

DZMM
-
Posts
2801 -
Joined
-
Last visited
-
Days Won
9
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by DZMM
-
-
I've just gone for beta 25 to RC1 - no lockups for 5.5hours which is promising
-
1 hour ago, sittingmongoose said:
I did post my diagnostics and enhanced syslog but I don’t see anything in there at all telling. And it’s random, it probably won’t crash overnight at all. But randomly during the day it will. I can’t even pin down a thing it’s doing to trigger it.
don’t have an option to run a remote syslog as it’s kinda remote. Nor do I even know how to do that.
I have had the same problem with all builds greater than beta25, and I've been unable to post diagnostics as my system completely freezes.
-
-
Thanks for the new beta. The write-up went right over my head as someone who's not very technical e.g. I can follow the instructions for the GPU Driver instruction section on how to configure the files...but, I don't know why I would do this or when it might be beneficial or not to do so. What does it potentially allow me to do? Thanks.
I'm keen to give this one a go as I'm still stuck on beta25 as the releases before this one, kept causing my machine to hang and lock me out.
-
11 hours ago, DZMM said:
I've had 2 lockups today on v29 which is very rare - had to use power button to shutdown as totally locked out/full crash. I'm not sure if the diags after boot will shed any light
highlander-diagnostics-20200929-2245.zip 126.35 kB · 1 download
I woke up to a unresponsive system this morning. My Windows 10 VMs were locked, but my pfsense VM I think was still running as I had Wi-Fi connectivity on other devices. I couldn't connect to unRAID though - even with my laptop via ethernet. I've had to rollback to beta25 as that's 3 lockups in 24 hours, whereas I had no issues with beta25.
Diags attached after reboot again, so not sure if they will help - I couldn't previous diags as I had to shutdown with hardware power button.
-
 1
1
-
-
I've had 2 lockups today on v29 which is very rare - had to use power button to shutdown as totally locked out/full crash. I'm not sure if the diags after boot will shed any light
-
1 hour ago, limetech said:
Correct!
Phew - I'd only just started hours of moving files off my pools when I saw this. It's probably worth adding to the main post as other people will be in the same boat i.e. luckily did this when they created new pools.
-
I have a question please about using the multiple pools.
I currently have my dockers in my appdata share /mnt/user/appdata using a pool called apps (/mnt/apps/appdata). I also have another pool called cache (/mnt/cache) that I use for most of my other shares.
I want to move some of my dockers e.g. /mnt/user/appdata/radarr to the cache pool i.e. from /mnt/apps/appdata/radarr to /mnt/cache/appdata/radarr. As long as I set the appdata share to cache only so that files never get moved to the array, is this safe?
I created a few test folders e.g. /mnt/cache/appdata/test and I can see that it was still visible at /mnt/user/appdata/test even though the appdata share is set to the /mnt/apps pool, so it seems to work i.e. even if a pool isn't setup in the GUI for a share, all files stored still bubble up to /mnt/user/sharename.
Thanks in advance.
Edit: realised a bad idea as new files will get added to /mnt/apps/appdata. I'll try a different way
-
4 hours ago, Arbadacarba said:
A possible solution... (Though I'm not running the Beta) I'm in a very similar boat... I have a gaming VM that has control over my NVIDIA GPU and while I can plug a spare monitor into the integrated Intel GPU I prefer keeping things simple.
I've assigned a static Address to my Unraid Server and when my pfSense VM fails for any reason I run the following script in Admin mode (WIndows) to temporarily set my laptops IP to a static address as well.
netsh interface ipv4 set address name="Wi-Fi 2" static 10.40.70.251 255.255.255.0 10.40.70.1
netsh interface ipv4 set dns name="Wi-Fi 2" static 10.40.70.1 8.8.2.2
Then I run a second script to change back to Dynamic after the router is back up and running:
netsh interface ipv4 set address name="Wi-Fi 2" source=dhcp
This quickly lets me diagnose any problems and get up and running asap.
I did stumble onto a similar workaround, where I set a static IP up on my laptop that I bought a few months ago, in order to access the server.
I'm loving the new pools and they are a great addition. It's particularly nice to be able to see the disk activity for drives that were previously UDs.
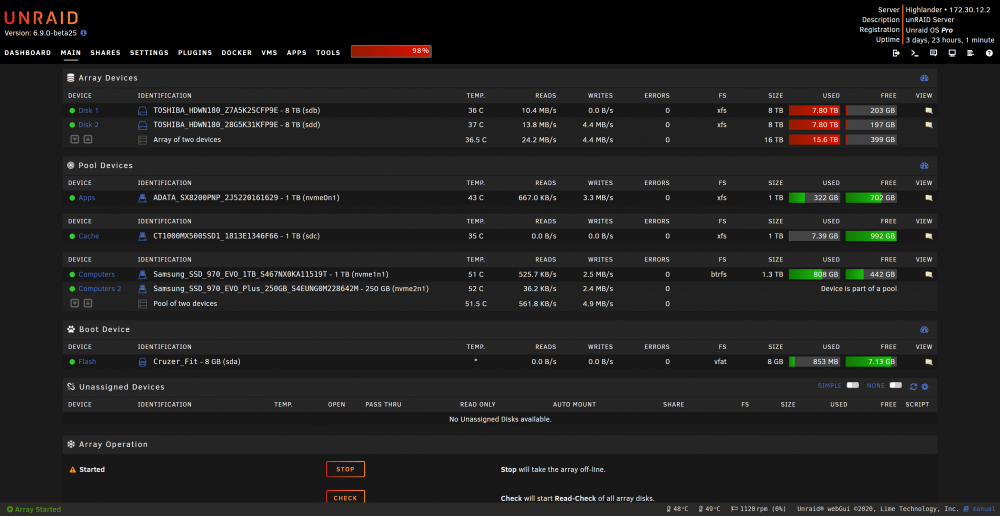
-
 1
1
-
-
Also, there's a problem with the logic on the green 'All Files protected' icon in shares.
I have two shares (domains and iso) setup as cache only that use my 'Computers' pool that is configured as a JBOD. They show up as 'protected' shares - the files aren't protected as it's a single pool.
highlander-diagnostics-20200822-1021.zip
-
New beta user. I've finished making the switch which was time consuming as I've created new pools for my appdata (mainly Plex) and VMs, which meant moving a lot of data around, formating drives etc.
It all went fairly smoothly, but there's one new addition that really didn't help me. I passthrough my primary GPU to a VM AND also run a pfSense VM. If my array doesn't start, I have to stop it, unplug the USB, undo the VFIO-bind edits so that I have a screen, and then reboot to be able to access the server, as I can't use another computer to access the server because of the VM.
In 6.9.0 it looks like if there's a unclean shutdown it turns off the disk auto start option - I'm sure this is a new feature. This means I have to go through the steps above every time which is a pain. Is it possible to make this optional or to remove as it's a real pain for people with headless servers AND a pfsense VM who can't get into the server over the LAN.
-
Changed Status to Solved
-
Ahh thanks
-
On 10/12/2019 at 9:26 PM, nuhll said:
new version of rclone plugin now supports 6.8.0-rc1
-
1
-
-
32 minutes ago, johnnie.black said:
I'm not seing the repost on the UD thread, so will comment here.
Dec 8 09:08:12 Highlander kernel: BTRFS info (device sda1): bdev /dev/sdb1 errs: wr 10554074, rd 11326465, flush 304, corrupt 81, gen 1Device sdb on this pool dropped out at some point in the past, run a scrub but IMO bad idea to use a pool of USB devices, USB is very prone to disconnects and generally bad at reporting and handling errors.
yeah, when it works it great but even 3 problems in 4 months is too much. I've decided to just get a bigger nvme drive so I can ditch the small 2x500GBs. Luckily I can return one of the SSDs and the other I'll probably just put on eBay together with my old SM961
-
1 minute ago, dlandon said:
You should close this as a bug, and post in the UD forum for some help.
Done
-
ok, thanks - I'll think I'll try and do a btrfs scrub at the next reboot
-
no worries, was just flagging in case it wasn't a known element - just a small blemish on the overall look
-
I had two variants of Disney - Disney (LEGO) and Disney_4C. When I deleted the original Disney profile, it let me delete the variants and when I re-created Disney I can now delete variants at will.
For other variants e.g. of Buzz I can't delete them - I guess I'll have to delete and re-create the original Buzz profile to fix the bug to allow me to delete the variants.
-
Yeah, parity is invalid as the cache problems @johnnie.black has been helping with have slowed down my whole array.
-
Ahh ok.
rclone is such an amazing project - I can't help thinking how much money Nick would make if he went commercial, although he's a successful businessman already I guess.
-
 1
1
-
-
ahh - thanks. I'm going to start running my commands that way - rclone usage is huge for me as I've uploaded about 80% of my library, so anything that gets closer to 'raw' performance seems a good thing
-
ok, hopefully one of the moderators will move this post
-
I've been running for 10 hours on the 6.6.0 release and I've only seen the problem twice in my logs, so I don't think (i) rclone is the source and (ii) it's not a biggie now whatever it is
Sep 21 01:08:00 Highlander nginx: 2018/09/21 01:08:00 [error] 8699#8699: *6530 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.30.10, server: , request: "GET /update.htm?cmd=/webGui/scripts/share_size&arg1=appdata&arg2=ssz1&csrf_token=50C36541BB26A4FA HTTP/2.0", upstream: "http://unix:/var/run/emhttpd.socket:/update.htm?cmd=/webGui/scripts/share_size&arg1=appdata&arg2=ssz1&csrf_token=50C36541BB26A4FA", host: "1d087a25aac48109ee9a15217a105d14c06e02a6.unraid.net", referrer: "https://1d087a25aac48109ee9a15217a105d14c06e02a6.unraid.net/Shares" Sep 21 09:02:51 Highlander nginx: 2018/09/21 09:02:51 [error] 8699#8699: *186147 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.30.10, server: , request: "POST /plugins/dynamix.docker.manager/include/Events.php HTTP/2.0", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "1d087a25aac48109ee9a15217a105d14c06e02a6.unraid.net", referrer: "https://1d087a25aac48109ee9a15217a105d14c06e02a6.unraid.net/Dashboard"highlander-diagnostics-20180921-1007.zip
@Waseh I can't find anything on the rcloneorig command - what's the difference between it and 'rclone'? Is it best to use rcloneorig? Thanks




Unraid OS version 6.10.0-rc3 available
-
-
-
-
-
in Prereleases
Posted
I'll give this a go over the weekend. I had to can rc2 immediately as my W10 VMs were very unresponsive - taking abut 20 mins just to get to the desktop. If I have the same problem this time I'll post diagnostics, which I should have done last time.