
wayner
-
Posts
536 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by wayner
-
-
To answer my own question here, in case anyone else comes across this:
Stop the array.
Go to unRAID settings, Network Settings and change Bridging to Yes.
In your Win11 VM setup change the network source to br0.
When you restart you should be on your LAN..
-
I have a 192.168.1.X subnetwork on my LAN. I installed a Win11 VM on my unRAID server and it has an IP address of 192.168.122.43. This Win VM can see my LAN, as in I can ping 192.168.1.1, etc. But other devices on my LAN cannot see the Win VM at 192.168.122.43. How do I fix this as I would like to use RDP to connect to the VM rather than VNC.
-
Since no one gave me any advice, I used mover to move all files back to the array again. I erased the drive. Then I changed the RAID type to mirror and restarted the array and used mover to move the system and appdata shares back to the cache.
So I am now working properly with a mirrored two disk ZFS cache pool.
-
Thanks, I deleted the files on the destination disk and mover did move them.
But isn't this error message incorrect? The file that exists which is causing a problem is the file on the destination disk, not the file on the source disk. Should I file a bug report?
-
I have had one 500GB NVME SSD as my cache disk and I am moving to 2x500GB disks for my cache pool. I did this a few minutes ago and have set it up as a ZFS drive. It defaulted to RAID0 and it shows a size of 922GB for the cache pool. I am guessing that is wrong as I should only have about 500GB available, is that not right?
What settings should I have? I am guessing that it should be RAID 1, correct?
And what about compression? I have a pretty fast CPU (core i5-11400), so I want compression On, do I not?
What about Autotrim and enable user share assignment? What should they be set to? Both drives are NVME SSDs.
And what do I have to do to change the RAID setting from 1 to 0 if that is the correct course of action? Move all files off of the disk with Mover? Then do I have to Erase the drive or do something else to change that setting? And what do I have to change, if anything, in the settings for the second cache drive?
-
For a bit more info, on my array disk3 there is a system directory that contains a libvirt.img and docker.img files. They are dated Nov 26. The libvirt.img and docker.img on my cache drive are date today, Dec 2.
Is this error message correct? Why is the error "/mnt/cache_nvme/system/libvirt/libvirt.img File exists" rather than "/mnt/disk3/system/libvirt/libvirt.img File exists", assuming that this is the problem?
-
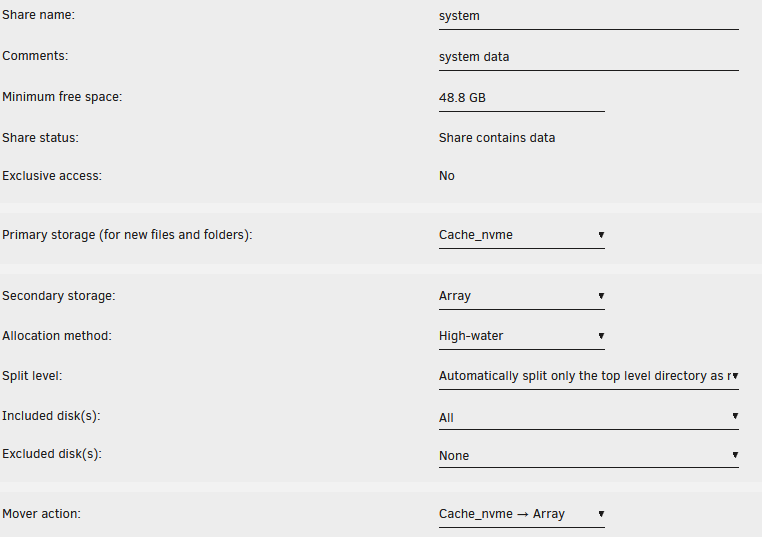
I am trying to reformat my cache drive, so I need to move all files from my cache to my array. The only directories that were on the cache driver were appdata and system. I disabled VMs and Dockers. Both the system and appdata shares have cache as the primary drive and the Array as the secondary drive. I switched mover to go from Cache->Array for both. All of the appdata files were moved. But mover is complaining that libvirt.img and docker.img already exist.
Here is the output from my log. What is going on and how do I fix this?
Dec 2 11:54:48 Portrush move: mover: started Dec 2 11:54:48 Portrush move: file: /mnt/cache_nvme/system/docker/docker.img Dec 2 11:54:48 Portrush move: move_object: /mnt/cache_nvme/system/docker/docker.img File exists Dec 2 11:54:48 Portrush move: file: /mnt/cache_nvme/system/libvirt/libvirt.img Dec 2 11:54:48 Portrush move: move_object: /mnt/cache_nvme/system/libvirt/libvirt.img File exists Dec 2 11:54:48 Portrush move: mover: finishedAnd here are the settings for the system share:
-
-
What do you mean by update paths? Would I have to use a new pool name for the new cache disk, like NewCache, and make the new NVME disk part of this pool? And then add the old cache disk to this pool and delete the old pool? Is that what you mean?
And would I then have to update the path for every docker, or just the Docker Config for the server?
-
I have added a disk to my system. Right now the disk shows up under Disk Devices. This will eventually be used as a mirrored cache drive so I want to format it to ZFS. When I go to format the disk after I select the format it says "Enter the pool name for this device. This will also be the mountpoint for the disk". What do I use for pool name when I don't really want it added to any pool?
I just want to format the drive and copy over all of the content from my cache drive for now. Do I just set any pool name?
-
My system right now has an NVME drive used as a single cache 500GB drive that is formatted as XFS. When I switched from 6.11.5 to 6.12.4 I had BTRFS corruption problems so I reformatted as XFS. To protect my cache I want to add a second cache drive that would be mirrored. I added a second 500GB NVME drive to the system but right now it is not yet formatted and shows up in unRAID under Disk Devices.
My understanding is that the disk has to be formatted as BTRFS or ZFS to be able to mirror the drive, at least as a cache drive. Is that correct? If so then I want to use ZFS due to my prior issues with BTRFS. I am pretty sure that ZFS can be used in this way but the unRAID docs don't appear to be updated to reflect this.
If so then what is the best way to move to a dual cache config? Can I format my new NVME drive as a ZFS, stop the docker service and VM service and manually copy all of the files from the existing cache drive to this unassigned ZFS drive, and then make this the cache drive? And then once I am sure that this is working then reformat the old cache drive to ZFS, increase the number of cache slots to two, and add this to the second slot cache drive? Would that be the easiest way? This way I only have to copy the files on the cache data once.
Or is it better to just stop docker+VM, copy everything from the cache drive to the pools using mover and then create my two new cache drives formatted as ZFS and use mover to move everything back?
-
I deleted the docker and reinstalled it and that worked. Someone else earlier in the thread suggested this. But it doesn't seem like a great option.
-
My user shares all have drwxrwxrwx when I do a ls -l from a root ssh session.
drwxrwxrwx 1 nobody users 4096 Nov 6 08:28 appdata/ drwxrwxrwx 1 nobody users 21 Nov 11 18:51 data/ drwxrwxrwx 1 nobody users 25 Sep 12 18:19 domains/ drwxrwxrwx 1 nobody users 6 Dec 27 2021 downloads/ drwxrwxrwx 1 nobody users 78 Sep 13 22:51 isos/ drwxrwxrwx 1 nobody users 135 Jan 24 2022 media/ drwxrwxrwx 1 nobody users 35 Sep 8 18:01 system/In an Ubuntu VM I create a director at /mnt called portrush_data. Then I mount with:
sudo mount -t cifs -o username=user,password=pass //192.168.1.254/data /mnt/portrush_dataI am able to read but the shares in the folder all have permissions drwxr-xr-x and I can't write to any directories. How do I fix this?
-
I have posted this issue in the support thread for this docker, but others have posted about this issue and it has not been answered.
I am getting errors when writing to files in appdata on a newly created docker - this is the MQTT docker.
1699286534: Error saving in-memory database, unable to open /config/data/mosquitto.db.new for writing. 1699286534: Error: Permission denied.I believe this directory is appdata/MQTT/data. How do I fix this?
Here are the permissions for the main appdata directory plus the child directories
drw-rw-rw- 1 nobody users 177 Nov 6 08:28 MQTT/ ls -l for /mnt/user/appdata/MQTT drw-rw-rw- 1 root root 20 Nov 6 08:28 ca_certificates/ -rw-rw-rw- 1 root root 793 Nov 6 08:28 passwords.README -rw-rw-rw- 1 root root 794 Nov 6 08:28 mosquitto.conf drw-rw-rw- 1 root root 20 Nov 6 08:28 conf.d/ drw-rw-rw- 1 root root 20 Nov 6 08:28 certs/ drw-rw-rw- 1 root root 27 Nov 6 08:28 log/ drw-rw-rw- 1 root root 6 Nov 6 08:28 data/ -rw-rw-rw- 1 root root 0 Nov 6 08:28 passwords.mqtt -rw-rw-rw- 1 root root 794 Nov 6 08:28 mosquitto.conf.example -
I installed this docker and I keep getting permission errors:
Error saving in-memory database, unable to open /config/data/mosquitto.db.new for writing.
The appdata folder seems to have different permissions than most of my other appdata folders:
drw-rw-rw- 1 nobody users 177 Nov 6 08:28 MQTT/
And here is what is inside of appdata/MQTT:
drw-rw-rw- 1 root root 20 Nov 6 08:28 ca_certificates/ -rw-rw-rw- 1 root root 793 Nov 6 08:28 passwords.README -rw-rw-rw- 1 root root 794 Nov 6 08:28 mosquitto.conf drw-rw-rw- 1 root root 20 Nov 6 08:28 conf.d/ drw-rw-rw- 1 root root 20 Nov 6 08:28 certs/ drw-rw-rw- 1 root root 27 Nov 6 08:28 log/ drw-rw-rw- 1 root root 6 Nov 6 08:28 data/ -rw-rw-rw- 1 root root 0 Nov 6 08:28 passwords.mqtt -rw-rw-rw- 1 root root 794 Nov 6 08:28 mosquitto.conf.exampleShould root be the owner of all of these?
How do I fix these? Do I need to change the permissions?
-
Thanks for the info
-
Just starting using TasmoAdmin, and a couple of questions. When I change the name of my device does it just change the device name displayed in TasmoAdmin, or does it also change the name on the device? Or something else.
I don't know if you maintain the code for this, but the Autoscan for me only had a 50% hit rate. I currently have 4 devices and it only found 2. The other 2 I was able to add manually.
Can I suggest that you pull down the name of the device from Tasmota, as in S31, Basic R2 or whatever. Why not show this in the device list?
-
I am trying to use this docker and when I try to encode a file I get
Destination: /storage/videos/temp
Can not read or write the directory
There seems to be a permissioning issue. The permissions to the folder are the following (I got this from an ssh session from root and going to /mnt/user/media/videos. Note that I get the same error when trying to use handbrake_recodes as the destination.
drwxrwxrwx 1 nobody users 4096 Jun 30 19:28 handbrake_recodes/
drwxrwxrwx 1 nobody users 6 Jan 24 2022 handbrake_watch/
drwxrwxrwx 1 wayne users 48 Nov 4 13:44 temp/In the logs I also get a message that doesn't make sense as this folder does exist.
[autovideoconverter] ERROR: Cannot process watch folder '/watch', because the associated output directory '/mnt/user/media/videos/handbrake_recodes/' doesn't exist.
Or am I mapping something wrong in the docker setup for the folders?
-
3 hours ago, PeteAsking said:
Its more complex to setup and requires 2 docker containers running and communicating with each other. So generally as complexity increases there is more that can go wrong and lower reliability is expected. Also nobody has started looking at how to migrate to it but you could take a look and tell us if its super easy.
Thanks, that makes a ton of sense. I would be worried that with two separate dockers that you would update the mongodb docker and the version would no longer work with the Unfi Network Appliance version.
-
Yah - shouldn't that be linked to, in post 1 of this thread? Is there a separate thread for the UNA docker, or will this thread by repurposed?
-
Maybe I am being paranoid but the end of this docker is a big deal and should be getting more attention. Shouldn't the first post in this thread be pointing out that this is about to be deprecated and don't install Unifi-Controller, install Unifi-Network-Application?
This thread is 54 pages, has posts from many users, so presumably there are a lot of users of this container. So far no one seems to know or care that they are going to have to migrate to a new docker, and install a mongodb docker as well.
Or am I way offbase here?
-
 1
1
-
 1
1
-
-
On 10/20/2023 at 1:25 PM, PeteAsking said:
I think you have to just setup 2 new containers (one for the unifi and one separate mongodb container).
What I would do is change the default management port on the existing one and then try get the new 2 containers working together and when they are working then doing a backup from the old on and shut it down, and then import to the new one. Sounds like a lot of boring effort.
Seems like a pain to now have two different dockers, as we now have to worry not only about a stable version of Unifi, but whether it works with the version of mongodb. (edit - and do we now run the risk of an update of the mongodb container screwing up our Unifi container?)
Do you have to then adopt from the new container? Or is that not necessary if you do a backup and restore?
-
I took a quick look at the docs and there doesn't seem to be a very clear description of how you migrate from the Unifi Controller docker to the Unifi Network Application container.
What do they mean by "a clean /config mount"? Does that mean a new appdata location? Or does it mean something else?And the mongo setup instructions are confusing to me. If we are migrating do we have to do this step?
QuoteMigration From Unifi-Controller
If you were using the mongoless tag for the Unifi Controller container, you can switch directly to the Unifi Network Application container without needing to perform any migration steps.
You cannot perform an in-place upgrade from an existing Unifi-Controller container, you must run a backup and then a restore.
The simplest migration approach is to take a full backup of your existing install, including history, from the Unifi-Controller web UI, then shut down the old container.
You can then start up the new container with a clean /config mount (and a database container configured), and perform a restore using the setup wizard.
-
To be honest when you have a cache setting of no or prefer (using the old unRAID terminology) then you are pretty much right, it isn't actually a cache. With prefer it would never get moved over to the pool, unless you run out of space on the primary cache drive.



Out of shared memory errors
in General Support
Posted
These errors have reappeared on my system after a few months without them.
Yesterday I switched my cache disk from XFS to ZFS and added a second cache drive to the pool in mirrored mode, and I added a Win11VM. Overnight I started getting these errors again - my log has hundreds or thousands of these entries. Any idea what is causing these? I saw a theory in the past that keeping a web browser tab to your server is a potential issue. This is a snippet of my log:
Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 309. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132809 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/parity?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /parity Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 234. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132810 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/paritymonitor?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /paritymonitor Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 237. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132811 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/fsState?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /fsState Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 234. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132812 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/mymonitor?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /mymonitor Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 3688. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132813 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/var?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /var Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 14281. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132814 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /disks Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [crit] 3106#3106: ngx_slab_alloc() failed: no memory Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: shpool alloc failed Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: nchan: Out of shared memory while allocating message of size 316. Increase nchan_max_reserved_memory. Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: *3132816 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/wireguard?buffer_length=1 HTTP/1.1", host: "localhost" Dec 3 05:15:36 Portrush nginx: 2023/12/03 05:15:36 [error] 3106#3106: MEMSTORE:00: can't create shared message for channel /wireguard