

Paul_Ber
-
Posts
371 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Paul_Ber
-
unRAID OS version 6.3.1 Stable Release Available
Paul_Ber replied to limetech's topic in Announcements
6.2.4 is still on the Lime Tech download page, just extract what you need. I know I kept having issues going from 6.1.9 to 6.2 and 6.1.9 to 6.3.1 and then going back. I found today my disk3 had errors. Went into maintenance mode and ran the repair from console, got back working after. Just waiting for parity sync to finish. Sent from my Pixel XL using Tapatalk -
Hex, Is there anything special to do for permissions for /config/openvpn folder? I basically follow what you do. I got my container caught up with you. I got it working with quite a few stops and starts. I noticed when I tried copying the .ovpn file with a file manager it looks like it copies but doesn't really end up in there. I had to finally do it in a terminal cp. Sent from my Pixel XL using Tapatalk
-
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
Ok I am back up and running on 6.3.1, thanks for everyones help, sorry to be such a noob Well i decided to put in the new Parity Drive I bought of 6TB. After all back up and running, will swap out the Disk 3 3TB drive for the old parity 5TB. I had used a totally new 6.3.1 with just the Plus copied to config, some how one of my VMs just started to work on its own. So after the new 6TB Parity HD is sync'd, what is the process to swap out the Disk 3 3TB drive for the 5TB drive? Just have to add my Dockers again. I was freaking out for the last 24hrs. -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
root@Tower:~# xfs_repair -v /dev/md3 Phase 1 - find and verify superblock... - block cache size set to 3028856 entries Phase 2 - using internal log - zero log... zero_log: head block 369445 tail block 369417 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. root@Tower:~# xfs_repair -vL /dev/md3 Phase 1 - find and verify superblock... - block cache size set to 3028856 entries Phase 2 - using internal log - zero log... zero_log: head block 369445 tail block 369417 ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... Metadata corruption detected at xfs_agf block 0x1/0x200 flfirst 118 in agf 0 too large (max = 118) sb_fdblocks 201379159, counted 201386137 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 3 - agno = 1 - agno = 2 - agno = 0 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (4:369441) is ahead of log (1:2). Format log to cycle 7. XFS_REPAIR Summary Sun Feb 12 13:33:19 2017 Phase Start End Duration Phase 1: 02/12 13:26:51 02/12 13:26:51 Phase 2: 02/12 13:26:51 02/12 13:28:00 1 minute, 9 seconds Phase 3: 02/12 13:28:00 02/12 13:30:39 2 minutes, 39 seconds Phase 4: 02/12 13:30:39 02/12 13:30:39 Phase 5: 02/12 13:30:39 02/12 13:30:39 Phase 6: 02/12 13:30:39 02/12 13:30:41 2 seconds Phase 7: 02/12 13:30:41 02/12 13:30:41 Total run time: 3 minutes, 50 seconds done So the Disk 3 is one I do not trust 100%. I know I screwed up my Parity. (I tried the xfs_repair thing on sdd, and then tried formatting, yes my super bad) So if I can get the array up, I already bought a new WD RED 6TB drive, and if the data seems fine(don't really have a choice now), can i shut down properly, swap out the 6TB for the 5TB, Turn back on run Parity on new 6TB drive? 10-12 hours later take out disk 3 which is 3TB and replace it with the 5TB one? -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
md3 is always disk3 but you need to start the array in maintenance mode before running xfs_repair, so after starting in maintenance mode run: xfs_repair -nv /dev/md3 root@Tower:~# xfs_repair -nv /dev/md3 Phase 1 - find and verify superblock... - block cache size set to 3028856 entries Phase 2 - using internal log - zero log... zero_log: head block 369445 tail block 369417 - scan filesystem freespace and inode maps... Metadata corruption detected at xfs_agf block 0x1/0x200 flfirst 118 in agf 0 too large (max = 118) agf 118 freelist blocks bad, skipping freelist scan sb_fdblocks 201379159, counted 201386130 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Sun Feb 12 13:20:40 2017 Phase Start End Duration Phase 1: 02/12 13:17:56 02/12 13:17:56 Phase 2: 02/12 13:17:56 02/12 13:18:00 4 seconds Phase 3: 02/12 13:18:00 02/12 13:20:38 2 minutes, 38 seconds Phase 4: 02/12 13:20:38 02/12 13:20:39 1 second Phase 5: Skipped Phase 6: 02/12 13:20:39 02/12 13:20:40 1 second Phase 7: 02/12 13:20:40 02/12 13:20:40 Total run time: 2 minutes, 44 seconds Do I run it again without the n? -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
Here is the syslog I am going to try and swap out the new Parity drive I bought. My drives that have green icons are: 2 Cache, 3 data The parity drive is a orange triangle. The USB stick is running brand new 6.3.1 with key copied to config. Not sure to try only 6.1.9 on the replacement parity drive? I know that works for sure. Maybe I should try 6.1.9 without changing the parity drive? syslog.txt -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
How do I get diags from console? How would I save that? I took a picture of what showed on the console screen right after starting array.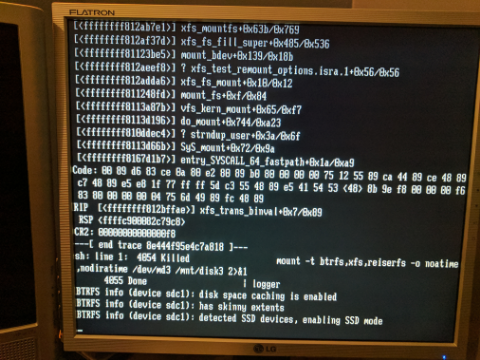
-
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
Well the SATA 3 port is connected to my 5TB Parity drive. I disconnect that sata port and I can boot into web gui of UNRAID. With that drive plugged in, I cannot get the the web gui. I am going out today to buy a new Parity drive. And swap them out. -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
I cannot get the web gui with the partiy drive connected, it happens to be sata 3. There is something about the parity drive that locks up the system. -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
OK md3 turns out to be /dev/sdd which happens to be my parity drive. So I am trying xfs_repair -v /dev/sdd It said something about bad super lock at the very beginning then tons of "." going by. Can a bad parity drive cause the system to lock up? Could of that been my troubles all along? -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
OK now I am deep in the water. Restored the USB stick by copying the contents of the /previous folder to the root of the USB. Well I am worse off now. XDS (md3): Metadata corruption detected at xfs_agf_read_verify+0xb/0xc1, block 0x1 Fffff etc. XAGF.......Etc 3 more lines of above XDS (md3): Metadata I/o error block ("xfs_trans_read_buf_map") error 117 numblks 1 So I tried xfs_repair -nv /dev/md3 It goes to a new line and no more info, HD LED not lighting up. What now? -
Paul_Ber-Problems after upgrade to 6.3.1 Stable
Paul_Ber replied to Paul_Ber's topic in General Support
Ok after the upgrade it was locking up. So I powered off and backed up the UNRAID USB stick, Formatted it and put 6.3.1 on it. Made it bootable. It is booted into the GUI. I was able to reassign my one Party Drive, 3 Data drives, 2 Cache drives. I hit start. It says mounting disk, Parity and 3 Data drives are blue on the GUI. Cache and USB is green, The UNRAID at tower is unresponsive. HD LED is not going on. I can still use the Firefox in a different tab to write this reply. I am running AMD FX-6300. Is this an AMD thing again? I had nothing but troubles a few months ago in Sept 2016 from 6.1.9 to 6.2, withing a day I went back to 6.1.9. Now this upgrade 6.1.9 to 6.3.1 is just frozen on the setup of Drives. How do I get a copy of 6.1.9 again? I have a Pro key. I am almost to try and copy the previous folder to get back to 6.1.9. ?? -
I went from 6.1.9 to 6.3.1 with mostly no problems. Just did the recommended stuff. Uninstalled the old powerdown plugin. My system was upgraded from 6.1.9 to 6.2 then back to 6.1.9 almost right away. Wait a few months to go to 6.3.1. The only problem is my App tab has disappeared. I did just have a non-responsive VM and web gui and ssh not connectable, had to do a hard powerdown as the press the powerbutton once didn't shut it down gracefully as I would of seen the HD light go crazy. unraid-diagnostics-20170211-1608.zip

-
How to have Docker Container use a previous build from DockerHub?
Paul_Ber replied to Paul_Ber's topic in Programming
I finally got my build to finish without errors. https://hub.docker.com/r/paulpoco/arch-delugevpn/ -
How to have Docker Container use a previous build from DockerHub? I am having issues with of of my build and cannot get to successfully build. One of my Dockerhub builds from a few months ago worked fine, I just want to get my container up and running while I work out is wrong with my code.
-
I have the NMedia Pro-LCD -- 2 (rows) x 20 (characters). I just finally unplugged the USB header and power as I could not figure out how to get it to work in unRAID. I got it to work in a Ubuntu VM and Windows VM but that is not really useful.
-
How much RAM do you have installed in your unRAID server?
Paul_Ber replied to harmser's topic in Unraid Polls
32GB ECC (8GB x 4) -
"Reported performance issues with some low/mid range hardware. No movement on this yet." What type of hardware would be low/mid? Is there still an issue with AMD FX CPUs and VMs? I might of asked this elsewhere but cannot find it.
-
To get away from this, any Intel CPU/MB that will take ddr3 ecc ram? Has to be better than AMD 6300. More cores? Sent from my XT1563 using Tapatalk
-
Why did Limetech finalize 6.2.x if they knew hardware didn't work like AMD FX CPUs? They also broke the webui on 6.1.9 as soon as 6.2.0 came out, it got fixed. Don't they test? My pro license means stuck at 6.1.9. Will it be fixed soon?
-
Can unRaid support the nMedia PRO-LCD-B panel?
Paul_Ber replied to Paul_Ber's topic in General Support
Any Update on this? -
I updated to 6.2. The plugin tab said there was an error for Powerdown, so deleted. Now I cannot seem to find Powerdown in the CA.
-
unRAID Server Release 6.2 Stable Release Available
Paul_Ber replied to limetech's topic in Announcements
Was going to try and stop the array but it just goes forever saying retry unmounted. How does a non updated system start doing this? -
unRAID Server Release 6.2 Stable Release Available
Paul_Ber replied to limetech's topic in Announcements
Haven't upgraded yet but today I notice the web GUI is acting up. Is there something changed in community apps for 6.2 that is breaking 6.1.9? Warning: parse_ini_file(state/network.ini): failed to open stream: No such file or directory in /usr/local/emhttp/plugins/dynamix/template.php on line 43 Warning: extract() expects parameter 1 to be array, boolean given in /usr/local/emhttp/plugins/dynamix/template.php on line 43
-
If I was buying a motherboard I would get an Intel chip set and CPU that supports VM. I plugged a PCI video card and in bios set to boot from PCI and not PCIe. I have so far not got audio working correctly. I also have Video card in the PCIe x16 slot and one in PCIe x8 slot and have a Windows 7 VM and an Ubuntu VM working fine. Have not tried gaming because I mainly use it for the Plex Server.


