

giantkingsquid
-
Posts
52 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by giantkingsquid
-
-
Hi everyone,
I did some searching the forums and reading the help files on the UI and can't find a reason for this behaviour on my array. Basically, Disk 1 is going to fill up while there is a lot of room left on the other two disks. See below for how my array is set up:
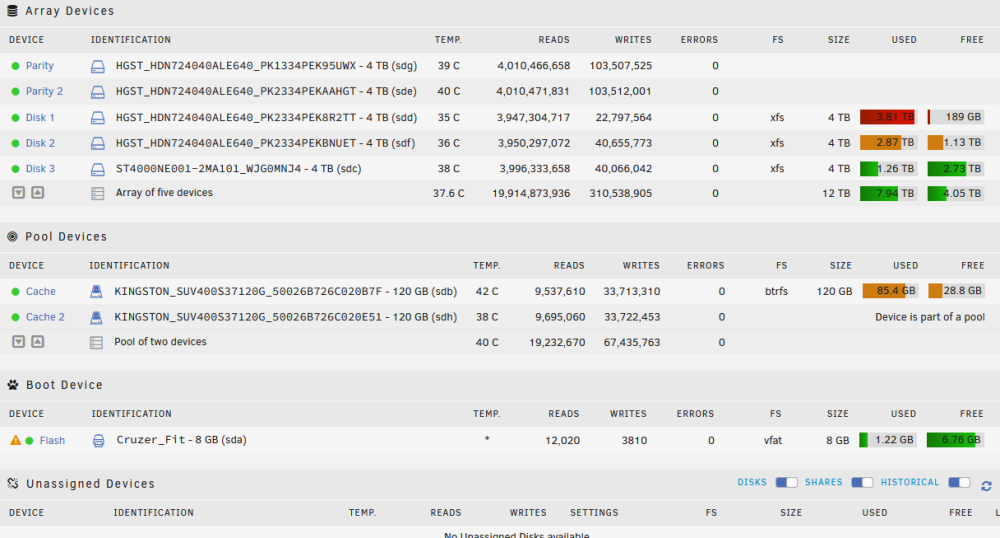
Now I have had this array going since 2017, so I haven't been in an fiddled share settings for five or six years, but from my reading of the share settings the data should be getting written to disk 3 in preference to disk 1 and 2 (Disk 3 is the only one with space above the high water mark). All of my shares are set up along these lines:
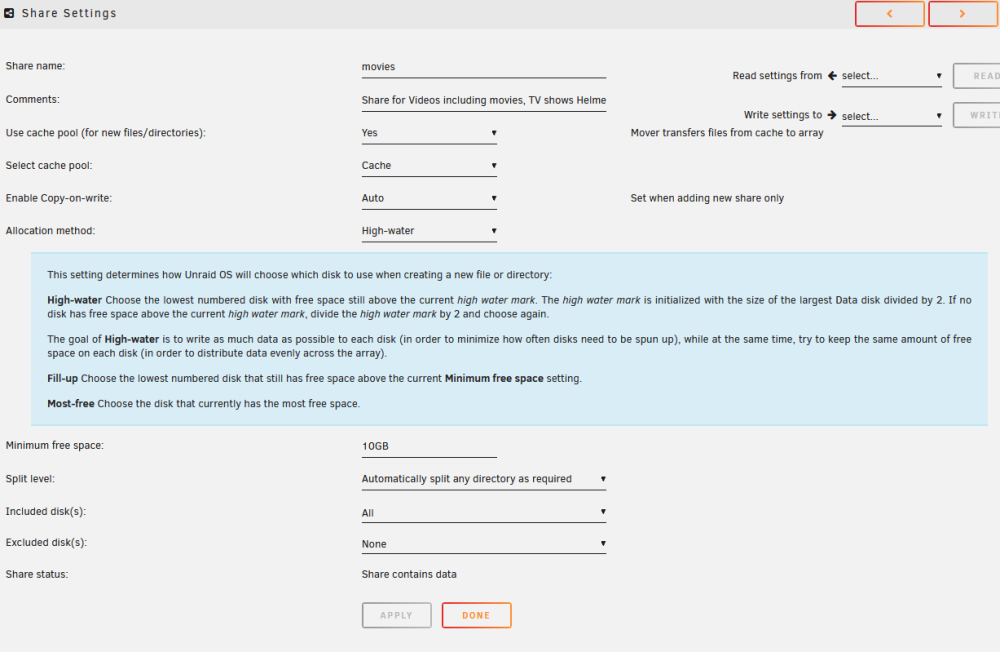
I have double checked and no shares are forcing the use of Disk 1.
Thanks very much,
Tom
-
Thanks for the suggestions. I ended up hosting it directly rather than in a VM, and it seems happy there.
Cheers.
-
11 minutes ago, dmacias said:1 hour ago, giantkingsquid said:Hi can I please request mysqldump-secure? I’d like to use it to pull database dumps from a remote server back to the array.
https://github.com/cytopia/mysqldump-secure/blob/master/README.md
thanks,
tomThis looks to just be some scripts
Oh ok, I thought it was neatly packaged up as a stand-alone as you can get it as a port or pkg for FreeBSD.
What I really want is plain old mysqldump but I’m not sure if it’s available without the entire database.
-
Hi can I please request mysqldump-secure? I’d like to use it to pull database dumps from a remote server back to the array.
https://github.com/cytopia/mysqldump-secure/blob/master/README.md
thanks,
tom
-
Has anyone managed to get this working through a Nginx reverse proxy?
I've tried two methods based on setups I've used successfully for other containers with no luck.
#Lychee proxy attempt #1 location /lychee/ { proxy_pass http://192.168.178.25:8082; add_header X-Frame-Options SAMEORIGIN; proxy_set_header Host $host; proxy_set_header X-Forwarded-Host $server_name; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Ssl on; proxy_set_header X-Forwarded-Proto $scheme; proxy_read_timeout 90; proxy_redirect http://192.168.178.25:8082 https://$host; }This first method results in the formatting looking all wrong. I'm guessing the CSS is not making it through. See Capture.PNG.
The second method:
#Lychee proxy attempt #2 location /lychee { proxy_pass http://192.168.178.25:8082/; proxy_set_header X-Lychee-Base "/lychee/"; add_header X-Frame-Options SAMEORIGIN; }This method results in what looks like the right format but no site. See Capture2.PNG.
Any ideas on this please?
Thanks,
Tom

-
On 6/26/2019 at 10:44 PM, aptalca said:
Switch to bridge networking and some other changes.
See the GitHub or docker hub pages for specific info (links on the first page)
Thanks very much, got around to making the changes and all is working well. Thanks again.
-
Hi All,
I've had this docker working fine for a few years now and it seems to have stopped working, presumably since upgrading to 6.7.
I can access the web ui, but cannot start the server. I get the following error in the web ui:
Quoteservice failed to start due to unresolved dependencies: set(['user'])
service failed to start due to unresolved dependencies: set(['iptables_openvpn'])
Service deferred error: IPTablesServiceBase: failed to run iptables-restore [status=2]: ['iptables-restore v1.6.0: Bad IP address ""', '', 'Error occurred at line: 143', "Try `iptables-restore -h' or 'iptables-restore --help' for more information."]: internet/defer:653,sagent/ipts:134,sagent/ipts:51,util/daemon:28,util/daemon:69,application/app:384,scripts/_twistd_unix:258,application/app:396,application/app:311,internet/base:1243,internet/base:1255,internet/epollreactor:235,python/log:103,python/log:86,python/context:122,python/context:85,internet/posixbase:627,internet/posixbase:252,internet/abstract:313,internet/process:312,internet/process:973,internet/process:985,internet/process:350,internet/_baseprocess:52,internet/process:987,internet/_baseprocess:64,svc/pp:142,svc/svcnotify:32,internet/defer:459,internet/defer:567,internet/defer:653,sagent/ipts:134,sagent/ipts:51,util/error:66,util/error:47
service failed to start due to unresolved dependencies: set(['user', 'iptables_live', 'iptables_openvpn'])
service failed to start due to unresolved dependencies: set(['iptables_live', 'iptables_openvpn'])
Has anyone got any ideas for that? I've read the last few pages of this thread but couldn't see anything relevent.
Cheers,
Tom
-
On 6/26/2018 at 9:35 PM, Djoss said:
So from what I understand the original issue is that some files fail to be backup? And no errors in the log files?
Yes that's right, and the files that fail to back up seem to vary each time. There are some logs, but not great.
Here are some of them. I believe that the 2nd and 3rd have been solved. The illegal symbol was some OS X metadata that I have since excluded, the permissions issue was fixed by changing the backup destination to root:root. The top one still has them stumped. Are they on the right track with their blaming of the fuse.shfs? Or is it something simple I wonder?
Thanks,
Tom
2018-06-14 18:03:40,919441 [ERROR]: [ CBB ] [ 4 ] Backup error: /storage/appdata/couchpotato/data/cache/python/bb056859be5dab3d6d2620d739c6fea0 message: Error on create destination path code: 22018-06-12 18:56:28,940418 [ERROR]: [ CBB ] [ 4 ] Ignoring file: " /storage/documents/Wedding/Icon " file contain illegal symbol!2018-06-09 05:51:03,762566 [ERROR]: [ CBC ] [ 8 ] Error open destination file data, to append data path: /localbackup/CBB_Apollo/storage/windows_backups/thoma/DIONYSUS/Data/C/Users/thoma/Downloads/signal-desktop-win-1.9.0 (2018_05_10 07_41_41 UTC).exe:/20180510072718/signal-desktop-win-1.9.0 (2018_05_10 07_41_41 UTC).exe message: Permission denied -
Hi,
I've been persisting with this for a while now and I still cannot get a full backup to complete. I've been dealing with Cloudberry support but they seem fairly confused as well. This is my latest response from them. What do you think?
QuoteHello giantkingsquid,My apologies for the delayed response.Looks like a floating error since the test backup was successful.Due to the fact there is no good error text, it complicates troubleshooting.We suppose it is caused by the fact you used fuse.shfs to mount the host directory for storage. Is this how it is organized by default in the container?Anyway, I have to ask you to re-mount the host dir using a true sshfs (as per this howto):- sudo apt-get update; sudo apt-get install sshfs- sudo echo "sshfs#[email protected]:/mnt/user /storage" >> /etc/fstabPlease make sure to replace the xxx-es with the host IP/nameEven if the issue persists after this, it will most likely provide us a better error text.If the issue re-occurs after that, please do the following:- send the latest logs referring to this ticket #84106- send us these files from both the host and the container:1) /var/log/dmesg2) /var/log/dmesg.03) /var/log/syslog4) /var/log/syslog.1Thanks in advance.Looking forward to hearing from you.The test backup they're referring to was when they asked me to backup one file only that had failed when the full plan was run.
The host directory for storage is a USB3 drive through Unassigned devices, I have it available to this docker with the rw slave option.
Things I've tried so far:
Changed path to external drive from rw to rw slave. This seemed to increase the speed of the backup drastically.
Changed permissions of storage directory to root:root. The Cloudberry processes seem to run as root.
Any ideas would be appreciated.
Tom
-
On 3/16/2018 at 1:41 PM, Strega said:
This is what I did-
I renamed the EFI- folder to EFI and set my BIOS back to the way it was with 6.4.1. Actually the only change I made was changing Boot Option Filter back to UEFI and Legacy. I left my boot order alone and didn't update the BIOS. My graphics is set to AUTO. Mine did the same as Hoopster, got stuck
i went back into BIOS and changed the boot order to #1 UEFI: Sandisk and set all the others to Disable. It booted up normally. I have rebooted it a couple of times and it boots up.
Gamephreak did discover the fix. Rename the EFI- folder to EFI and set the boot order to #1 UEFI (Flash Drive) and disable all other boot options.
This fixed my failure to boot also. I upgraded from 6.4.1 to 6.5.2 and struck this problem. Changing the boot order and folder name fixed my woes. My mobo is an Asrock H110 mini ITX.
-
I followed the steps on the plex site to repair a database and had no luck. The integrity check said it wasn't a database! I did a .dbinfo on it and it said it had zero tables...
Anyhow I rolled back to a backup db from 2 days ago and everything is up and running again! Thanks very much for your help
")
-
4 hours ago, aptalca said:
Plex is crashing for you. Could be corrupt database. Check the plex media server logs in your config folder. That should tell you the reason for the crash
Thanks for the tip, it does appear to be corrupt

Any ideas on how to repair a corrupt Plex DB?
May 04, 2018 06:08:45.823 [0x150267066700] INFO - Plex Media Server v1.12.3.4973-215c28d86 - ubuntu docker x86_64 - build: linux-ubuntu-x86_64 ubuntu - GMT 10:00 May 04, 2018 06:08:45.823 [0x150267066700] INFO - Linux version: 4.14.16-unRAID (#1 SMP PREEMPT Wed Jan 31 08:51:39 PST 2018), language: en-US May 04, 2018 06:08:45.824 [0x150267066700] INFO - Processor Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz May 04, 2018 06:08:45.824 [0x150267066700] INFO - /usr/lib/plexmediaserver/Plex Media Server May 04, 2018 06:08:45.822 [0x150272a8b800] DEBUG - BPQ: [Idle] -> [Starting] May 04, 2018 06:08:45.824 [0x150272a8b800] DEBUG - Opening 20 database sessions to library (com.plexapp.plugins.library), SQLite 3.13.0, threadsafe=1 May 04, 2018 06:08:45.824 [0x150272a8b800] ERROR - SQLITE3:0x10, 26, file is encrypted or is not a database May 04, 2018 06:08:45.825 [0x150272a8b800] ERROR - Database corruption: sqlite3_statement_backend::prepare: file is encrypted or is not a database for SQL: PRAGMA cache_size=2000 -
7 hours ago, trurl said:
How full is your docker image?
15% of 25 GB.
I downloaded and installed the official Plex container and it works fine, so it must be something specific to the LinuxServer container. Hopefully I can get it going again as my database is quite extensive!
-
Here you go:
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='plex' --net='host' -e TZ="Australia/Sydney" -e HOST_OS="unRAID" -e 'PUID'='99' -e 'PGID'='100' -e 'VERSION'='latest' -v '/mnt/user/movies/':'/media':'rw' -v '/tmp':'/transcode':'rw' -v '/mnt/user/appdata/plex':'/config':'rw' 'linuxserver/plex' bcfff21d0457b684aeda8c996f4c7d3cc3fadd582b5471d5c29b04c27c94ad1aThanks in advance for any suggestions
-
Hi guys,
I've been happily running this container for years now without any problems. I went to use it today and got nothing, so checked the log and it's doing some weird:
It all looks good until it actually gets to the line "Starting Plex Media Server", where it just repeats and never starts the server.
I'm not sure whether it's something to do with last weekend's build? Though a quick google revealed no other problems out there.
Any ideas?
[s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... usermod: no changes ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donations/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 30-dbus: executing... [cont-init.d] 30-dbus: exited 0. [cont-init.d] 40-chown-files: executing... [cont-init.d] 40-chown-files: exited 0. [cont-init.d] 50-plex-update: executing... No update required [cont-init.d] 50-plex-update: exited 0. [cont-init.d] done. [services.d] starting services Starting Plex Media Server. [services.d] done. Starting dbus-daemon dbus[276]: [system] org.freedesktop.DBus.Error.AccessDenied: Failed to set fd limit to 65536: Operation not permitted Starting Avahi daemon Starting Plex Media Server. Found user 'avahi' (UID 106) and group 'avahi' (GID 107). Successfully dropped root privileges. avahi-daemon 0.6.32-rc starting up. No service file found in /etc/avahi/services. *** WARNING: Detected another IPv4 mDNS stack running on this host. This makes mDNS unreliable and is thus not recommended. *** *** WARNING: Detected another IPv6 mDNS stack running on this host. This makes mDNS unreliable and is thus not recommended. *** Joining mDNS multicast group on interface veth288010d.IPv6 with address fe80::473:83ff:fee3:4a39. New relevant interface veth288010d.IPv6 for mDNS. Joining mDNS multicast group on interface virbr0.IPv4 with address 192.168.122.1. New relevant interface virbr0.IPv4 for mDNS. Joining mDNS multicast group on interface vethde15982.IPv6 with address fe80::8c7c:13ff:fe06:4d73. New relevant interface vethde15982.IPv6 for mDNS. Joining mDNS multicast group on interface vethe43364f.IPv6 with address fe80::a080:87ff:fe0d:1d26. New relevant interface vethe43364f.IPv6 for mDNS. Joining mDNS multicast group on interface veth6cfbdfa.IPv6 with address fe80::4a8:42ff:fecf:47e1. New relevant interface veth6cfbdfa.IPv6 for mDNS. Joining mDNS multicast group on interface docker0.IPv6 with address fe80::42:9fff:fe44:581d. New relevant interface docker0.IPv6 for mDNS. Joining mDNS multicast group on interface docker0.IPv4 with address 172.17.0.1. New relevant interface docker0.IPv4 for mDNS. Joining mDNS multicast group on interface br0.IPv6 with address fe80::9c30:56ff:fe9b:fc4e. New relevant interface br0.IPv6 for mDNS. Joining mDNS multicast group on interface br0.IPv4 with address 192.168.178.25. New relevant interface br0.IPv4 for mDNS. Joining mDNS multicast group on interface eth0.IPv6 with address fe80::7285:c2ff:fe21:72b3. New relevant interface eth0.IPv6 for mDNS. Network interface enumeration completed. Registering new address record for fe80::473:83ff:fee3:4a39 on veth288010d.*. Registering new address record for 192.168.122.1 on virbr0.IPv4. Registering new address record for fe80::8c7c:13ff:fe06:4d73 on vethde15982.*. Registering new address record for fe80::a080:87ff:fe0d:1d26 on vethe43364f.*. Registering new address record for fe80::4a8:42ff:fecf:47e1 on veth6cfbdfa.*. Registering new address record for fe80::42:9fff:fe44:581d on docker0.*. Registering new address record for 172.17.0.1 on docker0.IPv4. Registering new address record for fe80::9c30:56ff:fe9b:fc4e on br0.*. Registering new address record for 192.168.178.25 on br0.IPv4. Registering new address record for fe80::7285:c2ff:fe21:72b3 on eth0.*. Server startup complete. Host name is Apollo.local. Local service cookie is 77526132. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. Starting Plex Media Server. -
13 hours ago, BRiT said:
Dont reformat anything, yet.
What device did you run xfs repair on, was it on /dev/sdk2 ?
Yep.
I ran
xfs_repair /dev/sdk2
Then I tried
xfs_repair -L /dev/sdk2
-
Hi,
I got an email from Crashplan today stating that my backup hadn't run for three days. My backup destination is a Lacie external RAID thing with 2x4TB drives in RAID 1. It is connected through USB3 and UD.
Well, it was connected through UD. Upon inspection it was not mounted. I tried to mount it and got this:
Aug 04 20:21:03 Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdk2' '/mnt/disks/Hebe' Aug 04 20:21:03 Mount of '/dev/sdk2' failed. Error message: mount: wrong fs type, bad option, bad superblock on /dev/sdk2, missing codepage or helper program, or other error
I ran xfs_repair without and with the -L flag but that doesn't appear to have helped. It still won't mount
So, given that I'm currently 2000 km away from the machine I can't physically look at the enclosure to see if it's having some hardware RAID melt down or disk failure, have I got any other options? Assuming that I haven't corrupted the data on the good disk with the -L flag, that is if I've had a single drive failure.
Cheers,
Tom
Update: I got someone to have a look at the enclosure and all was well, no LEDs indicating single or double drive failure. They also rebooted the enclosure but the problem still persists...
Oh, there's another small EFI partition on the disk, not sure what it's for, but it's been there since I set it up and it mounts and unmounts fine, so I'm guessing the problem lies with the XFS filesystem on the sdk2 partition. What's the best way to reformat if it's required?
-
5 hours ago, Djoss said:
I'm not sure it's worth implementing this method, because it is something that covers few specific cases, but not all. Someone could use a different software that triggers on the renamed file.
I don't think we can remove everything, since some people may add multiple videos in the same subfolder. When a conversion fails, the source is not removed. So it seems that too much logic would be needed to perform a proper cleanup. The notion of "video" and "non-video" file would need to be introduced.
I'm wondering if your workflow could be:
- Downloaded files are moved to Couchpotato/Sickrage watch folder.
- Couchpotato/Sickrage moves files to Handbrake's watch folder.
- HandBrake converts video to its output folder, which is the final destination.
This way, HandBrake would only get video files (other files being removed by Couchpotato/Sickrage).
The other solution would be to use the hook to move converted videos to the Couchpotato/Sickrage's watch folder. The same script could also do the cleanup.
I'll give it a go! Thanks for your help to date
-
9 hours ago, Djoss said:
So for a file to not be recognized, do the file need to have an unknown extension or a name that doesn't match a known movie/tv show? I'm asking because HandBrake uses the extension of the output file to determine the video format.
When the conversion terminates, the source video file is removed. Then its folder will be removed if it is empty. Are you sure it's the case?
Yes that is the case. So if it was called nfljhslfh9w87520455h25g8ghnwto8.mkv it would not be recognized and would be left alone until the transcode finished and it was renamed to the correct name. However if it was was called NCIS_S11E01.mkv and Sickrage had already snatched (downloaded a torrent and sent it to the torrent program) that episode it would try to move it before Handbrake was finished encoding it because it knows it has downloaded that episode and is expecting it to turn up at some point in the future.
Yes that is true if the movie file was the only file in the directory. If there is a .nfo, .idx, .jpg or anything else the directory is not removed. Just hit it with a rm -rf

-
21 minutes ago, kizer said:
Tis exactly why I let Handbrake do its thing and I move files via scripts I come up with so nothing trips up something else.
Yes I'm sure there are many ways to skin this cat, but if the Djoss' script could prevent this happening with just a few lines of code that would help many users I'm sure.

-
Hi Djoss,
I finally got around to testing your new version. Everything you've done works as expected, however it's still not working for me. The problem I am having is that the Handbrake docker writes the files to Output slowly (obviously), and that both Sickrage and CouchPotato are moving the partially written file to their final destination before the encode is complete. Obviously this freaks out all programs involved!
So what I was thinking was that if you initially store the input file name as a variable, then wrote the output file to a randomly named file, for instance you could call it the MD5 hash that you calculate near the top of your script. Then when the conversion in complete and Handbrake is finished, rename the file back to the stored real file name.
That way, both Sickrage and CP would not recognize the file and try to move it until it is complete.
Second, minor problem (again for my work flow), is that the docker does not remove the directory when it completes the encode. Eg After /watch/movie/movie.mp4 is finished the whole /watch/movie directory should be removed.
Thanks mate.
-
In my experience, with CouchPotato and SickRage, they can both watch the same output folder and work out which movie files belong to which program. I've been using them both like this for six months now without a single misstep.
I assume that they know that they downloaded x.mp4 so ignore all else.
DJoss, I haven't had a chance to test the new version yet, will endeavor to today and let you know how it goes. I'll test for this situation as well.
-
I have disabled hyperthreading and the system did not crash for several hours now, but then again it has run for >40 days without crashing as well, but then again it has crashed after a few hours as well. Very difficult to test for. I honestly doubt that this bug is my problem, but it's another box to tick off I suppose.
Thanks for the interesting write up.
A hypothetical for those in the know:
If I had a Debian vm running on unraid, and used the Debian microcode patch at the vm boot, would the vm be patched, the host and vm be patched or nothing be patched?
-
Thanks for posting this. Please do keep us in the loop with any microcode updates that become available for UnRAID.
My Skylake based machine has been suffering from intermittent crashes for no discernible reason since the get go, specifically when hyperthreading is enabled, so looking forward to seeing whether a microcode update will fix it. I doubt my board manufacturer will release a Bios update this late in the game
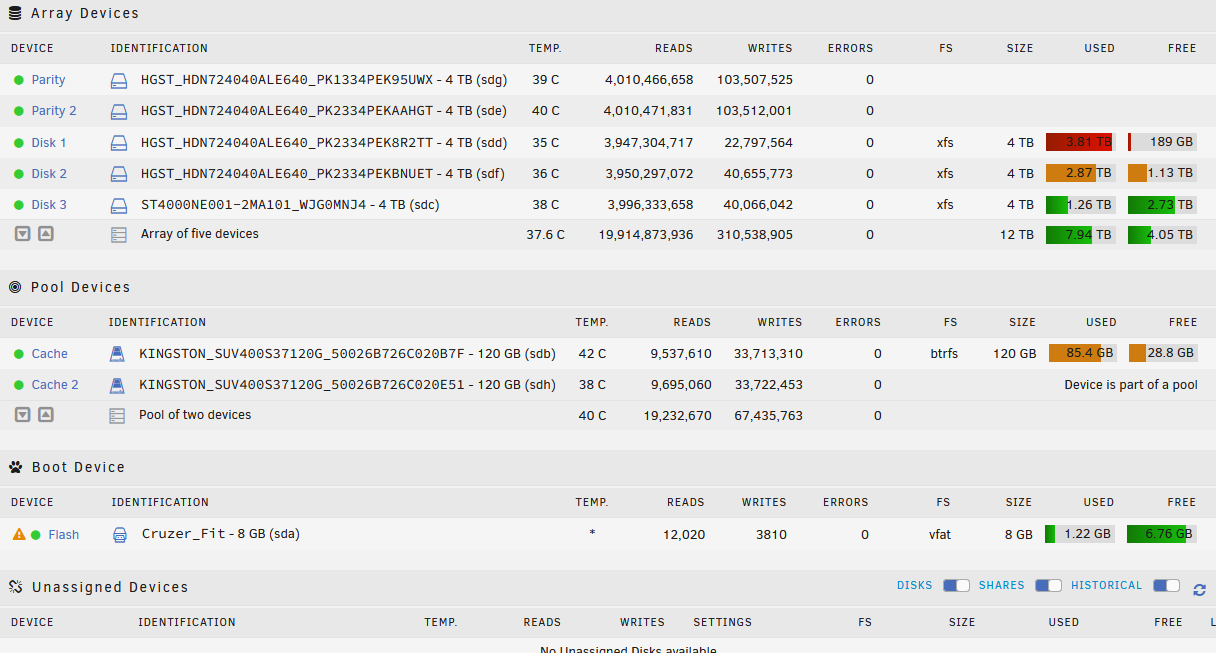

One disk getting full while others not so much
in General Support
Posted
Thanks very much, it was Rsync.