





1812
Members
-
Joined
-
Last visited
Everything posted by 1812
-
I found it, and this is correct. it was a script I had long forgotten about and couldn't see because... I didn't scroll down far enough.... thanks!
-
the time stamps are "old" because I hadn't opened my dashboard in like 3 weeks. But as you can see from my current attachment, it still does it. Also, since posting, I updated to 7.0.1 just to see if it would change anything. it did not.
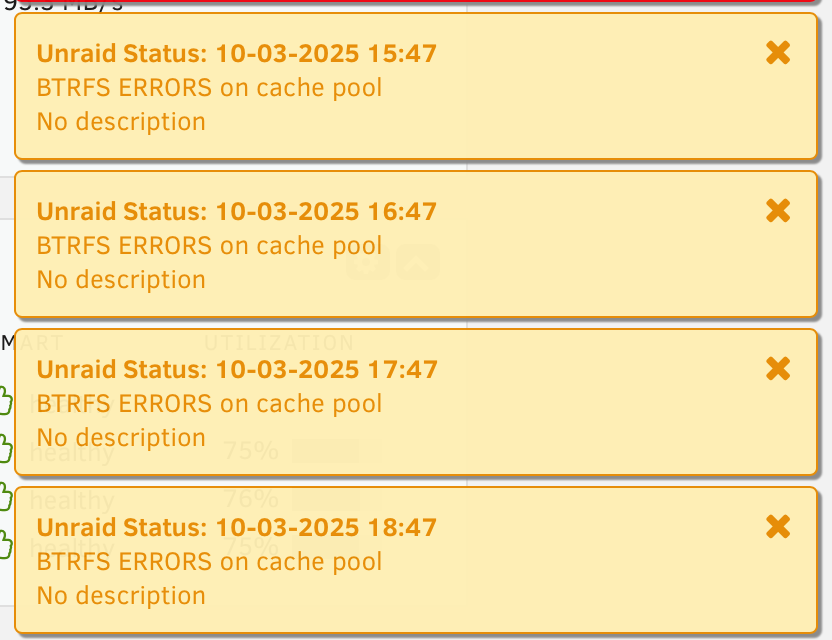
-
diagnostics-20250310-1651.zip
-
Maybe I wasn't clear. I didn't ask for the notifications, and did not have anything setup to request the monitoring of the cache pool previously when it was btrfs. the messages just began appearing after conversion. So I'm unclear how using a script to request monitoring it as zfs will make it stop showing errors for a format it no longer exists in. thanks
-
on 7.0.0 Converted my cache pool (2 drives) from btrfs to zfs. Now the pop up notification says there are errors on it. But there is nothing in the server log. how do I make this annoyance go away?
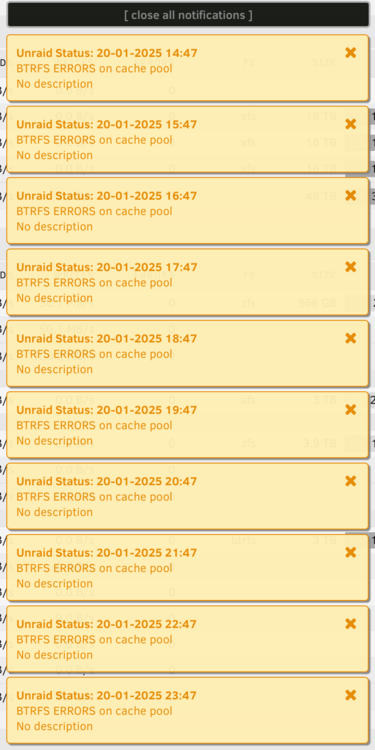
-
Was this forum upgrade included in my lifetime license?!? Or do I have to subscribe to keep it???? I don't understand how these new license systems work.... am I grandfathered? What about new users? Are security updates included? They really should be IMO.... This all smells like a cash grab to me.....If only there were an FAQ I could read and comprehend.... (I'm just messing around, nobody get their knickers knackered ❄️)
-
(chuckling at the irony of some of these people who illegally download movies they didn't pay for, complaining that software they already own that isn't changing, but new purchases will incur potential recurring fees to support further development of the platform they love, use, and, again, already own and will continue to receive the benefits of using at no additional cost.) Seriously folks, it's a standard, common sense practice for mature software to have recurring fees to sustain continued development. If it didn't, once you hit a market saturation point for your product, you essentially can only cover maintenance but no other development (or get in the business of harvesting your existing user base's personal information to sell to third parties.) Some of you complaining would be shocked to learn that there are many of us that pay hundreds every year for updates to other software companies we use and need. From audio and video editing, to network licensing. I do. I just did 2 weeks ago! But I evaluate if the new features in that next version are worth it, or skip a generation. Now, with all that said, I will honestly admit that the little cheapskate in me doesn't like any increase on anything ever! Even if I can rationally justify it. And that's because nobody really wants to gleefully pay more for anything. I hear you. I feel you. I started out like some folks cobbling together hardware and sketchy drives to make my first server. Many of you are probably still in this stage. But 8 years later, and after numerous sever interactions, I run 4 licenses now on solid hardware with solid drives [knock on wood.] If their newly announced model was implemented when I first looked around 8 years ago, it would have given me the same pause to consider it versus alternatives. I would have still tried all the other free operating systems like I did. But I think in the end, I would have still picked Unraid for its ease of use, ability to run on a wide range of hardware, and community support. I think that it's ridiculously generous that Unraid has stated that they will grandfather previously sold licenses to have continued updates. Some of my licenses are 7 or 8 years old, and I'm still getting new features, new patches, and more. There is no other software that I own that has done that beyond a few years. This is why I have recommended this os, and will continue to do so. I'll just tell people to suck it up and buy the lifetime upfront, as it'll pay for itself over time, and give the dev's the ability to do more sooner. --- as a postscript, don't reply to me with nonsensical arguments or how it "costs a month's worth of food" replies. I'll just ignore them. This software is a luxury, not a necessity. If you are having to make the decision between eating versus storing more data than the average pc can do, then the solution is simple; go use a completely free os and stop making irrelevant arguments.
-
works fine for me either way on both machines I have running 6.12.3. For reference, I'm on safari Version 16.5.1 (18615.2.9.11.7)
-
upgraded 2 similar machines from .2 to .3 no issues except this is new: Jul 17 14:54:50 Tower1 smbd[24128]: [2023/07/17 14:54:50.767379, 0] ../../source3/lib/adouble.c:2363(ad_read_rsrc_adouble) Jul 17 14:54:50 Tower1 smbd[24128]: ad_read_rsrc_adouble: invalid AppleDouble resource .DS_Store but I'm not that concerned about it at the moment because of the file type/what that does. I haven't had any file transfer issues (yet) will come back if it becomes a thing.
-
helped me out a few times (both in my own threads and when searching for previously solved threads), much appreciated and congrats!
-
regular user shares are a little bottlenecked on unraid. to increase smb performance look at https://forums.unraid.net/topic/100855-workaround-how-to-get-macos-smb-transfers-at-1gbs-on-10gbe/ and the original source https://forums.unraid.net/topic/97165-smb-performance-tuning/#comment-895985
-
Happy New Year! I'm new to 3d printing so I thought I'd give this docker a try my an ender 3 s1 pro. I ran into the same issue with serial/by-id issue and had the same result using "udevadm info --name=/dev/bus/usb/001/002" showing "device node not found". This may not be the "right" way but this is what I did to get my printer recognized: 1. open a terminal window on unraid server web page 2. enter "cd /dev/serial/by-id" 3. enter "dir" this showed me what I was after, which in my case was: usb-1a86_USB_Serial-if00-port0 in the docker template I changed it to "/dev/serial/by-id/usb-1a86_USB_Serial-if00-port0" I then followed the directions in the second post of this topic (even though I don't have multiple printers) which were 1) go to settings/serial connections and add /dev/serial/by-id/* to "Additional serial ports" 2) save 3) go to settings/serial connections and change AUTO in the serial port list to your device 4) save Just completed my first test and it all seems to be doing what it is suppose to. Hope that helps!
-
updated 2 machines from 6.11.x to this. no issues.

-
upgraded 2 boxes: one from 6.11.3, the other from 6.10.3. no issues currently observed. SPIFFY!
-
1. you can assign as many cores as you have to your vm or a number of vm's. 2. Any level of unRaid does this. The difference in the levels is the amount of disks you can attach. you can assign whatever and however many cores to any vm, and even stack vm's on the same cores (though you'll get an understandable performance penalty.) You can even isolate the cores away from unRaid running as host and reserve the cores to only be used by the vm's you choose. 3. open a question in the appropriate place on the forum and someone will probably be able to help you with that.
-
Over 4 years later and now I'm changing my +1 to a +10
-
side note: you can get around the halted boot process for missing devices by disabling them in the bios.
-
why does it keep installing the newest Nvidia driver after every update? I use a gt for Plex and it always rolls to the latest vs keeping me on the 470.129.06 which is the one that works for this card.
-
FWIW I have 2 HP ML30 Gen 9 servers updated to 6.10.2, both with dual: 02:00.0 Ethernet controller: Broadcom Inc. and subsidiaries NetXtreme BCM5720 Gigabit Ethernet PCIe 02:00.1 Ethernet controller: Broadcom Inc. and subsidiaries NetXtreme BCM5720 Gigabit Ethernet PCIe I did the "un-blacklist" procedure and have experienced no errors. I will also add that the Broadcom controllers are not eth0 in both systems either, and as far as I know there were no reports of this model of HP servers with issues.
-
soke too soon, having a problem with my gpu, which went from functional to not. Log shows: May 19 13:46:23 Tower kernel: nvidia-nvlink: Unregistered the Nvlink Core, major device number 245 May 19 13:46:23 Tower kernel: nvidia-nvlink: Nvlink Core is being initialized, major device number 245 May 19 13:46:23 Tower kernel: NVRM: The NVIDIA GeForce GT 730 GPU installed in this system is May 19 13:46:23 Tower kernel: NVRM: supported through the NVIDIA 470.xx Legacy drivers. Please May 19 13:46:23 Tower kernel: NVRM: visit http://www.nvidia.com/object/unix.html for more May 19 13:46:23 Tower kernel: NVRM: information. The 510.73.05 NVIDIA driver will ignore May 19 13:46:23 Tower kernel: NVRM: this GPU. Continuing probe... May 19 13:46:23 Tower kernel: NVRM: No NVIDIA GPU found. It appears that my GPU driver was automatically updated and now I have to roll back to the 470.xx option in the Nvidia plugin. Ok I guess... a bit of an annoyance to have to fix something like this that was working just fine.
-
updated 2 machines. first one no problems. Second one had all disks in the 2 pools "missing" as the device names had changed (those using an H240). I noted the disk positions/assignments, used new config and preserved the array disks, went back to the main tab and re-assigned the pool disks, marked parity as correct, and started the array. Normal operation as expected with no loss of data (also expected).
-
First post updated with instructions for 6.10.
-
I already listed my hardware specs. So moving on: Firstly, don't write to the array. If you have to, make sure you're on reconstruct write. For cache use ssd/nvme cache disks if you want fastest performance. second, see here: Try that and see if your experience changes. *Note* I don't have this setting on anything but a fast network share. The speeds I posted yesterday are just a a basic share that uses a cache drive.
-
M1 MacBook Pro > OWC Thunderbolt Pro Doc > 10gbe ethernet cable > mikrotik 4 port 10gbe switch > direct attach copper cable > mellanox connectx-2 card > hp ml30 gen9 unraid server. file copy from the server, off a cache pool of 6 data ssd's in raid10, writing is about 100MB/s slower. Reading from my spinning array gets me about 170MB/s give or take using exos drives. Writing is a little slower. So, it works for me and my Mac. YMMV depending on server/client hardware specifics and tuning.
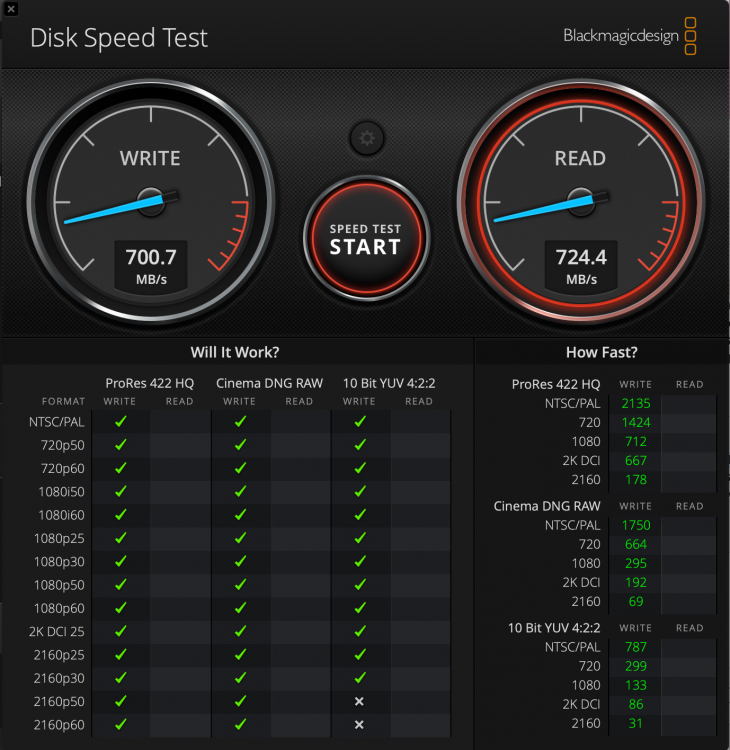

-
the very first post says "Installation (procedure used for unRaid 6.9.0 RC 2 and up to current stable versions, previous versions not supported). This thread will be updated/deprecated when 6.10 goes stable to reflect the changes with that version." The patch is a part of the OS currently in the RC versions, so technically it should work if you follow step 4 and 6 in the first post, rebooting after step 4. I sold my last proliant a year ago, and don't always run RC versions so I don't have the ability to test at the moment, hence why RC is not supported (plus things can unexpectedly change from version to version.) If you do try steps 4 and 5, kindly report back the results.










