

GroxyPod
-
Posts
136 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by GroxyPod
-
You're right, my bad. 0-6 would be the correct settings.
-
Do you see any errors in the docker log after it runs? EDIT: Is the email you are specifying in the advanced config an email address associated with a plex account or separate? If separate, I think the issue has to do with not using -n as a command line switch. Can you run an emailreport test with -n -t? (this just has to do with preventing plex members from getting emailed) Sent from my iPhone using Tapatalk Pro
-
Were you expecting it to come out at the same time? Because you set it to be two hours after. Sent from my iPhone using Tapatalk Pro
-
Zero is not an acceptable number for the day of the week. EDIT: Brain fart. Sent from my iPhone using Tapatalk Pro
-
Ok. We'll take a look tonight. Thanks! Sent from my iPhone using Tapatalk Pro
-
You shouldn't need to add anything that is required in the docker template as that is written inside the docker now instead of outputting to the file. Did your NowShowing not work without adding the additional information you listed? Sent from my iPhone using Tapatalk Pro
-
 In what way would you like to limit the release info? Sent from my iPhone using Tapatalk Pro
In what way would you like to limit the release info? Sent from my iPhone using Tapatalk Pro -
unRAID OS version 6.3.3 Stable Release Available
GroxyPod replied to limetech's topic in Announcements
Installed update. No problems updating from 6.3.2 to 6.3.3 so far. -
I just updated my PlexReport docker and it populated the web_email_body.erb correctly. Running a -t test worked as well without having to re-run any setup. Not sure what the differences are as I don't see any changelog, but it looks like it might of been an issue with the new file being committed vs when the docker file was updated.
-
[-options] is not an actual option. You need to select from one of the following options (-n -l -t or -d). Options: -n, --no-plex-email - Do not send emails to Plex friends. Can be used with the recipients_email and recipients config file option to customize email recipients. -l, --add-library-names - Adding the Library name in front of the movie/tv show. To be used with custom Libraries -t, --test-email - Send email only to the Plex owner (ie yourself). For testing purposes -d, --detailed-email - Send more details in the email, such as movie ratings, actors, etc Example: To run a test, you would type: docker exec plexReport plexreport -t Example 2: To run a test with a more detailed email, you would type: docker exec plexReport plexreport -t -d
-
You'll need to modify the email_body.erb file. It's XHTML v1.0 STRICT, so you can add a href / img src tags wherever you feel the need to. You can review how it looks with a WYSIWYG HTML editor (such as dreamweaver, etc.) or run the docker using docker exec plexReport plexreport -t
-
Cannot create a Windows 10 virtual machine
GroxyPod replied to JohnSnyder's topic in General Support
I had this same issue as well with the machine being i440fx-2.7. I switched to q35-2.5 and it started working, no other modifications needed. -
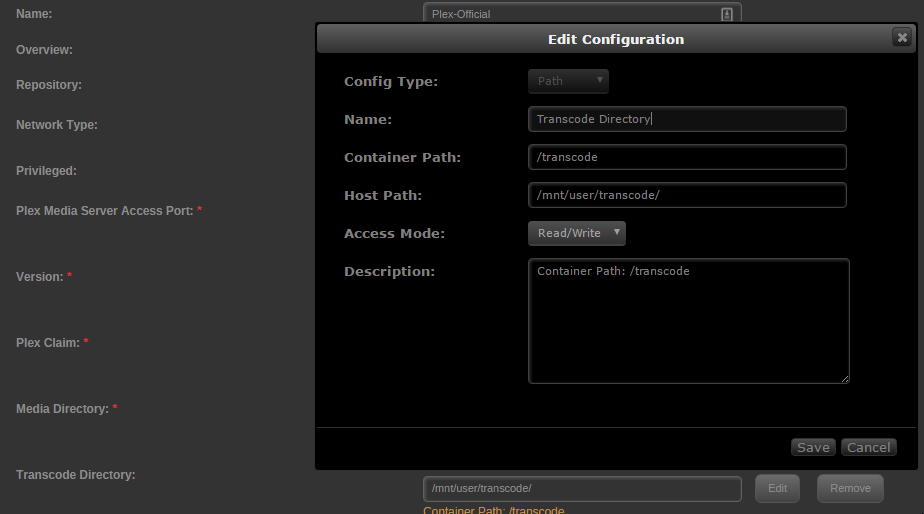
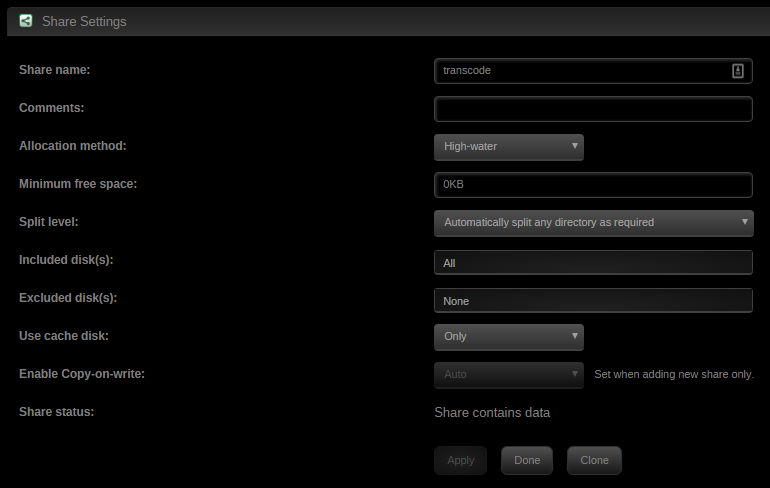
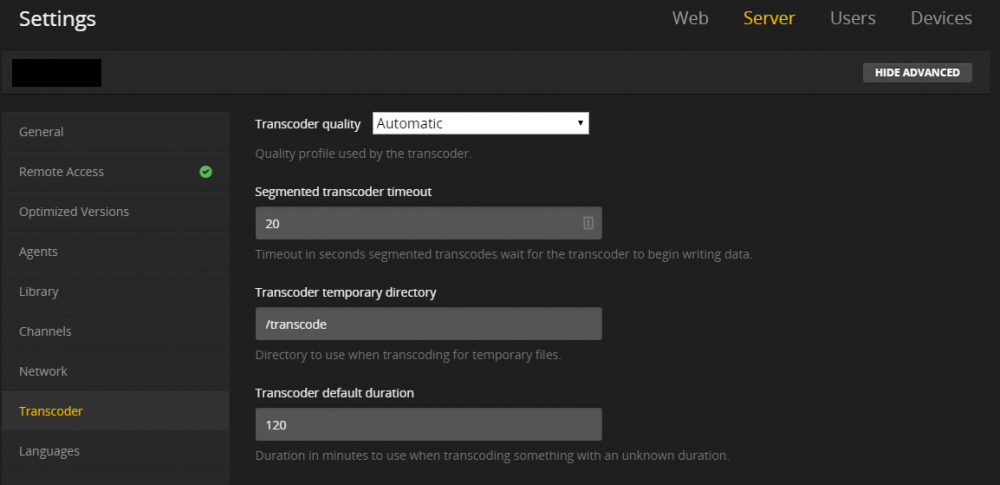
If you installed plex on to your cache drive, it should already be setup to do transcoding on that device. If you want a specific folder, you can set one up in the docker you're using and point it to the cache drive or share that is set to cache-only and then point your server transcoding directory to it. I've attached screenshots of how I have mine setup. I use a cache-only share.
-
Removing the drives off the onboard Marvell controller did the trick. No errors in 24 hours. The only issue now is my parity drive has sync errors due to the drives dropping and all my troubleshooting. Not a big deal, I can rebuild it/correct sync errors and deal with any data loss that has already occurred. I'm just happy to have working hardware! Thanks again!
-
I don't want to jump the gun too much, but I have been up for 4 1/2 hours with the Marvell ports on board removed from the equation and it seems to have helped. I'm using an external card that has a different Marvell controller to handle my cache drives atm because I'm 2 drives over what I can put on the board. I also found a forum post here: https://forums.tweaktown.com/asrock/56191-c2750d4i-marvel-9230-sata-port.html which shows some other people having very very similar error messages to what I was getting with unraid on ubuntu. That makes me feel better about the board's status to where I won't have to RMA it. Once my testing completes, I'll post an update. Thank you so much to johnnie.black and RobJ for the assistance thus far!
-
Good to know. I'll keep at it. Thanks for your help!
-
The errors happened again on the same ports: ATA7-ATA10 which are the devices plugged into the marvell controller. I have a non-marvell card coming in which has an ASM1061 chipset. According to the hardware compatibility page for unraid, this will work out of the box. Not sure if I'll encounter the same issues but it's worth a quick test until I can find an appropriate hba card. I have another card but it has a marvell chipset. Supposedly it will work out of the box according to the hardware compatibility page, so I will give it a test. Just to see if the errors only occur on the devices hooked up to it. Power supply ruled out, on to the next endeavor.
-
Sounds about right, whenever it would happen it would be ATA7-ATA10. All those are on the Marvell controller. So far the PSU swap seems to be working, I've been up on the marvell controller for about 7 hours now and haven't experienced the same issues just yet but who knows what will happen in an hour. I'm crossing my fingers it was the PSU and not the motherboard, or an incompatibility with the marvell controller cause that would SUCK lol
-
Hi RobJ, thanks for the reply! I really appreciate it. I got to the cabling conclusion from this link: https://lime-technology.com/wiki/index.php/The_Analysis_of_Drive_Issues#Drive_interface_issue_.234 since the message I was getting was very similar. I may have spun down a rabbit hole by the time I found this so I just jumped on it I'm using the SATA ports directly on the board and it is running the latest BIOS and BMC update out of the factory according to what I have compared with ASRock's website and what's on the board. Yeah, I'm working through all the possibilities. Currently I have obtained another power supply to see if the supplied power may have been flaky, then I will be trying an HBA card to test johnnie.black's recommendation.
-
Thank you, I will try that!
-
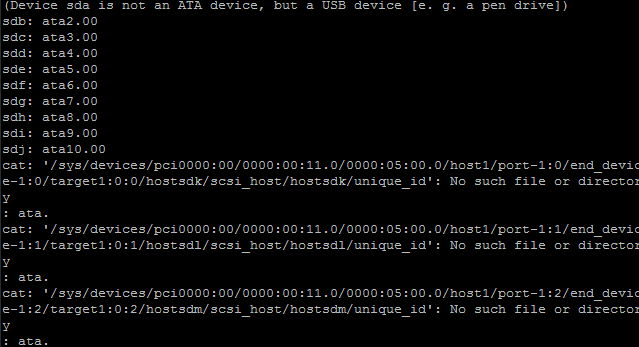
Greetings Awesome People! I have an issue that is driving me nuts to the point where I'm almost ready to office space this server. Background: I recently started having issues on my old hardware which ranged from general instability (freezing) to memory errors upon boot (which magically resolved itself after another reboot). All these issues lead me to believe the motherboard was bad since it was a refurb and I picked it up cheap. I decided to dive in with some new hardware and that leads us up to my current issue. I'm getting read errors after awhile, and it seems to change between different drives. I've tried changing sata ports, backplane channels, power cables, and even switching drives. They all come to the same outcome: read / write errors which lead to red ball. When it first happened, I checked the drive with an extended SMART test but it came back clean. No bad sectors needed to be re-allocated, no pending, nothing. Rebuilt that drive (disk 7) and thought I was done. Nope. Now other drives are giving me a shit fit. Hardware: CPUs: Dual E5-2670s Memory: 96GB Motherboard: ASRock EP2C602-4L/D16 Power Supply: EVGA SuperNOVA 850 G2 Looking at my syslog, I see: Jan 26 22:50:23 Phoenix kernel: ata10.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen Jan 26 22:50:23 Phoenix kernel: ata10.00: failed command: SMART Jan 26 22:50:23 Phoenix kernel: ata10.00: cmd b0/d0:01:00:4f:c2/00:00:00:00:00/00 tag 7 pio 512 in Jan 26 22:50:23 Phoenix kernel: res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 26 22:50:23 Phoenix kernel: ata10.00: status: { DRDY } Jan 26 22:50:23 Phoenix kernel: ata10: hard resetting link Jan 26 22:50:23 Phoenix kernel: ata10: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jan 26 22:50:23 Phoenix kernel: ata10.00: configured for UDMA/133 Jan 26 22:50:23 Phoenix kernel: ata10: EH complete Jan 26 22:50:44 Phoenix kernel: ata9.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen Jan 26 22:50:44 Phoenix kernel: ata9.00: failed command: SMART Jan 26 22:50:44 Phoenix kernel: ata9.00: cmd b0/d0:01:00:4f:c2/00:00:00:00:00/00 tag 18 pio 512 in Jan 26 22:50:44 Phoenix kernel: res 40/00:ff:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout) Jan 26 22:50:44 Phoenix kernel: ata9.00: status: { DRDY } I know the status of DRDY signals a bad cable but it seems no matter what I do, switching between sata ports, backplane locations, etc.. These errors always seem to happen after awhile. Please help! I'm losing my mind and ready to office space it. phoenix-diagnostics-20170126-2255.zip
-
According to the person who forked it, it is supposed to be a couchpotato replacement.
-
Everything is saved to the usb flash drive so it should all carry over between systems. I would recommend if you have your array set to auto-start on boot (not sure why someone would do this), to disable it. Also, take a screenshot of your current drive setup so you can compare each drive to make sure it is in the right order before starting your array. You may run into compatibility issues involving raid controllers found on enterprise servers (issues can be as simple of putting it into a JBOD mode to no direct access from within unraid to run features like smart checks or spin down, or potentially not compatible at all). Hopefully all goes well, and if it doesn't, just move everything back to the original system. Goodluck!
-
Please post the output from running the following commands via an ssh session: df -h /var/log du -sm /var/log/*
-
You're welcome. The key is just a precaution and mentioned since you asked if your usb flash drive died If you're using the same flash drive, using the link again works perfectly because it is tied to the GUID of the device. Hope everything continues to work well!







