
testdasi
-
Posts
2812 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by testdasi
-
-
8 minutes ago, Cobragt88 said:
I have no clue why syslog is filling it up????
Known issue. "unexpected GSO type" issue flooding your syslog.
Read the release note (search for virtio-net).
Also read my post here for some alternative fixes.
-
17 minutes ago, Cobragt88 said:
Thought I'd bring this up, my routing table is wrong or is this the new behavior of 6.9? I don't have any /25 networks. So why did it add a /25? Also can't delete those /25 either. On 6.8.3 there was a no /25 networks on my routing table.
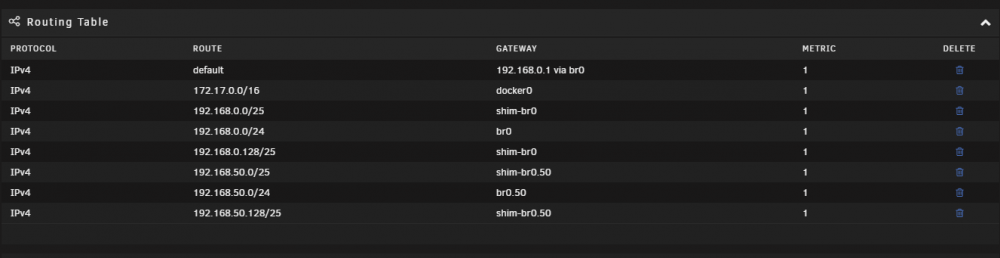
Settings -> Docker -> untick "Host access to custom networks"
-
2 minutes ago, Koenig said:
Well, I only have the one docker with static IP....
YMMV then.
-
So I got curious and did some more testing with the "unexpected GSO type" bug.
Changing VM to 5.0 (Q35 or i440fx) fixes the issue when there are a small number of dockers with static IP on the same bridge as the VM (e.g. br0 custom network).
In my particular server, "small number" is about 2-3 dockers.
In my tests (with reboot in between), the error happened after the 3rd or 4th dockers with static IP were started (not sure why sometimes 3rd, sometimes 4th).
The error seems to depend strictly on number of dockers and not number of VM. I started 5 VM with 2 static IP dockers and no error but 1 VM + 5 dockers guaranteed error.
So conclusion:
- If you only have a few dockers with static IP, try changing machine type to 5.0 first. That may fix it without the need of any further tweaks.
-
If you have many dockers with static IP (i.e. (1) doesn't fix it for you) then:
- If you have multiple NIC's then connect another NIC (different from the one on the VM bridge), don't give it IP (important to not have IP, otherwise chances are your VM access to the shares will be done through the router i.e. limited to gigabit), add it to a different bridge (e.g. br1) and use it instead of br0 for your docker static IP.
-
If you only have a single NIC then you will have to change your VM network to virtio-net.
- I think VLAN also fixes it but I have had no need for that so have no interest to test.
And I think the errors are harmless, other than flooding syslog. When I started with 6.9.0, I didn't realise there were errors until my syslog filled up and there was no other issue at all.
@Koenig: see above.
-
2 hours ago, Koenig said:
Just tried again and still same results, attaching my diagnostics if you wish to see for yor self.
unraid-diagnostics-20200821-0848.zip 182.76 kB · 0 downloads
It looks like switching to 5.0 fixes it for some and not for others (it was suggested somewhere earlier in the topic).
The officially guaranteed method is to switch to virtio-net (or set up VLAN or use separate NICs for docker and VM).
LT said next release will allow user to pick between virtio vs virtio-net, which I think is better than defaulting to virtio-net in beta25 since there are other ways to guarantee no errors.
-
16 minutes ago, Thorsten said:
I have some problems with VMs. I can´t passthrough my grafic card anymore. When i change something with the VM Ui i get this Error. (Fehler.png)
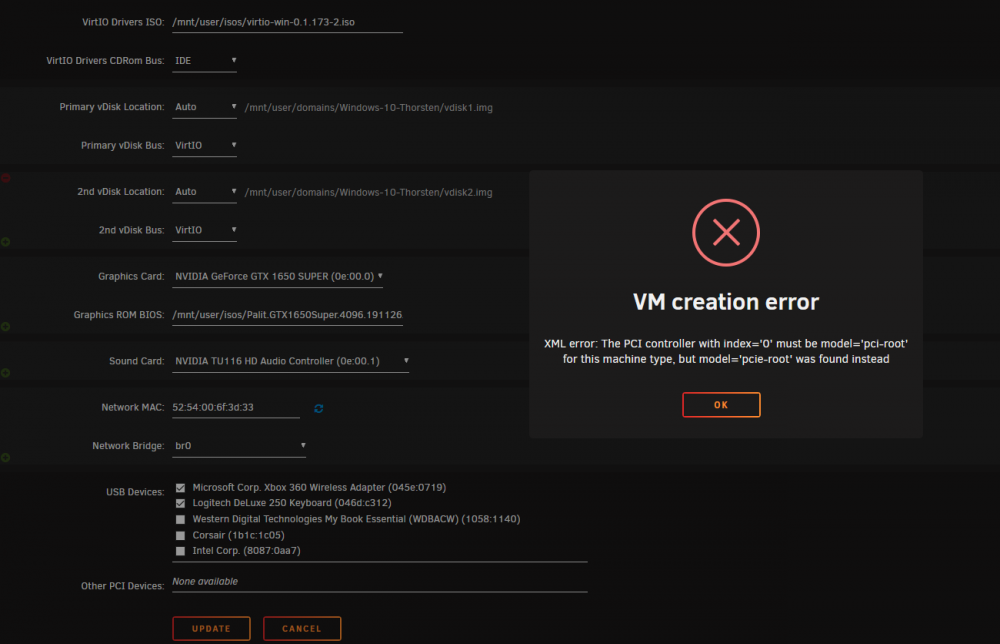
It looks like you changed your machine type from Q35 to i440fx?
Changing machine type cannot be done through the GUI. The only way is to create a brand new template. This applies to ALL Unraid versions so downgrading won't fix it.
Why do you want to change machine type to begin with? That is rarely if ever required (if anything, "modern" Windows VM should be using Q35 and not the super outdated i440fx)
And please attach diagnostics for any queries. (Tools -> Diagnostics -> attach the full zip file to your next post).
-
33 minutes ago, Thorsten said:
How can i downgrade from Beta 6.9 - 25 to the stable version 6.8.3?
If you updated from 6.8.3 then go to Tools -> Update OS. You should see Unraid OS (previous) which should have 6.8.3 in the version column.
Note that there are things not backward compatible e.g. 1MiB alignment, multiple pools etc. Read the beta release notes for more details.
-
10 hours ago, Marshalleq said:
Just to add some context - my VM DOES work in windows 10 on this beta. I have created a new template (by deleting the VM without deleting the disks) and created a new one - pointed back at the disks etc.
So that might be why it works, though personally I've always had to do this delete vm template dance in unraid since at least 3-4 versions ago. At leat with windows.
Networking isn't great though. Even downloaded the latest virt-io drivers but no difference. I've just passed through a physical Nic for now as connections were dropping.
Anyway. hopefully that works for you as an alternate option.
Just guessing, could be because you had your old template on 4.1/4.2 etc.? Creating a new template would immediately bring it to 5.0.
Networking default to virtio-net adapter with beta25. That has performance limitation. Try editing the xml and change virtio-net to virtio.
I was told the next 6.9.0 version will have the option to pick virtio or virtio-net.
-
28 minutes ago, Unraid Newbie said:
no, I have been running beta 25 for a month now.
I meant cpu problem started yesterday. didn't make any new changes.
honestly I can't tell if this is a beta bug or just a bug in general. but I don't see anyone post about it recently.
sorry if i posted incorrectly.
Then it's likely nothing to do with beta25. You probably have another issue happening so perhaps posting in the General forum instead. Don't forget to attach diagnostics, preferably right after you have experienced the problem without rebooting Unraid.
5 minutes ago, Cobragt88 said:Got a small problem with beta 25. My log file gets to 100% in a few days. This never happened before on 6.8.3. Just thought i'd say something, other than that, I don't have any problems with this version.
That suggests you have an issue. Logs don't fill up unless being bombarded with entries. Next time it happens, extract diagnostics (Tools -> Diagnostics -> attach full zip file to your next post).
-
 1
1
-
-
1 hour ago, Unraid Newbie said:
This just happened a day ago, didn't change anything to the VM xml. please help.
Did you just update to 6.9.0-beta25 "a day ago" i.e. it was all working fine before the update and then you updated and it immediately stopped working right after?
This topic is specific to 6.9.0-beta25 related issues to help with bug fixing. If you have an issue that cannot be specifically identified as being a problem with 6.9.0-beta25, you have a much better chance of getting help posting your issue in the main general help forum.
-
1 hour ago, DerfMcDoogal said:
So I was planning to add 2x 860 EVO 1TB SSDs this weekend as a Raid-1 btrfs Cache Pool... I'm on 6.8.2. Is it just my best bet to wait for 6.9 to get released? Is there anything I can do on my current version to get this going now without having to wait?
Update to 6.9.0-beta25? 😉
Longer answer: What you can do is to update to 6.9.0-beta25 now and test your server thoroughly (+ doing any necessary tweaks e.g. VM 5.0 / virtio-net etc.). As long as it's stable for you, there's no need to worry about the beta label. Then when you are ready, plop the 2 SSD in a new pool and format.
-
So repeated my test overnight for 15 hours
- Unraid 6.9.0-beta25
- 2x Intel 750 1.2TB
- BTRFS RAID-0 for data chunks, RAID-1 for metadata + system chunks
- Both partitions aligned to 1MiB
- 35 dockers running in BAU pattern i.e. not trying to keep things idle
Still average about 350 MB/hr (or 8.5 GB/day) on loop2 so sounds like that's my best baseline.
Loop2 is 5th on the list, only about 2% the top one on the list (which I know for sure has written that much data). So basically negligible.
-
57 minutes ago, vakilando said:
No, I'm on 6.8.3 and I did not align the parition to 1MiB (its MBR: 4K-aligned).
What is the benefit of aligning it to 1MiB? I mus have missed this "tuning" advice...
Yep, 6.9.0 should bring improvement to your situation. But as I said, you need to wipe the drive in 6.9.0 to reformat it back to 1MiB alignment and needless to say it would make the drive incompatible with Unraid before 6.9.0.
Essentially back up, stop array, unassign, blkdiscard, assign back, start and format, restore backup. Beside backing up and restoring from backup, the middle process took 5 minutes.
I expect LT to provide more detailed guidance regarding this perhaps when 6.9.0 enters RC or at least when 6.9.0 becomes stable.
Not that 6.9.0-beta isn't stable. I did see some bugs report but I personally have only seen the virtio / virtio-net thingie which was fixed by using Q35-5.0 machine type (instead of 4.2). No need to use virtio-net which negatively affects network performance.
PS: been running iotop for 3 hours and still average about 345MB / hr. We'll see if my daily house-keeping affects it tonight.
-
5 minutes ago, JP s said:
How do i get the diagnostics file?
Tools -> Diagnostics -> attach the zip file in full to your next post.
-
1 hour ago, TexasUnraid said:
If you go back a ways in this thread, you will find a few pages of me testing every possible scenario.
While the docker image is the main culprit for sure, appdata was not far behind. With just appdata on the BTRFS I was still seeing around 800mb/hour IIRC. Vs both on the XFS and ~200mb/hour combined.
Have you redone the tests on 6.9.0 + partition align to 1MiB?
It makes a huge difference.
Also you probably missed my point a bit. There is a balance to be struck between the needs for endurance vs resiliency.
-
Docker image has the lowest need for resiliency (everything is reinstallable so recovering from complete lost is a mundane mouse-clicking affair) so the need to increase longevity for the SSD naturally floats to the top.
- Then you add the loop2 amplification, which is the consistently the highest and exclusively affects docker image. That builds the case for having docker image in the xfs disk.
-
Appdata does have some needs for resiliency because reconfiguring every app is a pain in the backside, if impossible in some cases. So one has to debate if the need to reduce SSD wear would trump the need to protect the appdata against failure.
- In an ideal scenario, you would have a backup to mitigate the risk but just as parity is not a backup, a backup isn't a parity either (note: a mirror i.e. RAID-1 is a special case of parity).
It's like the UK government misguided effort to promote diesel cars to reduce carbon emission. The end result was air quality went down the drain due to particulate matter and nitrogen oxides in diesel exhaust.
So people don't die 10 years down the road because of global warming. They die next year because of lung cancer.
-
Docker image has the lowest need for resiliency (everything is reinstallable so recovering from complete lost is a mundane mouse-clicking affair) so the need to increase longevity for the SSD naturally floats to the top.
-
This is my quick test.
- Unraid 6.9.0-beta25
- 2x Intel 750 1.2TB
- BTRFS RAID-0 for data chunks, RAID-1 for metadata + system chunks
- Both partitions aligned to 1MiB
- 35 dockers running but mostly idle
403.41 MB / 70 minutes or 345.78 MB/hr.
About 100MB/hr worse than @TexasUnraid XFS image but only about 1/3 of @vakilando test.
Maybe I'll do an overnight run or something to see if there's any diff.

-
11 hours ago, TexasUnraid said:
In my case I decided to move appdata and docker to an XFS cache pool on 6.9 and leave everything else on the BTRFS pool.
Only docker image would need to be in xfs cache. Appdata isn't subjected to the same loop2 overhead. Which is great because the docker image doesn't really need protection.
5 hours ago, vakilando said:It's better than before (less writes for loop2 and shfs) but it should be even less or what do you think?
Are you using 6.9.0? Did you also align the parition to 1MiB? That requires wiping the pool so I would assume quite few people would do it.
-
I updated from 6.8.3 and there was no change to the cache pool.
You might want to provide details as to what you have done + attach diagnostics (Tools -> Diagnostics -> attach zip file).
-
4 hours ago, Velodo said:
All very good points, thanks for taking the time to answer! I can't help but wonder how many people will make the switch to Unraid from Freenas if zfs gets implemented. When I tried out Freenas years ago before purchasing Unraid it was certainly decent, but Unraid was way ahead when it comes to all the plugins, VMs, and Docker. Really glad I made the switch before it was too late, but as my data has grown my needs for many TB of faster storage than my Unraid pool can muster has also grown. I'm really hoping zfs will be the answer to that.
If you just want a fast pool, you don't quite need ZFS. 6.9.0 + btrfs cache pool work just as well.
You might be mixing up the Unraid array with the (cache) pool. The pool runs RAID and has no performance limitation.
-
9 minutes ago, Velodo said:
I'm excited to see the possibility of zfs! Assuming this does get added, is likely to be added to this release or a future release? I know giving exact timelines is impossible, but I've been planning an upgrade and part of that will include a smaller zfs pool that will be always spun up with everything except large media files, then a large unraid pool with the bulk of my media which will keep the drives spun down when possible to save on electricity. If official implementation is a ways out yet I might set it up with the zfs plugin and trying to deal with importing it later, but starting off with native support would probably be better.
While things may change, I really don't expect LT to implement ZFS in 6.9.0 due to a few factors:
- Has the question surrounding zfs licensing been answered? It's less of a legal concern for an enthusiastic user to compile zfs with Unraid kernel and share it. Most businesses need to get proper (and expensive) legal advice to assess this sort of stuff.
- ZFS would count as a new filesystem and I could be wrong but I vaguely remember the last time a new filesystem was implemented was from 5.x to 6.x with XFS replacing ReiserFS. So it wasn't just a major release but a new version number all together.
- At the very least, 6.9.0 beta has gone quite far along that adding ZFS would risk destabilising and delaying the release (which is kinda already overdue anyway as kernel 5.x was supposed to be out with Unraid 6.8 - so overdue that LT has made the unprecedented move of doing public beta instead of only releasing RC)
So TL;DR: you are better off with the ZFS plugin (or custom-built Unraid kernel with zfs baked in) if you need ZFS now.
Other than the minor annoyance of needing to use the CLI to monitor my pool free space and health, there isn't really any particular issue that I have seen so far, including when I attempted a mocked failure-and-recovery event (the "magic" of just unplugging the SSD 😅)
-
3
-
@limetech: given we now have multiple-pool, would it be possible to eliminate the requirement to have a device in the array? Even the 6.9.0-beta GUI now disables array-related attributes if cache = only.
-
11 minutes ago, TexasUnraid said:
Good to know, interesting use case as well. How would the script know that an attack is taking place?
So no gotchas with symlinks on unraid? works just like any other linux system (aka, I can look up generic symlink tutorials online)?
Very simple really. I took inspiration from the protect against cryptovirus plugin I saw on the app store. I put a few traps on various SMB locations and have a script run periodically to check on those traps if they change. It is just part of my overall strategy.
No gotcha. Have been using symlinks for years.
I think you don't need to wait for 6.9 RC. This is beta 25, not beta 1. It's pretty rock solid for me.
-
1
-
-
11 hours ago, TexasUnraid said:
The writes are massively inflated with appdata as well as docker. Now that we understand why, it makes sense, the tiny writes that both make will cause the writing of at least 2 full blocks on the drive + the filesystem overhead with the free space caching. Even if it just wanted to write 1 byte.
Great, so the symlinks won't cause any issues with the fuse file system?
I simply put a symlink in cache pointing towards the UD drive and everything works as expected, the files will be accessible from the /user file system?
That could work, have not actually used symlinks in linux yet but no time like the present to learn lol. Used them a lot in windows.
No prob with symlinks. I use that to point things everywhere.
I even make a kill switch for my most important data (bash script to remove the symlink takes millisecond to complete and would completely cut off my data from e.g. any cryptovirus doing sinister stuff on the network).
-
9 minutes ago, nlash said:
Can anyone ELI5 what this passage means for people using an Nvidia card for Plex hardware transcoding on 6.8 and an additional card passed through to a VM (also Nvidia)? I'm using the Nvidia version of Unraid.
Am I supposed to do something now, before 6.9 releases?
In the current beta, the VFIO-PCI.CFG plugin has been integrated into Unraid.
So instead of binding using the usual vfio-ids method in syslinux or manually editing the VFIO-PCI.CFG file (manually or through the plugin), you can now do that on the Unraid native GUI via Tools -> System Devices. You just tick the boxes next to the devices you want to bind for VM pass-through and apply and reboot.
What the passage means is in addition to the usual devices that you would need to bind (e.g. USB controller, NVMe SSD etc.), you should also bind the graphic card that you intent to pass through to the VM as well. That has not been required in the past and is not required until Nvidia / AMD driver is baked in. Better do it now rather than "my VM stops working" in the future.
Right now though, there is no implication since there's no Nvidia / AMD driver included (yet).
Side note: if the syslinux method has been working for you then you don't really need to use the new GUI method. Just need to take note to add the graphic card device ID to syslinux as well.




Unraid OS version 6.9.0-beta25 available
-
-
-
-
-
in Prereleases
Posted
Reboot is the best way but you can try this. Also from command line go to /var/log and delete the old syslog.1 and 2 and so on.
echo "$(date "+%d.%m.%Y %T") Log was cleared." > /var/log/syslogYou should post a separate bug report with Diagnostics. Also perhaps try Q35 machine type (but I doubt it would help). And ask SpaceInvader One if he has any tips.