

knutarn
-
Posts
88 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by knutarn
-
-
30 minutes ago, JorgeB said:
Because disks are overheating, if any disk is above the set warning temp when the reported is generated it fails.
hoo!
thx!

-
16 minutes ago, JorgeB said:
Improve disk cooling.
Yes
") I working on it
I working on it
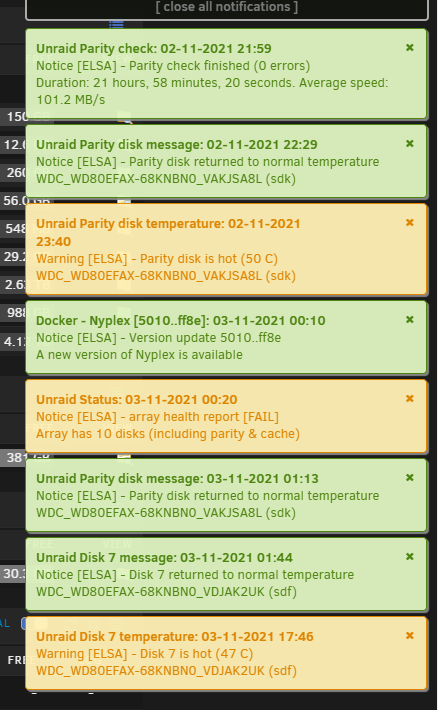
But what is my array fail?
-
Hay guys!
I get this: (fail)
What is this?
Efter I change the SSD disk too new on.
-
3 hours ago, Squid said:
Post your diagnostics
Hi!
Looks like I'm still having problems. Has removed the bad SSD disk from unraid. And set up a new vDisk and appdata storage folder on one of my file disks until I get a new SSD. But get this mld in LOG.
Oct 25 23:10:45 Elsa nginx: 2021/10/25 23:10:45 [error] 7100#7100: *169 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /update.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Settings/DockerSettings"And it takes a very long time and for example turn on/off the Docker service.
New diag file here
-
2 minutes ago, JorgeB said:
Already mentioned in your other thread that's there's a problem with the cache device, try a different one.
Yes I use normal disk right now and not the SSD But is slow like H***
I remove the SSD from the server . And it is faster
-
Oct 25 20:12:12 Elsa avahi-daemon[5765]: Joining mDNS multicast group on interface docker0.IPv6 with address fe80::42:b2ff:feca:b773. Oct 25 20:12:12 Elsa avahi-daemon[5765]: New relevant interface docker0.IPv6 for mDNS. Oct 25 20:12:12 Elsa avahi-daemon[5765]: Registering new address record for fe80::42:b2ff:feca:b773 on docker0.*. Oct 25 20:13:24 Elsa kernel: print_req_error: 2 callbacks suppressed Oct 25 20:13:24 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Oct 25 20:13:34 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:13:44 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:13:54 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:04 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:09 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 32598576 op 0x1:(WRITE) flags 0x100000 phys_seg 1 prio class 0 Oct 25 20:14:15 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:25 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:27 Elsa kernel: vethd6499df: renamed from eth0 Oct 25 20:14:27 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:35 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:45 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 Oct 25 20:14:46 Elsa ntpd[2033]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized Oct 25 20:14:55 Elsa avahi-daemon[5765]: Interface veth844bb46.IPv6 no longer relevant for mDNS. Oct 25 20:14:55 Elsa avahi-daemon[5765]: Leaving mDNS multicast group on interface veth844bb46.IPv6 with address fe80::4c7d:1cff:fefe:5e55. Oct 25 20:14:55 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:55 Elsa kernel: device veth844bb46 left promiscuous mode Oct 25 20:14:55 Elsa kernel: docker0: port 1(veth844bb46) entered disabled state Oct 25 20:14:55 Elsa avahi-daemon[5765]: Withdrawing address record for fe80::4c7d:1cff:fefe:5e55 on veth844bb46. Oct 25 20:14:56 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 570558528 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0 -
4 minutes ago, Squid said:
Post your diagnostics
Here it is
I have just downgrader OS and rebootet
(for test)
-
Hey!
I just make a new unraid docker image. And it slowe like a ****
Dont now what is wrong.
This is from Log
Oct 25 19:29:30 Elsa nginx: 2021/10/25 19:29:30 [error] 6817#6817: *22324 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /update.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Settings/DockerSettings"And when i add container.
Oct 25 19:40:07 Elsa nginx: 2021/10/25 19:40:07 [error] 6817#6817: *24741 upstream timed out (110: Connection timed out) while reading upstream, client: 192.168.1.76, server: , request: "POST /Docker/AddContainer?xmlTemplate=user%3A%2Fboot%2Fconfig%2Fplugins%2FdockerMan%2Ftemplates-user%2Fmy-binhex-krusader.xml&rmTemplate= HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "192.168.1.30", referrer: "http://192.168.1.30/Docker/AddContainer?xmlTemplate=user%3A%2Fboot%2Fconfig%2Fplugins%2FdockerMan%2Ftemplates-user%2Fmy-binhex-krusader.xml&rmTemplate="I just make a new docker on my disk and not SSD
Reff:
-
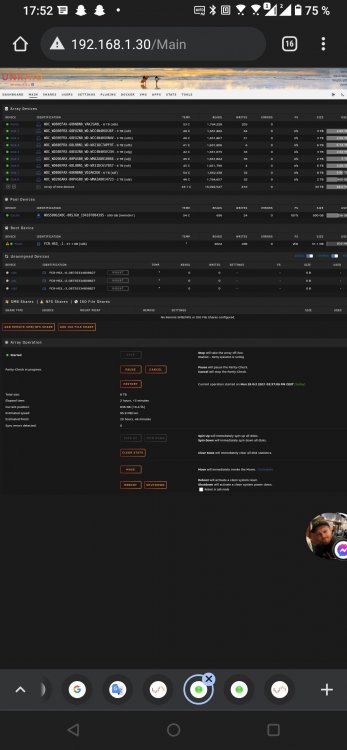
21 minutes ago, JorgeB said:
Problem with the NVMe cache device:
Oct 25 15:36:50 Elsa kernel: blk_update_request: critical medium error, dev nvme0n1, sector 327930968 op 0x1:(WRITE) flags 0x8800 phys_seg 1 prio class 0This is not a software issue.
Ho.
What this means ? I can enter the ssd **
Is broken ?
-
Hey:)
After I had to kill Windows VM (when it was stuck) I could not turn it on again. I try and restart the server. Then suddenly all the VMs were gone and Docker service will not start. (Docker Service failed to start.)
What happened here ?

-
8 minutes ago, saarg said:
Isn't that obvious? You do want the Nvidia build, right?
Yes, but not 100% shore. Wil not fuck my unraid server up

-
19 minutes ago, david279 said:
Update thru the plug-in page not TOOLS.
Ok thx!
On this: Nvidia Unraid Builds: or this: Stock Unraid Builds:
-
Hey!
Going to update the Unraid OS to 6.8.3.
How do I do this right? Should I upgrade the OS from TOOLS. So add new driver in navidia plugin?
-
Just now, Squid said:
Switch where it says Upon Host Shutdown to be Hibernate, and on the VFIO ISO disk that appears in Windows you need to install the Client Tools.
Thx, I wil try this
-
4 hours ago, Squid said:
Are you trying to do what I'm suggesting, because you keep quoting me, but your posting implies that you're attempting to work with @jonathanm Very confusing on my part
For the immediate question, have you clicked the link there yet? It'll take you directly to where you need to be.
If you're attempting to do what I'm suggesting, then you've completely missed the point of what I'm suggesting. If you're attempting to do what @jonathanm is suggesting, then stop quoting me...
Hello again. I misunderstood I then, thought that's what you meant. My English is not as good as it should be.
How I can do this: "set unRaid to hibernate the VMs when it shuts itself down." Any guide on this here?
-
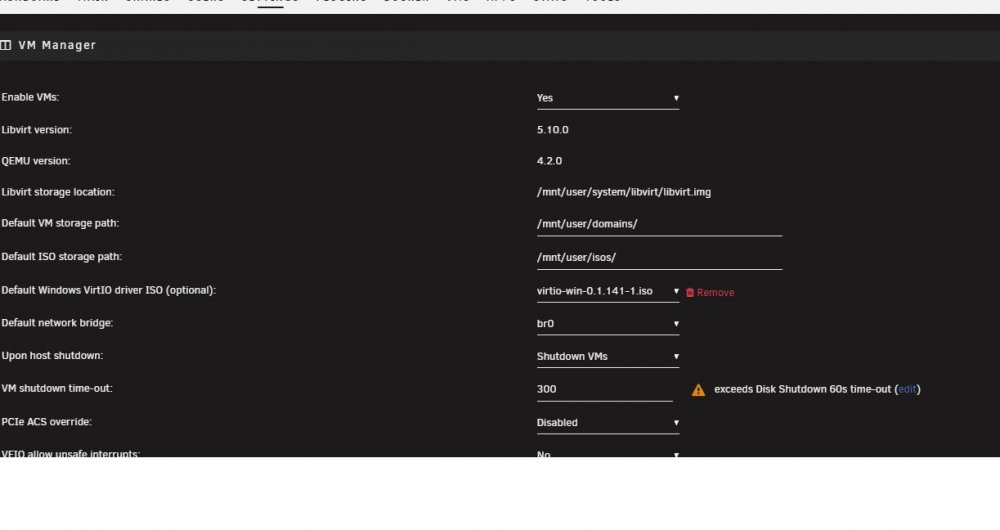
8 hours ago, Squid said:
Since you quoted me, if you hibernate shutdown time isnt a problem
I change to 300. But what is? "exceeds Disk Shutdown 60s time-out (edit)" ? What do i change here?
-
13 hours ago, trurl said:
Did you disable the Docker and VM Services? Not the individual dockers and VMs but the services in Settings - Docker and Settings - VM Manager
hoo no
-
52 minutes ago, Squid said:
Caveat: You're running windows, and there's a million reasons why Windows won't shutdown (open dialog window or a document needs to be saved), or will automatically install updates when shutting down. And then unRaid will basically yank the power from the VM if it excedes it's timer to shutdown (I believe the default it allows a VM to shutdown gracefully is 60seconds)
Easier solution is to forget about installing apcupsd on the VM, and rather install the VM client tools that's on the virtio iso, and then set unRaid to hibernate the VMs when it shuts itself down.
Yes, I drive HS3 and this app is very slow to shutdown. So i need more time for VM to shutdown. or my DB be lost.
How do I can get more time for VM to shutdown? Or wait to it shutdowan or if time get over 5-10 min, it can kill the VM for shutdown the unraid server
-
17 minutes ago, jonathanm said:
Set Unraid to shutdown after 5 minutes (300 seconds) on battery, set the VM to shutdown after 4 minutes (TIMEOUT 240) on battery.
You want your system completely shut down as soon as it is clear the power is not coming back, typically if the power is out more than 1 minute, it's going to be out WAY longer than your UPS can handle. The last thing you want is to drain the batteries, you want to reserve as much battery as possible.
Thx!
How do I " set the VM to shutdown after 4 minutes (TIMEOUT 240) on battery." ? Cant find any settings on this program for it, just info fraom UPS:/
-
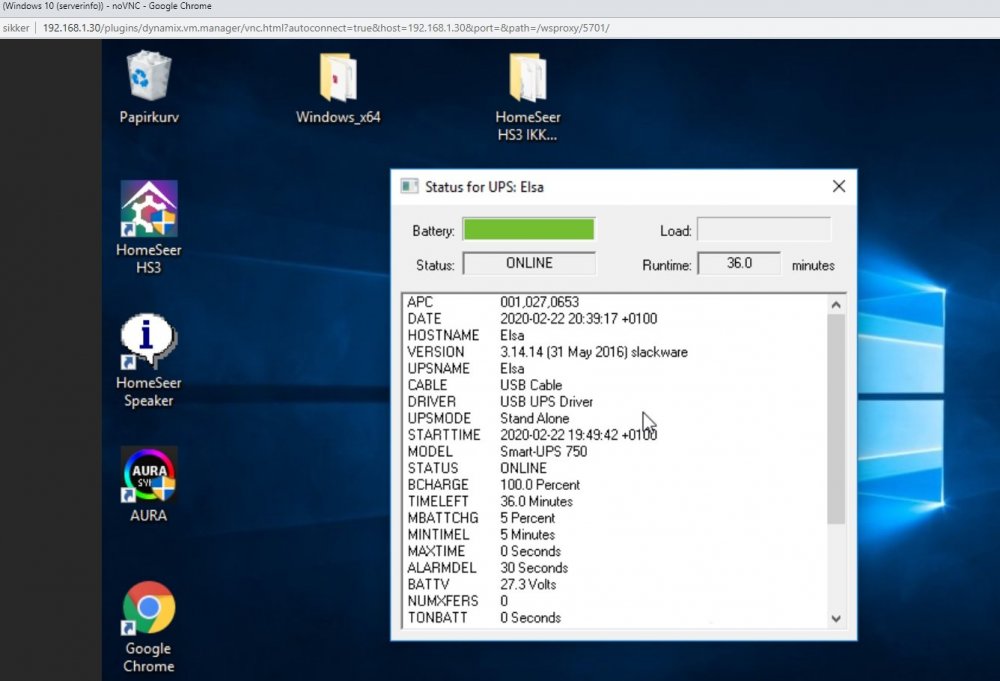
Hey!
apcupsd get info from unraid ups: (look in picture) (Use my network ip)
But how I get det VM to shutdown 1 min befor unraid do it?
-
16 minutes ago, trurl said:
appdata, domains, and system are normally kept on cache so your docker and VM performance won't be impacted by the slower parity writes on the array, and so your dockers and VMs won't keep array disks spinning.
Of these 3 shares, I would say system is the most important to keep on cache, because it is always in use if you have Docker and/or VM Services enabled.
You will have to disable Docker and VM Services since Mover can't move open files, then set system share to cache-prefer and run Mover to get it moved to cache where it belongs.
You can check how much of which disks each of your Shares are using by using the Compute All button on the Shares page.
Get this:
Feb 22 17:27:48 Elsa root: mover: started Feb 22 17:27:48 Elsa move: move: skip /mnt/disk1/system/docker/docker.img Feb 22 17:27:48 Elsa shfs: set_nocow path: /mnt/cache/system Feb 22 17:27:48 Elsa move: move: skip /mnt/disk1/system/libvirt/libvirt.img Feb 22 17:27:48 Elsa root: find: 'system': No such file or directory Feb 22 17:27:48 Elsa root: mover: finished -
2 minutes ago, trurl said:
appdata, domains, and system are normally kept on cache so your docker and VM performance won't be impacted by the slower parity writes on the array, and so your dockers and VMs won't keep array disks spinning.
Of these 3 shares, I would say system is the most important to keep on cache, because it is always in use if you have Docker and/or VM Services enabled.
You will have to disable Docker and VM Services since Mover can't move open files, then set system share to cache-prefer and run Mover to get it moved to cache where it belongs.
You can check how much of which disks each of your Shares are using by using the Compute All button on the Shares page.
Hooo thx!
-
3 minutes ago, trurl said:
Why is your system share on disk1?
Dont now
I am new on this XD
Shuld I ??
-
Now its gone. and the plex work norm again





Does anyone have a way to automatically move the X number of most commonly used files back to the cache?
in Lounge
Posted
Any new on this? I like to love to have feks plex move a movie on SSD and move it back when it no aktiv on 1 week")

So if the are new movie when many ppl look on, so its on the SSD