

darrenyorston
-
Posts
321 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by darrenyorston
-
-
2 hours ago, biggiesize said:
I have not seen glutetun be removed after an update. Can you reinstall it through the appstore? You should be able to find it under previous apps and it maintain your settings.
Could possibly be startup order. Make sure that glutun starts before all the apps that use it for network.
Hello. Yes I can reinstall the container. It is a brand new install though. Interestingly there remains a gluetun fodler within appdata but it only contains a servers.json file. Are there any other unRAID logs which would record the containers deletion. By the system log GluetunVPN was updated at 020122 Jan 16 and restarted at 020144. Community Applications ran autoupdate at 020145. Could the Community Applications update have removed the container?
-
Hello. I have been using GluetunVPN successfully for awhile now. However, this morning when I went to use a browser which was using GluetunVPN I received an error. Upon looking at my containers it appears the container has been removed from my system, though I did not do it. Looking at the unRAID logs I can see the following:
Jan 16 01:00:01 Tower Plugin Auto Update: Checking for available plugin updates Jan 16 01:00:06 Tower Plugin Auto Update: unassigned.devices.plg version 2022.01.15 does not meet age requirements to update Jan 16 01:00:06 Tower Plugin Auto Update: Checking for language updates Jan 16 01:00:06 Tower Plugin Auto Update: Community Applications Plugin Auto Update finished Jan 16 02:00:01 Tower Docker Auto Update: Community Applications Docker Autoupdate running Jan 16 02:00:01 Tower Docker Auto Update: Checking for available updates Jan 16 02:01:19 Tower Docker Auto Update: Stopping Thunderbird Jan 16 02:01:21 Tower kernel: br-92a4b7e2cd0e: port 15(vetha2f1c80) entered disabled state Jan 16 02:01:21 Tower kernel: veth48e0c6f: renamed from eth0 Jan 16 02:01:21 Tower kernel: br-92a4b7e2cd0e: port 15(vetha2f1c80) entered disabled state Jan 16 02:01:21 Tower kernel: device vetha2f1c80 left promiscuous mode Jan 16 02:01:21 Tower kernel: br-92a4b7e2cd0e: port 15(vetha2f1c80) entered disabled state Jan 16 02:01:21 Tower Docker Auto Update: Stopping GluetunVPN Jan 16 02:01:22 Tower kernel: docker0: port 1(veth33f7aaf) entered disabled state Jan 16 02:01:22 Tower kernel: vethc33b19e: renamed from eth0 Jan 16 02:01:22 Tower kernel: docker0: port 1(veth33f7aaf) entered disabled state Jan 16 02:01:22 Tower kernel: device veth33f7aaf left promiscuous mode Jan 16 02:01:22 Tower kernel: docker0: port 1(veth33f7aaf) entered disabled state Jan 16 02:01:22 Tower Docker Auto Update: Stopping redis Jan 16 02:01:22 Tower kernel: br-92a4b7e2cd0e: port 9(veth5b87852) entered disabled state Jan 16 02:01:22 Tower kernel: veth6afa664: renamed from eth0 Jan 16 02:01:22 Tower kernel: br-92a4b7e2cd0e: port 9(veth5b87852) entered disabled state Jan 16 02:01:22 Tower kernel: device veth5b87852 left promiscuous mode Jan 16 02:01:22 Tower kernel: br-92a4b7e2cd0e: port 9(veth5b87852) entered disabled state Jan 16 02:01:22 Tower Docker Auto Update: Installing Updates for Thunderbird GluetunVPN redis Jan 16 02:01:44 Tower Docker Auto Update: Restarting Thunderbird Jan 16 02:01:44 Tower kernel: br-92a4b7e2cd0e: port 9(vethf1f6747) entered blocking state Jan 16 02:01:44 Tower kernel: br-92a4b7e2cd0e: port 9(vethf1f6747) entered disabled state Jan 16 02:01:44 Tower kernel: device vethf1f6747 entered promiscuous mode Jan 16 02:01:44 Tower kernel: eth0: renamed from veth15ea6ed Jan 16 02:01:44 Tower kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethf1f6747: link becomes ready Jan 16 02:01:44 Tower kernel: br-92a4b7e2cd0e: port 9(vethf1f6747) entered blocking state Jan 16 02:01:44 Tower kernel: br-92a4b7e2cd0e: port 9(vethf1f6747) entered forwarding state Jan 16 02:01:44 Tower Docker Auto Update: Restarting GluetunVPN Jan 16 02:01:44 Tower Docker Auto Update: Restarting redis
There is no mention of GluetunVPN beign removed however it ius no longer showing as installed. How could this happen? I am a little concerned that modifications to my server could happen this way, without atleast being prompted.
-
On 11/24/2021 at 11:32 AM, darrenyorston said:
Hello all. Following up on a previous post re Scrutiny. How do you get it to show all the drives in the array? Mine only shows three, though one popped up after a week or so of running. My config has /dev/sda, /dev/sdb, /dev/nvme1n1, and /dev/nvme2n1 in the template but when I start the UI /dev/sdb, /dev/sdh, and /dev/sdi are displayed.
Is there another config somewhere I have to change to have it show all 11 drives?
I ended up solving the issue of drives not chowing up. I edited the scrutiny.yaml file in appdata. There is a field called "disks:" I added all my drives and they showed up straight away in the UI. I dont know why but editing the drives in the docker template makes no difference to. The UI always shows what's in the .yaml file.
-
Hello all. Following up on a previous post re Scrutiny. How do you get it to show all the drives in the array? Mine only shows three, though one popped up after a week or so of running. My config has /dev/sda, /dev/sdb, /dev/nvme1n1, and /dev/nvme2n1 in the template but when I start the UI /dev/sdb, /dev/sdh, and /dev/sdi are displayed.
Is there another config somewhere I have to change to have it show all 11 drives?
-
Still trying to work out my ongoing issues with VMs on unraid. At the moment I have been able to get my VMs to stop freezing. I have been disabling/enabling the VM manager and rebooting. Its taken a few restarts but at the moment VMs seem to not freeze. Though I am having an issue now where the mouse does not fucntion correctly when passed through. Everythign works fine when a VM boots into the live CD but once I restart the VM I find that my mouse activates on the opposite screen, I have two, to where the mouse pointer is. I can open the menu on my left screen by clicking in the position where the mouse would be on the other screen. Anyone else experienced this and found a solution?
I have tried a variety of Linux VMs and its always the same.
-
Anyone able to explain how to get the container to see all the drives on my system? At the moment it will only show the two in the /dev/sda and /dev/sdb fields. Nor will it show my NVMe drives.
-
11 hours ago, Frank1940 said:
I would assume that both of these failures have been the same disk. If that is the case and it happens again, change the SATA data cable and check the SATA power cable to that drive. If you are using a power splitter type cable, consider replacing it also. (Avoid the type where the wires are molded into the plastic, they are a potential fire hazard.)
Always double (and even triple) check every SATA connector to make sure that is firmly seated before applying power. It is not uncommon that in changing out one drive that the connector on another drive will be unseated ever so slightly!
For several years, I have always had spare 'cold' drive(s) for my systems. Whenever a drive goes off-line, my first action is to replace it with the spare. I then run a two or three preclear cycles on that 'failed' drive. If it passes, it becomes the cold spare. IF it has any SMART errors other than an 'UDMA CRC error rate' (#199), it is headed for the trash bin. (Fortunately, I have never had a second failure of the same Disk within a short period. But if I were to experience that, I would be doing what I suggested in the first paragraph...)
I had checked the cabling for each drive. They didnt appear to be out of place; they didnt move when I pressed them. And the system had been restarted as I have been trying to resolved an issue with VMs randomly freezing.
-
10 hours ago, Frank1940 said:
I would assume that both of these failures have been the same disk. If that is the case and it happens again, change the SATA data cable and check the SATA power cable to that drive. If you are using a power splitter type cable, consider replacing it also. (Avoid the type where the wires are molded into the plastic, they are a potential fire hazard.)
Always double (and even triple) check every SATA connector to make sure that is firmly seated before applying power. It is not uncommon that in changing out one drive that the connector on another drive will be unseated ever so slightly!
For several years, I have always had spare 'cold' drive(s) for my systems. Whenever a drive goes off-line, my first action is to replace it with the spare. I then run a two or three preclear cycles on that 'failed' drive. If it passes, it becomes the cold spare. IF it has any SMART errors other than an 'UDMA CRC error rate' (#199), it is headed for the trash bin. (Fortunately, I have never had a second failure of the same Disk within a short period. But if I were to experience that, I would be doing what I suggested in the first paragraph...)
That is a good idea, thanks.
-
1 hour ago, trurl said:
Probably nothing wrong with the disk. Connection problems are much more common than disk problems. Since you likely rebooted since you had that problem we wouldn't be able to see what caused the disk to be disabled.
Attach diagnostics to your NEXT post in this thread and we can see if there is anything else of concern.
-
One of the spinning disks in my array has been reporting errors. Recently it went offline. As a result I replaced the disk. After the new disk was rebuilt I ran pre-clear on the failed disk. Unassigned devices is reporting the pre-clear finished successfully. I cant see anything notable in the log file, though I do not really know what would be considered a problem. I have attached the log. As a result I wondering about the reliability of disk error reporting. Is the disk good or bad? What should I have confidence in? The array reporting problems and taking the disk offline or the pre-clear check?
Oct 31 00:50:30 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: dd if=/dev/sdc of=/tmp/.preclear/sdc/fifo count=2096640 skip=512 iflag=nocache,count_bytes,skip_bytes Oct 31 00:50:31 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: verifying the rest of the disk. Oct 31 00:50:31 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: cmp /tmp/.preclear/sdc/fifo /dev/zero Oct 31 00:50:31 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: dd if=/dev/sdc of=/tmp/.preclear/sdc/fifo bs=2097152 skip=2097152 count=3000590884864 iflag=nocache,count_bytes,skip_bytes Oct 31 01:23:48 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 10% verified @ 148 MB/s Oct 31 01:58:04 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 20% verified @ 141 MB/s Oct 31 02:33:47 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 30% verified @ 135 MB/s Oct 31 03:11:30 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 40% verified @ 129 MB/s Oct 31 03:51:17 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 50% verified @ 120 MB/s Oct 31 04:33:51 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 60% verified @ 114 MB/s Oct 31 05:19:12 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 70% verified @ 106 MB/s Oct 31 06:08:59 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 80% verified @ 94 MB/s Oct 31 07:04:27 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: progress - 90% verified @ 84 MB/s Oct 31 08:08:01 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: dd - read 3000592982016 of 3000592982016 (0). Oct 31 08:08:01 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: elapsed time - 7:17:28 Oct 31 08:08:01 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: dd exit code - 0 Oct 31 08:08:02 preclear_disk_WD-WCC4N1AKP9J6_127711: Post-Read: post-read verification completed! Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Cycle 1 Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: ATTRIBUTE INITIAL NOW STATUS Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Reallocated_Sector_Ct 0 0 - Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Power_On_Hours 47106 47128 Up 22 Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Temperature_Celsius 34 31 Down 3 Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Reallocated_Event_Count 0 0 - Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Current_Pending_Sector 0 0 - Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: Offline_Uncorrectable 0 0 - Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: UDMA_CRC_Error_Count 0 0 - Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: S.M.A.R.T.: SMART overall-health self-assessment test result: PASSED Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: Cycle: elapsed time: 21:33:48 Oct 31 08:08:06 preclear_disk_WD-WCC4N1AKP9J6_127711: Preclear: total elapsed time: 21:33:53
-
On 10/31/2021 at 10:17 PM, okkies said:
How would the companion plugin work for the elgato streamdeck ?
did you ever get this to work ?
The streamdeck? No. Never tried. I also moved away from using ControlR. I found it easier just to use the tablet browser.
-
How do I get the container to show all my drives? I followed the instruction to add '/dev:/dev' to the field '/dev/sda' however it reports server error when I try to start the container. Also adding `--cap-add=SYS_ADMIN` for the NVME drive results in server error.
-
Its obviously a straight forward process to do periodic backups to a Synology NAS from unraid. Keeping two Synology devices in sync over the internet is built into Synology NAS so that isnt a problem. I was hoping someone might have containerised Synology's Cloud Station app which would allow unraid to sync files directly to a remote site.
-
I had looked at a few of those. I was looking to avoid using cloud services for obvious reasons, which necessitates a local solution, either an OTS NAS, a home brew NAS or a PC. I was against a PC, particularly for the remote site as I want something which would be unobtrusive and require no interaction from people at the host location. Hence why I was thinking of a OTS NAS like the Synology. I know I could have two Synology NAS, one remote and a second in the same physical location as my main server but as I already have a local backup this would be a duplication.
I was wondering whether there was a docker container which allowed for the mirroring function used by Synology. Essentially that I could connect a remote NAS to the docker container for the data sync.
-
I thought the libvrt log would show that the VM has crashed. So I am presuming the problem is occuring before the error/s can be logged.
-
11 hours ago, RiDDiX said:
Did you find anyway around your freezes? Would be interesting...
Not as yet, no.
At the moment I see no errors in the VM logs.
I do however see errors in the Libvirt Log:
2021-10-21 08:37:19.994+0000: 10790: warning : qemuDomainObjTaint:6075 : Domain id=3 name='Manjaro' uuid=93250046-5efe-9082-9009-bc183f6d4f6c is tainted: high-privileges
2021-10-21 08:37:19.994+0000: 10790: warning : qemuDomainObjTaint:6075 : Domain id=3 name='Manjaro' uuid=93250046-5efe-9082-9009-bc183f6d4f6c is tainted: host-cpu
2021-10-21 08:40:40.443+0000: 10788: warning : qemuDomainObjTaint:6075 : Domain id=4 name='Arch' uuid=fb5a38b0-6857-abb5-caba-1df6b23360a2 is tainted: high-privileges
2021-10-21 08:40:40.443+0000: 10788: warning : qemuDomainObjTaint:6075 : Domain id=4 name='Arch' uuid=fb5a38b0-6857-abb5-caba-1df6b23360a2 is tainted: host-cpuThis was the log for the Manjaro VM when it crashed. Nothing draws my attention. I had to do a forced shutdown as the VM was frozen.
ErrorWarningSystemArrayLogin
-uuid 93250046-5efe-9082-9009-bc183f6d4f6c \
-display none \
-no-user-config \
-nodefaults \
-chardev socket,id=charmonitor,fd=31,server,nowait \
-mon chardev=charmonitor,id=monitor,mode=control \
-rtc base=utc,driftfix=slew \
-global kvm-pit.lost_tick_policy=delay \
-no-hpet \
-no-shutdown \
-boot strict=on \
-device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 \
-device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 \
-device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 \
-device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 \
-device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 \
-device pcie-root-port,port=0xd,chassis=6,id=pci.6,bus=pcie.0,addr=0x1.0x5 \
-device pcie-root-port,port=0xe,chassis=7,id=pci.7,bus=pcie.0,addr=0x1.0x6 \
-device ich9-usb-ehci1,id=usb,bus=pcie.0,addr=0x7.0x7 \
-device ich9-usb-uhci1,masterbus=usb.0,firstport=0,bus=pcie.0,multifunction=on,addr=0x7 \
-device ich9-usb-uhci2,masterbus=usb.0,firstport=2,bus=pcie.0,addr=0x7.0x1 \
-device ich9-usb-uhci3,masterbus=usb.0,firstport=4,bus=pcie.0,addr=0x7.0x2 \
-device virtio-serial-pci,id=virtio-serial0,bus=pci.2,addr=0x0 \
-blockdev '{"driver":"file","filename":"/mnt/user/domains/Manjaro/vdisk1.img","node-name":"libvirt-1-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \
-blockdev '{"node-name":"libvirt-1-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-1-storage"}' \
-device virtio-blk-pci,bus=pci.3,addr=0x0,drive=libvirt-1-format,id=virtio-disk2,bootindex=1,write-cache=on \
-netdev tap,fd=33,id=hostnet0 \
-device virtio-net,netdev=hostnet0,id=net0,mac=52:54:00:db:9c:d8,bus=pci.1,addr=0x0 \
-chardev pty,id=charserial0 \
-device isa-serial,chardev=charserial0,id=serial0 \
-chardev socket,id=charchannel0,fd=34,server,nowait \
-device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 \
-device vfio-pci,host=0000:44:00.0,id=hostdev0,bus=pci.4,addr=0x0,romfile=/mnt/user/isos/vbios/GTX1080.rom \
-device vfio-pci,host=0000:44:00.1,id=hostdev1,bus=pci.5,addr=0x0 \
-device vfio-pci,host=0000:45:00.3,id=hostdev2,bus=pci.6,addr=0x0 \
-sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \
-msg timestamp=on
2021-10-21 08:47:16.522+0000: Domain id=6 is tainted: high-privileges
2021-10-21 08:47:16.522+0000: Domain id=6 is tainted: host-cpu
char device redirected to /dev/pts/0 (label charserial0)
2021-10-21T08:52:46.745914Z qemu-system-x86_64: terminating on signal 15 from pid 10785 (/usr/sbin/libvirtd)
2021-10-21 08:52:48.146+0000: shutting down, reason=destroyed -
Ive started using the S3 Sleep plugin to shutdown my server at night. It works fine with WOL however every time the system restarts it commences a Parity-Check as a result of an unclean shutdown.
Ive seen a number of posts from users with similar issues however none have a solution. Anyone else have this issue and found a solution?
-
On 6/23/2021 at 1:39 AM, xerox445 said:
Hello,
I recently configured my server to shut off at 7am in the morning, and turn back on at 7pm. I have it functioning with a combo of a shutdown program within my windows 10 VM I am running, the s3 sleep plugin addon to get the server to shut down, and a WIFI plug/timer to kill power a half hour later at 730, and restore it at 700 pm to turn the server back on.
Unfortunately, I can not get unraid to shut down cleanly, and it keeps triggering a parity check when it turns on. The VM I have is on a NVME drive, formatted with unassigned devices not in the array.
Is there a command I can or need to add to the s3 sleep addon to get this to function correctly? Keep in mind, I want to do a full shutdown, not a s3 sleep.
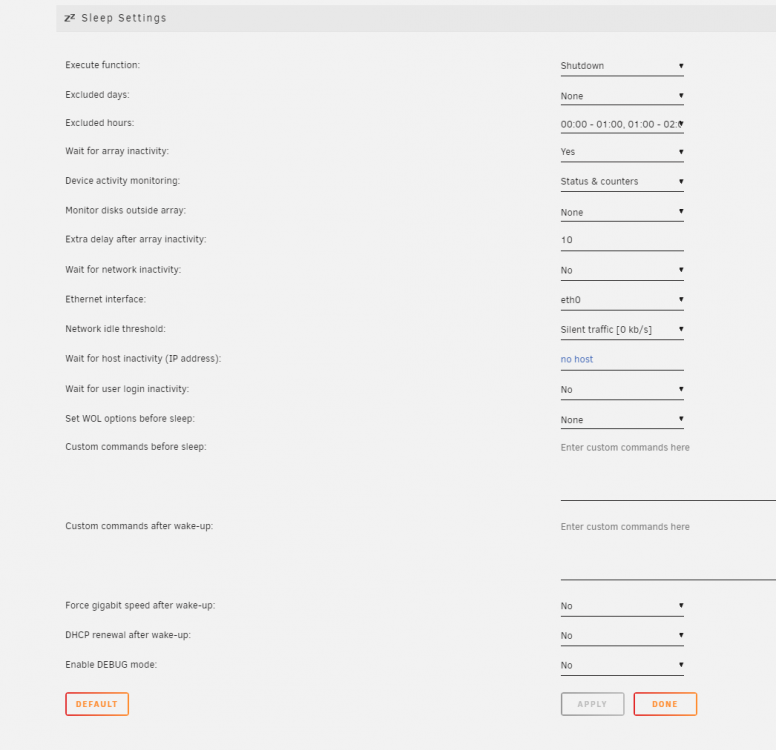
Hello. I have this problem also. Did you find a resolution?
-
Id like to get TPLink Energy Monitoring running on unraid. There are standalone containers around as well as ones using influxDB and Prometheus. Anything workable on unraid that people have seen? I tried installing one from DockerHub but it has a port conflict with Grafana and I dont know how to change the containers port allocation.
-
I am having an issue with VMs freezing randomly. I dont see any problems in the log for the VM and its not causing an issue with the host machine. The VMs are completely unresponsiveness and require the VM to be forced shutdown and restarted. Are there any places other than the VM log where I can look for problems?
-
Hello all. Im trying to set up the container to work with ProtonVPN. There are a lot of config options in the container template; I dont know which are required or not. Im wanting to use the container as a proxy for certain browsers on some of my devices. I was hoping that I could use my local PiHole for DNS/Adblocking if at all possible. Anyone able to share a sanitised version of their config?Hello all. Im trying to set up the container to work with ProtonVPN. There are a lot of config options in the container template; I dont know which are required or not. Im wanting to use the container as a proxy for certain browsers on some of my devices. I was hoping that I could use my local PiHole for DNS/Adblocking if at all possible. Anyone able to share a sanitised version of their config?
-
I am looking to expand my backup approach. Currently I am backing up important materials to a separate, but local, storage system. I am interested in adding in some remote storage. I was recently watching a Network Chuck video where he was showing how he had files in sync between two remote locations with Synology NAS.
I was wondering if it is possible to do the same thing but from Unraid to an OTS NAS like the Synology. Obviously do the main backup on site due to the size of the data involved, then move the devices to their remote locations.
Anyone done this? Or seen someone doing this?
-
7 hours ago, Kru-x said:
You just open the template file in your list for ex. wordpress (if that what you have named it) and rename the next template to wordpress2, then you have to choose a different folder. I name the folder exactly the same as the container eg "wordpress2" and the port number. The newly named template will be saved in your list of templates you have, the old still remains. You could also choose the app from the comunity app page, same same and this can be done with all containers in the same way. It is just how unraid templates and docker works.
Kru-x
ahh ok. ill give that a go. thanks.
-
11 hours ago, Kru-x said:
And I guess after reading your post through properly 😏 I didn't actually answered your question. Hups. But you just name the second wordpress installation differently and use a different folder for the installation as well as a different port offcourse. Then install it as you did with the first one pointing it to the db of your choice. Then you should be up and running.
Kru-x
Thanks mate. I hear what you are saying. But how do you actually install a duplicate container of the same type as one already installed? Whenever I try it opens the config for my existing container. I presume you do it by some means other than using the community applications tab? Or do you open the application values for the container in community applications, append something to distinguish a new container which, as a result, creates a duplicate container?

[SUPPORT] DiamondPrecisionComputing - ALL IMAGES AND FILES
in Docker Containers
Posted
tower-diagnostics-20220116-1847.zip