

DjSamLb
-
Posts
55 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by DjSamLb
-
After moving docker image to cache and spinning down Disk1 as it was no longer used, I just had a kernel panic help!
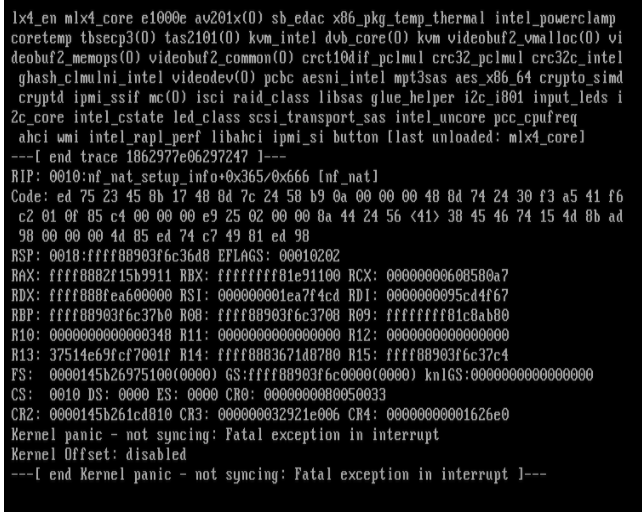
-
I don't remember it ever did with the older versions; any version in particular? I am trying now moving the docker image to the cache SSD and clearing disk1 and check if the problem reoccurs
-
Here's the syslog from the syslog server if it offers anything plus? syslog-192.168.100.133.log
-
Disk1 is a SAS drive and SMART report never worked on it I guess any other way to check if Disk1 is failing? Also if it's not Disk1 anything else in the logs or diagnostics that shows any other problems?
-
Here you go I'm suspecting Disk1 is failing because docker image is on that hdd and it has been loading the docker containers very slowly recently Thanks a lot for your help! tower-diagnostics-20200623-1822.zip
-
I don't think this is the culprit I suspect Disk1 which holds docker image? Any indication that it's failing?
-
I have been having trouble with Unraid for the last week or so where I had two Kernel Panics and today all docker containers were frozen and I couldn't restart the server from the webUI or from ssh poweroff script or shutdown -h now managed to copy the syslog before I hard rebooted any idea whats wrong? syslog
-
So u think I have nothing to worry about? I'll still run another check next week just to be safe Thanks a lot for all the help!
-
@johnnie.black First run had zero errors Gonna do another run next week just to be sure Do u think it's a one time glitch? anything in the diags flagged? Did u try running more scans?
-
Ok already started it; will report back in 18 hours thanks a lot for the great help!
-
Ok will do that And if the exact same amount of errors that would be a one time thing? just run check with fix parity?
-
None, or at least not that I know of I should probably mention that the VM first was using the Cache but then due to heavy I/O I moved it to a dedicated SSD passhtroughed Dno if that might be the culprit
-
Also noticed that dual parity are not in sync in number of reads and writes I think I recall they were always in sync before?

-
After using UNRAID with zero issues and loving it for so long, today I received that the monthly parity check returned 1194 errors I must add that this month I swapped out the cpu and added an SSD and a GPU passthroughed to a VM no other changes I also noticed that my second parity drive is connected via SATA2 and not 3 no idea if that has been all along or if it's having cable issues or maybe wrong port? Please find attached my diags tower-diagnostics-20200305-1020.zip
-
+1 no corruption on my server running 6.7.2 with appdata on the cache nvme On my hetzner hosted server with no cache disks; had corruption in 2 days after 6.7.2 upgrade, went back to 6.6.7 and no corruptions since
-
yup it is thanks!
-
Same problem
-
Hi I had the same problem ran this command in terminal: sudo chown 911:911 /mnt/disks/rclone_volume/ and restarted the docker and it worked added it to the go file and now all is good try it
-
Thanks a lot!!!!
-
Oh ok Thanks a lot! love the help! BTW should I run another parity check when this one is done?
-
It was an empty drive Btw the last 4TB wd red never gets any data on it Any idea why? I have all discs selected in Global share settings
-
any hdd errors? tower-diagnostics-20170129-0349.zip
-
Done Thanks a lot!! great help
-
That solved it thank you! Any help on how to keep parity to rebuild the replaced drive after I did a new config?
-
I had a failure on a 300GB SAS Drive in my array of 9 x 300GB SAS drives, 4 x 3TB WD Reds, 4 x 4TB Wd reds and 2x 6tb wd reds for parity I replaced the drive with another 300GB Sas drive but when I select the new drive the page refreshes but the drive isn't selected anymore I tried doing a new config; the wd reds get readded fine and ready to start the array but all 9 of the 300gb sas drives can't be added; after the page refreshes the drive goes back to unassigned HELP GUYS!!

