weirdly, although inbound connections fail (HTTP to the web console / docker ports, SMB connections to shares, ICMP ECHO pings), from looking at my NZBGet history, it appears as though outbound traffic is still working - I see downloads that completed successfully during the time that I could not ping the box.
I have just enabled syslog and will report back here with logs if I see the problem reoccurring.
Edit to add that this is on a regular old Intel PC, I'm not running QNAP hardware.
-
Just wanted to say thanks for the instructions, this has been working great for me!
-
Ok, well after a good deal of messing around I created a new config and am rebuilding parity now. I definitely lost a bunch of data, and without disk3 being readable it's a little hard to say what exactly went away, but the system is stable again and I definitely learned something through this whole process.
Thanks very much for helping me out with this @JorgeB!
-
18 hours ago, JorgeB said:
Parity status is unclear, you didn't even mentioned for how long has disk 3 been disabled, and if you know if there were any writes to it after, like mentioned above you could try to force enable disk3 to rebuild disk2 to a new disk, I can still post instructions for that if you want, but it will only work if parity is still valid.
Sorry about that. I first got a notification that disk3 was out on 2022-01-15, and I definitely didn't intentionally write anything to the disk after that. Most of the data going into the array since that time would be automatic downloads (from Sonarr etc) which are not super important and could be redownloaded if needed.
After running for quite a while, ddrescue from disk2 to my new replacement for it succeeded, rescuing 99.99% of the data, and after running a xfs_repair on the replacement it mounts fine, with just a few random files (6GB or so) winding up in lost+found.
Do you think it would be worthwhile to try to add in this replacement disk back into the array as disk2, and then once it's in there to try to rebuild my replacement for disk3 from parity, or would I just be risking 6GB or more of corrupt data on the replacement (since that would be changed on disk2 since parity was computed)? Or should I just start over with a new config and live without whatever was on disk3?
-
6 hours ago, JorgeB said:
Not a good idea since you have a known bad disk in the array, disk2.
Ah, right. Well I just wanted to see whether I could get any data off of it at all, but it seemed to be totally unresponsive.
I've got ddrescue running right now on disk2 (current remaining time: 222d 15h, though I'm hopeful that will improve).
Am I correct in saying that at this point my existing parity drive isn't useful any more, since it's been trying to check two faulty drives at once and whatever parity information is on it is unreliable now? So my best course of action is just to recover as much stuff as I can from disk2 and then recompute parity from scratch with whatever recovered data I can get off of it?
-
As a brief update, I removed disk3 (the disabled one) from the array and tried to add it back in to rebuild, but it started throwing SMART errors, and then finally wouldn't mount at all. xfs_repair told me to run it again with -L, which I may try to do, but in theory everything in there should be rebuildable from parity, so I'll likely just get rid of the disk. I'll be trying a ddrescue from disk2 to the new disk as soon as the new disk's extended SMART test is complete.
-
Thanks for the link to ddrescue. So If I'm understanding correctly, my next steps would be:
- install a new disk as disk5
- try to ddrescue as much stuff as I can from disk2 to disk5
- remove disk2 from the array, add disk5
- Rebuild parity based on the recovered data, probably with some data loss
Is there any chance of un-disabling disk3? Should I just uninstall the disk and trash it?
-
Ok, so The disk2 and disk3 reports completed.
disk3, the disabled one, shows the test completing without error in that same section of the report:
SMART Extended Self-test Log Version: 1 (1 sectors) Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 21383 - # 2 Short offline Completed without error 00% 21365 - # 3 Short offline Completed without error 00% 21328 -disk2, which is doomed, shows 4218 errors (and unraid shows the test as "completed: read failure").
SMART Extended Self-test Log Version: 1 (1 sectors) Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 90% 46611 43138432 # 2 Extended offline Completed: read failure 90% 46566 3145072 # 3 Short offline Completed without error 00% 46557 -So it looks like only disk2 fails the SMART tests, and if I'm lucky I'll be able to swap it out and rebuild from parity.
One thing I still don't understand is how I can get disk3 back into the array. Just starting the array doesn't seem to do it. Do I need to erase the disk or something? Remove it from the array and re-add it? Will a cold reboot do it? (I've rebooted, but haven't turned the power all the way off.)
Relatedly, I would think it would be best to get disk3 back online before I swap out disk2 for a fresh drive, but is that the wrong order to do it in? I would think that as long as disk2 is unreliable, the system as a whole wouldn't be able to reliably compute the parity.
disk3-eurydice-smart-20220225-0900.zip disk2-eurydice-smart-20220225-0038.zip
-
21 hours ago, JorgeB said:
There appear to be 3 failing disks with single parity, so some some data loss is expected, disk2 is failing for sure, disk1 might also be, run an extended SMART test on disks 1 and 3 and post new diags once they are done.
Thanks for taking a look. I've got SMART tests running on disk2 and disk3 and will post them once they're done. The disk1 test finished and reported a passing test, as far as I can make out from the logs ("SMART overall-health self-assessment test result: PASSED"), but I'm not super familiar with what I should be looking for in there.
-
Oh, one other thing: this was probably a mistake, but I ran a parity check after I noticed things were failing. I got a lot of errors:

Does this mean I'm screwed for data recovery? Like, if the parity disk couldn't read a bit from the failing disk, it wouldn't be able to compute the parity for that bit across all four disks, would it?
-
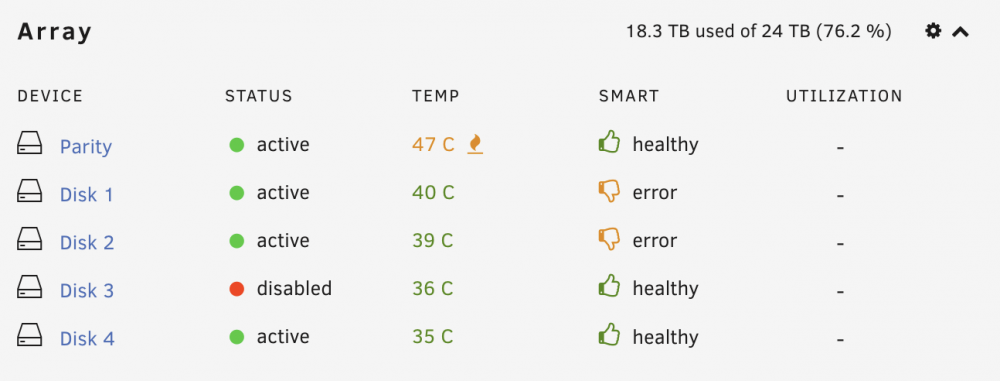
Hello! I seem to be in a bit of a pickle. Two of the data disks in my 4-disk array are reporting SMART errors. One seems to pass xfs_repair with no problems, while with the other one xfs_repair fails on an i/o error.
xfs_repair on disk #2 give me this:
Phase 1 - find and verify superblock... - block cache size set to 1478872 entries Phase 2 - using internal log - zero log... zero_log: head block 1285582 tail block 1285582 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 xfs_repair: read failed: Input/output error can't read block 0 for directory inode 2096964 no . entry for directory 2096964 no .. entry for directory 2096964 problem with directory contents in inode 2096964 cleared inode 2096964 xfs_repair: read failed: Input/output error cannot read inode 3144960, disk block 3144992, cnt 32(That's xfs_repair -v, I get errors just running -n though.)
Meanwhile, a third disk is marked "disabled" although it reports no SMART errors, and will not seem to come back into the array even after stopping and restarting the array. I've run xfs_repair on it and it doesn't seem to have any errors.
My shares are acting a bit strange, with two of them refusing to respond to an `ls` command:
root@Eurydice:/mnt/user/Video/Television# ls /bin/ls: reading directory '.': Input/output error
From looking at the xfs_repair output and smart tests, it seems clear that disk2 is a goner and will need to be replaced. I've actually got two new disks that I can swap in right now, but I'd like some advice before I do it.
Right now my shares are all marked as "unprotected" which makes me worry that I'll lose data if I just clear a disk.
So my questions are:
- What should I do about disk #2, which has the i/o failures shown above?
- Disk #1 shows a little SMART thumbs-down icon in the dashboard, but the last time I ran self-tests it was fine. Does hitting "acknowledge" clear the thumb-down icon? Should I consider this disk compromised as well?
- What can I do to get disk #3, which shows status "disabled", back into the array?
- What can I do do try to minimize data loss before I pull disk #2 (and maybe the others) out of the array?
I'll include a diagnostics zip file (if I can manage to upload it, I was having trouble in Firefox).
Thanks!
-
There seem to be a lot of problems with the front-end for this image:
- The "search" button on the ebooks/audiobooks page doesn't do anything, just refreshes the page
- The search box on the "series" page returns a 404 because the URL parameter is called "searchbox" (manually changing the URL to use "name" seems to work)
- Changing of the "status" dropdowns on the manage page seems to just refresh the page and only ever show things in the "wanted" state
Anyone else seeing this? I don't see any js errors in my console and the behavior is the same between Firefox and Chrome.
-
This is maybe a dumb question, I just can't remember. Is the source code for videosort/VideoSort.py included in this docker image, or is it something that is downloaded and installed separately from the docker image itself? (I installed nzbget a long time ago and several versions of Unraid back, so I honestly can't remember.)
If it's in the image it should be patchable (by running it through the 2to3 script as @Merson suggested, at a minimum). If not, does anyone have a link to wherever the official source is, or else an alternative script written in Python 3?
The reason for my question is that I'm also getting the same "VideoSort: SyntaxError: invalid syntax" failure messages. I tried adding the ".py=whatever" line and that didn't fix it, which makes sense now that I'm thinking about it since there isn't a python2 binary anywhere in the image that could execute the videosort file. From the error message, I'm guessing all that needs to be done is changing the "<>" operators to "!=" (as "<>" was deprecated in python3, and presumably removed in whatever point release the base image was updated to recently).
-
Hi all, I have a question. I've got a machine that I put together back in 2016 which used this now-discontinued 660W PSU, the Seasonic SS-660XP2. The PSU recently failed, and I'm wondering if I might have been running too much hardware on it.
When I first set this up, it was running 4 WD Reds (6GB) plus a NVidia GeForce GTX 970 (not used often, just for gaming in a VM). Everything worked fine. Then a while back my motherboard failed and I wound up uninstalling the GPU. Recently after a disk failure I decided to add in a 5th HDD and pop the GPU back in. I started it up and everything seemed to be working fine, but then after several days of happiness it just shut down, and refused to POST, and after a bit of troubleshooting I realized the PSU had failed.
I've RMAed the power supply, but I'm wondering if I might have been hovering just on the edge of how much power I needed, and if adding in the 5th HDD might have pushed it over the edge and caused the PSU to fail. So I thought I'd get some advice. Does 660W sound like a big enough power supply for that amount of hardware? Should I upgrade to a beefier model now and save whatever replacement Seasonic sends me for a different machine?
-
On 4/2/2017 at 7:27 PM, caseyparsons said:
Loaded and it boots, but now it takes around 30 minutes to load bzimage and bzroot. Was running fine before upgrade.
I'm seeing something (maybe) similar, but I gave up on it after about 5 minutes assuming it was frozen. However, I can boot into GUI mode and everything works fine, boot takes maybe a minute or so.
I had similar problems with 6.3.2: the GUI mode booted up with no problems but everything would hang when I tried to boot into headless mode. For 6.3.2 I was able to fix this problem via a firmware upgrade of my ASRock motherboard. For 6.3.3 I'm again unable to boot headless - the terminal prints "Loading bzImage... ok" and then it seems to freeze up, no response from the NIC or the keyboard (even ctrl-alt-delete).
[EDIT, 6 months later: I upgraded to unRaid 6.5.2 and this problem went away!]
-
On 3/9/2017 at 9:11 AM, thither said:
Just to confirm, I also see these same checksums on my Asus Z170 board, and my syslinux.cfg is the same as the one @JonUKRed posted above (and I'm also not able to boot into non-GUI mode). Don't have time for a BIOS upgrade now but I'll try it sometime in the next few days and report back.
Ok, so I updated my firmware BIOS to version 7.30 and was able to boot up normally in non-GUI mode again. Not sure what the deal is, but everything seems to be kosher now. Thanks for the advice! (Also I have an ASRock board, not an Asus one, just for the record.)
-
17 hours ago, limetech said:
I guess for completeness can check 'em all:
5a4d270d192c0573bb78af92220e149b bzimage c1a14a522656426fb9e20b66a5968d1a bzroot f65c0917efe04edf5b91528c3c7eb1d1 bzroot-guiJust to confirm, I also see these same checksums on my Asus Z170 board, and my syslinux.cfg is the same as the one @JonUKRed posted above (and I'm also not able to boot into non-GUI mode). Don't have time for a BIOS upgrade now but I'll try it sometime in the next few days and report back.
-
44 minutes ago, itimpi said:
Quite a few people have reported that! In most cases it seems to occur for SuperMicro motherboards - what do you have?
I've got an ASRock Z170 Extreme+ - this one.
-
After upgrading from 6.3.1 I'm seeing some odd behavior where I can boot into GUI mode, but when I try to boot into regular (OS) mode the server freezes after it loads /bzImage and is not pingable. I run headless most of the time with my monitor plugged into a different GUI card for VMs, so this isn't ideal. Anything I can try to diagnose this?
-
I had the exact same issue upgrading from rc3 to rc4. I didn't change anything explicitly, bt when I went to my WM settings, I found that there were two sound cards being passed through - the onboard one and the GPU one. I disabled the onboard one (set "first sound card" to the GPU sound card and the second to "none") and then I was able to boot my VM as before, and sound (through HDMI) works fine again.



Most docker apps not starting after downgrade from 6.12 to 6.11, "Unknown subsys name 'elogind'"
in General Support
Posted
Answering my own question about the docker images, what I did was to use "Add Container" from the docker page for every image I wanted to add, then under "templates" I selected the template from the "users" section, created new containers with names in the form "sonarr-6-11", and set them to autostart instead of the old ones. The "add container" form had all the right data prepopulated correctly and so far everything has worked without a hitch.