

aterfax
-
Posts
61 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by aterfax
-
-
On 12/21/2022 at 6:44 AM, Hammy Havoc said:
Getting this error when trying to start the latest version of the `matrix` Docker container:
/usr/bin/python3: Error while finding module specification for 'synapse.app.homeserver' (ModuleNotFoundError: No module named 'synapse.app')
Likewise, reverting now.
If the docker image has been updated / rebased on Debian a cursory Google suggests that this may be related:
https://github.com/matrix-org/synapse/issues/4431
Edit: Reverting to the previous image works fine. Filed an issue on Github for this. -
7 minutes ago, ich777 said:
AFAIK yes.
What is not working for you?
Can you please go a bit more into detail? Are any changes necessary to the container?
By default the apt mirroring seems to be missing the cnf directory. This caused my ubuntu machines to throw the 'Failed to fetch' error from my original post.
I added the cnf.sh linked from above to the config directory, edited it to support "jammy" then ran it from inside the running container to download the missing files.
Script as follows:
#!/bin/bash cd /ubuntu-mirror/data/mirror/ for p in "${1:-jammy}"{,-{security,updates}}\ /{main,restricted,universe,multiverse};do >&2 echo "${p}" wget -q -c -r -np -R "index.html*"\ "http://archive.ubuntu.com/ubuntu/dists/${p}/cnf/Commands-amd64.xz" wget -q -c -r -np -R "index.html*"\ "http://archive.ubuntu.com/ubuntu/dists/${p}/cnf/Commands-i386.xz" done
This resolved the 'Failed to fetch' problem.
This could be added to the container in one way or another I suspect, but it does not appear to be something that needs to be ran regularly according to the link above. -
Is the ich777/ubuntu-mirror docker working correctly?
Seeing errors:
E: Failed to fetch https://ubuntu.mirrors.domain.com/ubuntu/dists/jammy/main/cnf/Commands-amd64 404 Not Found [IP: 192.168.1.3 443]
Which may relate to: https://www.linuxtechi.com/setup-local-apt-repository-server-ubuntu/
Note : If we don’t sync cnf directory then on client machines we will get following errors, so to resolve these errors we have to create and execute above script.
Edit: Following the instructions above to grab the cnf directory seems to have resolved the issue. -
General warning from me, I seem to be getting horrible memory leaks with Readarr. After a few hours it consumes all RAM / CPU and grinds my Gen 8 microserver to a halt.
-
To be explicit with my volume mounts for SSL working:
/data/ssl/server.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/cert.pem /data/ssl/ca.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/chain.pem /data/ssl/server.key → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/privkey.pem
I do not recall the exact details of why the above is optimal but I suspect that Poste is handling making it's own full chain cert which results in some cert mangling if you do give it your fullchain cert rather than each separately (various internal services inside the docker need different formats) - I believe that without the mounts as above the administration portal will be unable to log you in.
@brucejobs You might want to check if this is working for you / Poste may have fixed the above.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
To move back to the Swag docker itself.
My own nginx reverse proxy config for the Swag docker looks like:# mail server { listen 443 ssl http2; server_name mailonlycert.DOMAIN.com; ssl_certificate /etc/letsencrypt/live/mailonlycert.DOMAIN.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/mailonlycert.DOMAIN.com/privkey.pem; ssl_dhparam /config/nginx/dhparams.pem; ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA'; ssl_prefer_server_ciphers on; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_pass https://10.0.0.1:444; proxy_read_timeout 90; proxy_redirect https://10.0.0.1:444 https://mailonlycert.DOMAIN.com; } }
Some adjusting if you have multiple SSL certs would be needed and you should take care if using specific domain certs ala documentation here: https://certbot.eff.org/docs/using.html#where-are-my-certificates
The SSL configuration is effectively duplicated from: /config/nginx/ssl.conf thus could be simplified if you are only using one certificate file with:include /config/nginx/ssl.conf
Likewise for the proxy configuration you can simplify if content with the options in /config/nginx/proxy.conf with:include /config/nginx/proxy.conf;
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
When using includes just be sure that the included file has what you need e.g.
The option:
proxy_http_version 1.1;
Is particularly important if you are using websockets on the internal service.
In some cases (Jellyfin perhaps) you may also want additional statements like the following for connection rate limiting:
Outside your server block:limit_conn_zone $binary_remote_addr zone=barfoo:10m;
Inside your server block:location ~ Items\/.*\/Download.* { proxy_buffering on; limit_rate_after 5M; limit_rate 1050k; limit_conn barfoo 1; limit_conn_status 429; }
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Cheers, (hope there's no typos!) -
11 hours ago, tmor2 said:
In other words this statement from your refernce is simply NOT true
The SWAG docker uses certbot........ https://github.com/linuxserver/docker-swag/blob/master/Dockerfile
/mnt/usr/appdata/swag/KEYS/letsencrypt/ is a symlink - due to the way docker mounts things you are better avoiding trying to mount anything symlinked as the appropriate file pathing must exist in the container. If you mount the symlink it will point at things that do not exist within a given container which is why the method 1 below required you to mount the entire config folder - a bad practice.
Mounting a symlink of a cert directly will work, but mounting directly from /mnt/usr/appdata/swag/KEYS/letsencrypt/ will almost certainly break the minute you attempt to get multiple certs for more than one domain.
You appear to be talking about generating a single certificate with multiple subdomains.... this is going to generate only one certificate and one folder it sits in.
Feel free to make an issue on their Github if you are so convinced that you know their container better than they do:
https://github.com/linuxserver/docker-swag/issuesYou can argue the toss about how you should correctly mount things - but you really should be doing method 2.
https://hub.docker.com/r/linuxserver/swagQuoteUsing certs in other containers
This container includes auto-generated pfx and private-fullchain-bundle pem certs that are needed by other apps like Emby and Znc.
To use these certs in other containers, do either of the following:
1 : (Easier) Mount the container's config folder in other containers (ie. -v /path-to-le-config:/le-ssl) and in the other containers, use the cert location /le-ssl/keys/letsencrypt/
2: (More secure) Mount the SWAG folder etc that resides under /config in other containers (ie. -v /path-to-le-config/etc:/le-ssl) and in the other containers, use the cert location /le-ssl/letsencrypt/live/<your.domain.url>/ (This is more secure because the first method shares the entire SWAG config folder with other containers, including the www files, whereas the second method only shares the ssl certs)
These certs include:
1: cert.pem, chain.pem, fullchain.pem and privkey.pem, which are generated by Certbot and used by nginx and various other apps
2: privkey.pfx, a format supported by Microsoft and commonly used by dotnet apps such as Emby Server (no password)
3: priv-fullchain-bundle.pem, a pem cert that bundles the private key and the fullchain, used by apps like ZNC
I am not using the letsencrypt docker, I am using swag which is a meaningless distinction since they are the same project with a different name due to copyright issues. You do not really appear to be reading anything linked properly nor understanding anything fully.
I'm not continuing with this dialogue. -
19 hours ago, tmor2 said:
The guide may pertain to Letsencrypt docker (which is not maintained any longer and has been migrated to SWAG docker).
Your screen shot has 4 lines, what is the FILE NAME (!) of the first path? Line ends with /liv....?????
I assume it's fullchain.pem???
But that needs not be true because there is also priv-fullchain-bundle.pem file.
Your screen shot (below) shows path to swag...as /mnt/user/appdata/letsencrypt/live/SUBDOMAIN.DOMAIN.COM/*.PEM
In swag, this directory is empty -> if you SSH into it from Docker command line, it will be empty.
The keys are stored in following directory: /mnt/usr/appdata/swag/KEYS/letsencrypt/*.PEM
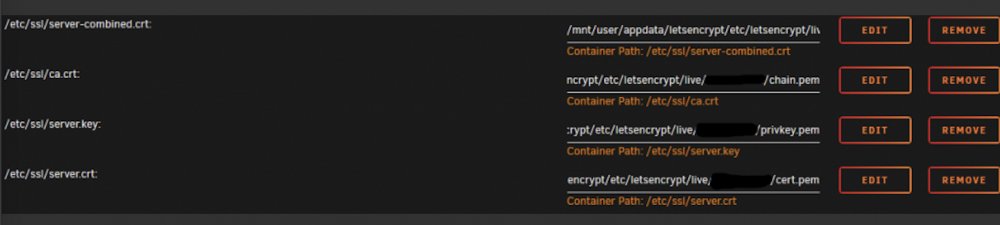
You are familiar with the concept of the past I assume?
Edit: Here are the docs you need, your certificate files are not in the keys folder: https://certbot.eff.org/docs/using.html#where-are-my-certificates -
On 1/24/2021 at 1:53 AM, tmor2 said:
-
How did you add this:
- Is this, Variable, Path, Prot, Label or Device?
-
What did you do in letsencrypt to issue certificate (I issue one for bitwarden, nextcloudetc)
- Did you add in "Sudomains": "mail"? (next to "nextcloud,sonnar,bitwarden...")
- Did you have to do anthing else on DNS provider (my MX record is enabeld)?
- Did you have to add .config file within letenscrypt? I see no existing template
-
when I navigate to /etc/letsencrypt/live I don't see the 3 .pem files. Why?
- There is only etc/letsencrypt/live/nextcloud.MYDOMAIN.COM folder, but the folder is empty

1 - Yes these are paths.2 - I added mail.domain.com - naturally you need to have setup your CNAME / MX records and forward ports in your router/network gateway to the Poste.io server. If you wish for the web GUI of poste.io also to be accessible externally you will also need to setup the correct reverse proxy with SWAG. I don't know what you mean by .config
3 - I blanked the folder in the screen shot as I do not want to share my domain name, but yes the subfolder with your domain name / subdomain name is where the PEM files should be if you have setup SWAG correctly to get SSL certificates. If you are lacking certificates you have probably got it setup incorrectly. -
How did you add this:
-
On 11/15/2020 at 6:05 PM, tmor2 said:
I can't create valid certificates using Poste.io's built in function (within web GUI). I don't know how to set up either of the two to work together. Any help?
I'm using Poste.io docker and I also have Letsencrypt docker for cloud and other stuff. I couldn't find premade certificate file in UNRAID->apps->letsencrypt->nginx-> proxy-confs.
It's really annoying since my iOS devices keep bringing up pop-up "invalid certificate". Even after clicking "cancel" the prompt just keeps coming back.
Error message emailed by post.io are:
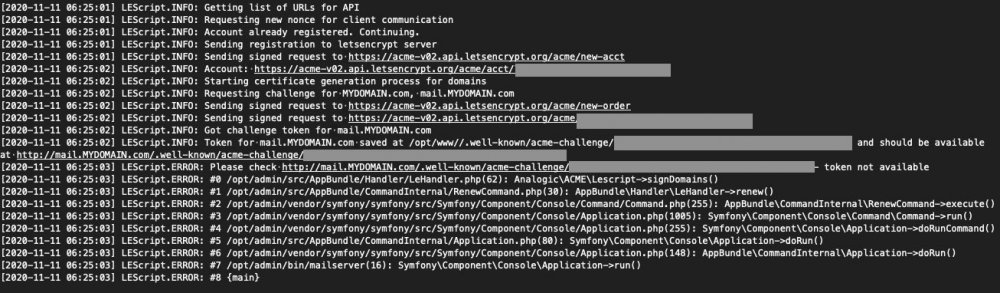
I get another message (emailed) that says:
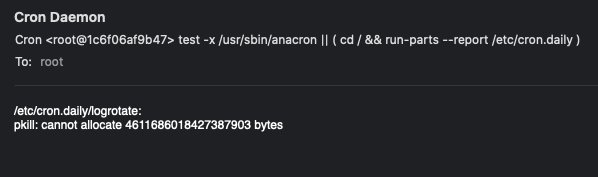
Does anyone have a simple solution on how to make this work?
Snapshots (images) of solutions are more helpful than textual explanations.
EDIT: UPDATED MAY 2021!
I ended up mounting the default certificate files in the docker directly to the certificates from my letsencrypt docker:
To be explicit with my volume mounts for SSL working:
/data/ssl/server.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/cert.pem /data/ssl/ca.crt → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/chain.pem /data/ssl/server.key → /mnt/user/appdata/letsencrypt/etc/letsencrypt/live/mailonlycert.DOMAIN.com/privkey.pem
I do not recall the exact details of why the above is optimal but I suspect that Poste is handling making it's own full chain cert which results in some cert mangling if you do give it your fullchain cert rather than each separately (various internal services inside the docker need different formats) - I believe that without the mounts as above the administration portal will be unable to log you in.
As I mentioned further up in this thread you can alternatively mount .well-known folders between your Poste IO and letsencrypt docker - this will not work if your domain has HSTS turned on with redirects to HTTPS (or this was the case with the version of letsencypt in the docker a while ago as it was reported here: https://bitbucket.org/analogic/mailserver/issues/749/lets-encrypt-errors-with-caprover )
-
On 11/15/2020 at 5:48 PM, tmor2 said:
Hi,
How come your POste.io config is so drastically different from mine?
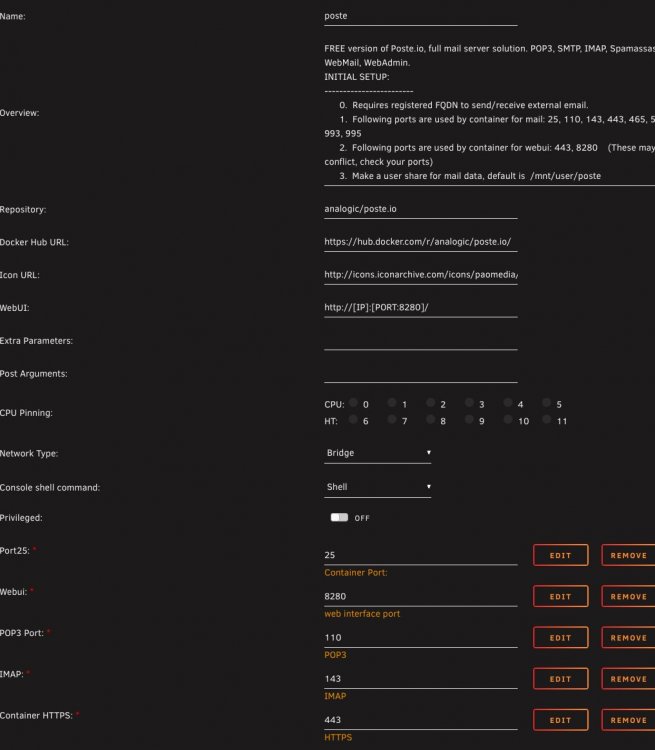
You have advanced view turned on, you can toggle this at the top right.
-
I too would like these to be added however I have solved the problem elsewhere before: https://forums.unraid.net/topic/71259-solved-docker-swarm-not-working/?do=findComment&comment=760934
-
37 minutes ago, ich777 said:
Yes, but you can access also the container console itself in portainer or isn't that enough if you run it with my script that installs screen and everything is needed?
That is a limitation of Docker itself, some containers need the physical path where the files are (eg Don't Starve, L4D2,...) and some not and that's not a limitation of my containers that's a limitation of the application itself that runs in the container. There are also other containers out there that act as in your case L4D2 but that has with the application itself to do and not the container.
Like I've said above you can run the containers from other directorys too but you have to link tho the path where the gamefiles are (/mnt/user is not the physical path this is just 'virtual' path that combines all directorys so that they are in the right spot if you open up a share).
For example:
If you make a new share, let's say 'gameservers' that is forbidden to use the cache and is exclusively on the array the 'virtual' path is /mnt/user/gameserver/... but the real path would be (let's say unraid created this folder on disk3) /mnt/disk3/gameserver/...
The same goes for your appdata directory if it's on the array it would be (also let's say it's on disk3) /mnt/disk3/appdata/... even if it's available through /mnt/user/appdata/
(Please also note that if the files are spread over multiple disks this doesn't work)
I also have some games on my appdata (which is set to use the cache only) where the path would be /mnt/cache/appdata/... and also got games that are on a Unassigned Drives share where the path is /mnt/disks/DISKNAME/... and even got one game that I've set to be on the array in the folder 'gameserver' (and I also set to use only disk6 in my case) where the path is /mnt/disk6/gameserver/...
Hope this makes things clearer.
Many thanks for the explanation - I was not aware that certain things would have issues with the virtual paths as it were.
The script for L4D you sent me works great and starts everything in a screen which is super.
In terms of screen / tmux support for gameservers - I have gotten quite used to using https://linuxgsm.com/ which keeps each server console in its own tmux and has a robust logging setup and a lot of support for many game servers. The access to the console via SSH or if in a docker potentially via the Unraid or portainer console is certainly my preference to RCON given RCON's shortcomings.
The developer (Dan Gibbs) has actually been looking for someone able to maintain / make a docker from his project for some time - so you might find working with his project easier to maintain / supports more game server types? His solution as it stands is excellent supporting automatic install of plugins etc...
I'd love to see a collab! -
I do mean over SSL - you can access your docker consoles from the docker page inside Unraid after all or in setups like mine I have access to all running dockers via a portainer instance being hosted with SSL protection.
I was using /mnt/user/appdata/l4d2 before getting it working on the cache drive- is there a reason why you cannot run this from an appdata dir like all my other dockers? I really have no idea what could be causing a segfault in /mnt/user/appdata/l4d2 unless the file system is doing something whacky in the background with the cache. E.g. below:
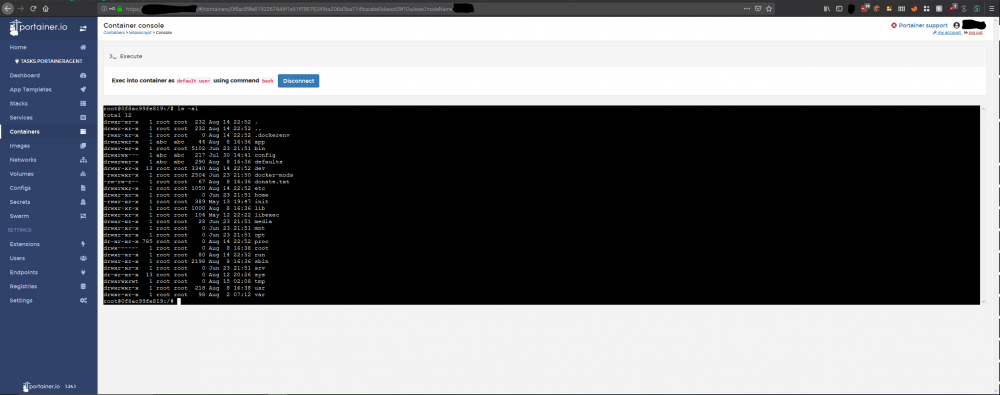
-
Very odd - I now seem to have it working ok but only when on the cache drive....
Edit - the ask for access via screen for server console is kinda agnostic of the server type - some things will not support rcon and rcon itself is an insecure protocol - I'd rather just login over SSL and deal with things via portainer or via Unraid docker console. -
15 hours ago, ich777 said:
I will build a script that you can use so that you could launch it inside a screen session, really don't understand the usecase for that (there are so many apps on the mobile phone or even software on windows/linux so that you can connect to rcon)...Here is the finished script: l4d2.sh
Please download it and place it in your appdata folder (I don't recommend to place it in the same folder as L4D2.
Then go to the template page and create a new Path (update the 'Host Path' where your script physically is - please not that you have to type in 'user.sh' at 'Container Path' and 'l4d2.sh' at 'Host Path' at the end):
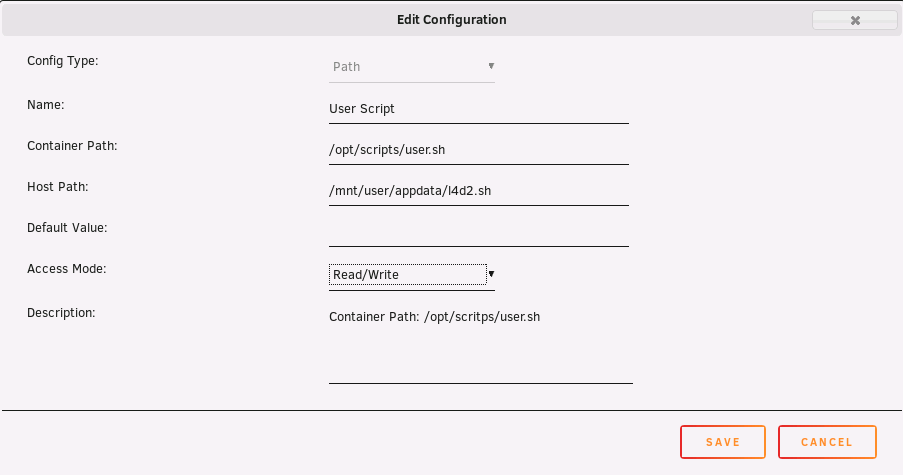
This script should work for most of the 'srcds' containers you can also customize it to your liking (please note that I also included a script for the termination handler - the termination handler is only included in the newer builds and I update the containers in the near future to support this -
at the time you can leave the script as it is but please note that if you end the screen session the container will NOT automatically restart if the termination handler is not implemented).EDIT: Updated the L4D2 container to support the termination handler...
After the container started entirely you can then connect to the screen session by opening a console window for that container and type in: 'su $USER -c "screen -xS &USER"' or simply 'su steam -c "screen -xS steam"' (put also a message in the log how to do that).
If you got further questions feel free to contact me.
")
I will look into that.
EDIT: No problem here, also attached the log: l4d2.log
Have you changed something in the template itself?
On which Unraid version are you? Have you installed a cache drive in your system? Can you try to change the 'ServerFiles' path to '/mnt/user/appdata/l4d2' (stop the container and delete the old folder for left4dead in the appdata directory befor doing that...)
That doesn't work, gdb isn't installed in the containers so there is no output.
But I don't need that output.
You want only to bring up the command line?
This should be possible, I will look into it but jsDOS is designed to load a zip file and then start the executable inside the zip, don't know if it would work the way you would like to use it.
Just purged the folder and reinstalled the app from the community apps plugin again today, same issue - I have been installing to /mnt/user/appdata/l4d2 rather than cache from the start - I am on Unraid 6.8.3 - I can try using my cache drive - pretty sure my appdata folder is set to prefer mode so I will swap that now and see if that helps.
See logs:Update state (0x101) committing, progress: 58.67 (4812218723 / 8202656842) Update state (0x101) committing, progress: 58.68 (4813019123 / 8202656842) Update state (0x101) committing, progress: 58.69 (4814223871 / 8202656842) Update state (0x101) committing, progress: 58.70 (4815004139 / 8202656842) Update state (0x101) committing, progress: 58.71 (4815629318 / 8202656842) Update state (0x101) committing, progress: 58.72 (4816202362 / 8202656842) Update state (0x101) committing, progress: 58.72 (4816703629 / 8202656842) Update state (0x101) committing, progress: 58.73 (4817122866 / 8202656842) Update state (0x101) committing, progress: 58.74 (4817962729 / 8202656842) Update state (0x101) committing, progress: 58.75 (4818946359 / 8202656842) Update state (0x101) committing, progress: 58.76 (4819688920 / 8202656842) Update state (0x101) committing, progress: 58.76 (4820238981 / 8202656842) Update state (0x101) committing, progress: 58.77 (4820707914 / 8202656842) Update state (0x101) committing, progress: 62.82 (5152699145 / 8202656842) Update state (0x101) committing, progress: 62.84 (5154537738 / 8202656842) Update state (0x101) committing, progress: 73.26 (6009561231 / 8202656842) Update state (0x101) committing, progress: 73.27 (6010194234 / 8202656842) Update state (0x101) committing, progress: 73.28 (6010693799 / 8202656842) Update state (0x101) committing, progress: 73.29 (6011708900 / 8202656842) Update state (0x101) committing, progress: 73.30 (6012476650 / 8202656842) Update state (0x101) committing, progress: 73.31 (6013542086 / 8202656842) Update state (0x101) committing, progress: 73.32 (6014328143 / 8202656842) Update state (0x101) committing, progress: 73.39 (6019990404 / 8202656842) Update state (0x101) committing, progress: 73.40 (6020942346 / 8202656842) Update state (0x101) committing, progress: 73.41 (6021653635 / 8202656842) Update state (0x101) committing, progress: 92.92 (7622095264 / 8202656842) Update state (0x101) committing, progress: 92.93 (7623095284 / 8202656842) Update state (0x101) committing, progress: 92.95 (7624106147 / 8202656842) Update state (0x101) committing, progress: 92.96 (7625166870 / 8202656842) Update state (0x101) committing, progress: 93.03 (7630646624 / 8202656842) Update state (0x101) committing, progress: 93.04 (7631921404 / 8202656842) Update state (0x101) committing, progress: 97.85 (8026301170 / 8202656842) Success! App '222860' fully installed. ---Prepare Server--- ---Server ready--- ---Start Server--- Server will auto-restart if there is a crash. Setting breakpad minidump AppID = 222860 Using breakpad crash handler Forcing breakpad minidump interfaces to load Looking up breakpad interfaces from steamclient Calling BreakpadMiniDumpSystemInit Segmentation fault Add "-debug" to the /serverdata/serverfiles/srcds_run command line to generate a debug.log to help with solving this problem Fri 14 Aug 2020 10:30:46 PM BST: Server restart in 10 seconds Setting breakpad minidump AppID = 222860 Using breakpad crash handler Forcing breakpad minidump interfaces to load Looking up breakpad interfaces from steamclient Calling BreakpadMiniDumpSystemInit Segmentation fault
-
More debug -
Further debug log output -
/serverdata/serverfiles/srcds_run: 1: /serverdata/serverfiles/srcds_run: gdb: not found WARNING: Please install gdb first. goto http://www.gnu.org/software/gdb/ Server will auto-restart if there is a crash. Setting breakpad minidump AppID = 222860 Using breakpad crash handler Forcing breakpad minidump interfaces to load Looking up breakpad interfaces from steamclient Calling BreakpadMiniDumpSystemInit Segmentation fault Add "-debug" to the /serverdata/serverfiles/srcds_run command line to generate a debug.log to help with solving this problem Thu 13 Aug 2020 11:59:30 PM BST: Server restart in 10 seconds ---Server ready--- ---Start Server--- Enabling debug mode /serverdata/serverfiles/srcds_run: 178: ulimit: error setting limit (Operation not permitted) /serverdata/serverfiles/srcds_run: 1: /serverdata/serverfiles/srcds_run: gdb: not found WARNING: Please install gdb first. goto http://www.gnu.org/software/gdb/ Server will auto-restart if there is a crash. -
Ah right - could I recommend launching all servers inside a screen or a tmux as an enhancement?
As for the error with left4dead - I purged and reinstalled twice leaving it to validate the second time and it resulted in the following (part of why I wanted the console):
Add "-debug" to the /serverdata/serverfiles/srcds_run command line to generate a debug.log to help with solving this problem Thu 13 Aug 2020 10:48:24 PM BST: Server restart in 10 seconds Setting breakpad minidump AppID = 222860 Using breakpad crash handler Forcing breakpad minidump interfaces to load Looking up breakpad interfaces from steamclient Calling BreakpadMiniDumpSystemInit Segmentation fault -
16 hours ago, ich777 said:
Which container?
Try to change ot to /mnt/user/appdata/nwnee
What have you linked and how? I think this is only a linking issue.
Any of the source servers e.g. left4dead2 which now appears to be stuck in a bootloop.
-
Does this docker have any support for accessing the running console of the game through screen or tmux?
I cannot see any documented way to access the running console to run server commands? -
I might be wrong, but when I have set different UID and GID this does not seem to be respecting that.
Edit: Looking at the files, the UID and GID are currently hardcoded in the dockerfile and I do not see anything in the start scripting to change from the default values of 99 and 100.
So if you need to change this, you need to use the dockerfile and build the image yourself currently.
Might be an improvement to add something to the built in start script to account for this.
Many thanks @ich777-
 1
1
-
-
Looks like this is related to the VM XML config:
-<hostdev type="pci" mode="subsystem" managed="yes"> <driver name="vfio"/> -<source> <address bus="0x04" function="0x0" slot="0x00" domain="0x0000"/> </source> <rom file="/boot/vbios/gtx 1060 dump.rom"/> <address type="pci" bus="0x00" function="0x0" slot="0x05" domain="0x0000"/> </hostdev> -<hostdev type="pci" mode="subsystem" managed="yes"> <driver name="vfio"/> -<source> <address bus="0x04" function="0x1" slot="0x00" domain="0x0000"/> </source> <address type="pci" bus="0x00" function="0x0" slot="0x06" domain="0x0000"/> </hostdev>
Assuming these are the GPU and GPU audio devices you have the audio in a different slot in the VM. These need to be matching the physical layout from the source hardware, i.e. same slot, different function.
Correct the second address to the same slot and one function higher i.e. :
<address type="pci" bus="0x00" function="0x1" slot="0x05" domain="0x0000"/>
Which will probably fix the issue.
See reasoning below:
This is assuming that the passthrough is actually working* and the VM can actually see the GPU hardware. -
3 hours ago, 1812 said:
You should read the top of the thread as it pertains to RMRR issues and proliants. It's not a red herring, it's a legitimate bios issue that prevents working hardware passthrough.
You should read what I said then - "I still get an RMRR warning on a ethernet passthrough on my server" i.e. I get the warning on a device that is passing through correctly. Ergo, red herring.
-
14 minutes ago, Tswitcher29 said:
Well I just now noticed its only giving that RMRR warning for the sound portion nvidia audio but dosnt everything have to be passed through in order to not get code 43
I still get an RMRR warning on a ethernet passthrough on my server- given it is working in the VM, I assume you are getting a red herring of a warning.
Edit: I suppose you can test by setting up a Ubuntu / linux VM and taking a look for the device.
-
17 minutes ago, Tswitcher29 said:
I posted diagnostics and screenshot of logs. I am still getting service is ineligible for iommu domain attach due to rmmr in the logs. But the vm is booting with the gpu passthrough just says Microsoft basic display adapter in windows I try to install drivers it shows up then but with code 43.
I've dumped bios and edited bios and tried a bunch of stuff I cant get drivers to install
IOMMU RMRR warning is probably a red herring.
I suspect you need to follow / attempt to avoid error 43 with the link I sent above: https://mathiashueber.com/fighting-error-43-nvidia-gpu-virtual-machine/
Specifically - KVM hidden via Libvirt xml - you will need to edit your VM in xml mode. (Top right toggle in the VM editor.)
Another user fixed it here:You should probably search the forums first?







[Support] ich777 - Application Dockers
in Docker Containers
Posted
Was this an issue for other users? Did this get resolved in the container?