

runraid
-
Posts
94 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by runraid
-
Things load fine and fast on the apps tab. @Squid
-
@bonienl thanks, but I'm not using pihole.
-
When I click "Check for updates", the UI spins forever with "checking..." next to each container. If I eventually reload the page I see updates. When I go to the plugins page and click "Check for updates", its very very very slow. Any idea why things are slow like this?
-
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
Anyways, I know when mine corrupts. It’s when a new show or movies is added to plex for the first time. I use sonarr, it will download a tv show to my download directory, then move it to my media directory. Plex is configure to watch for file changes, notices the new file and attempts to add it to my collection. Then db corrupts at that point. Same process with movies. Deluge downloads to the download directory then moves it to the media, at which point my db corrupts. From there, I restore from my backup db, start plex, and tell it to scan for new files. It has no problem at that point. It’s the first scenario that corrupts plex. I haven’t noticed a pattern with sonarr or the others yet. But it seems like if one is corrupted the others have a high chance of being corrupted as well. -
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
I have the backup plugin installed but I do not have it configured to create backups. Per the plugin, it says it stops the container. -
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
I have the unassigned devices plugin installed but I’m not using it. I’ve been fighting corruption since I upgraded to 6.7.0. Switched to /mnt/disk3 and I was good for nearly a week then my SQLite db files corrupted yesterday. Maybe I’ll try uninstalling the plugin. -
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
I just got corrupted again, even when routing to /mnt/disk3. Jun 05, 2019 19:32:48.284 [0x1482e0d63700] ERROR - SQLITE3:(nil), 11, database corruption at line 79051 of [bf8c1b2b7a] Jun 05, 2019 19:32:48.284 [0x1482e0d63700] ERROR - SQLITE3:(nil), 11, statement aborts at 9: [select statistics_bandwidth.id as 'statistics_bandwidth_id', statistics_bandwidth.account_id as 'statistics_bandwidth_account_id', statistics_bandwidth.device_id as 'statistics_bandwidt Jun 05, 2019 19:32:48.284 [0x1482e0d63700] ERROR - Thread: Uncaught exception running async task which was spawned by thread 0x1482e3428700: sqlite3_statement_backend::loadOne: database disk image is malformed Jun 05, 2019 19:32:48.285 [0x148289c6b700] ERROR - SQLITE3:(nil), 11, database corruption at line 79051 of [bf8c1b2b7a] Jun 05, 2019 19:32:48.285 [0x148289c6b700] ERROR - SQLITE3:(nil), 11, statement aborts at 9: [select statistics_bandwidth.id as 'statistics_bandwidth_id', statistics_bandwidth.account_id as 'statistics_bandwidth_account_id', statistics_bandwidth.device_id as 'statistics_bandwidt Jun 05, 2019 19:32:48.286 [0x148289c6b700] ERROR - Thread: Uncaught exception running async task which was spawned by thread 0x1482e3227700: sqlite3_statement_backend::loadOne: database disk image is malformed And here's come config: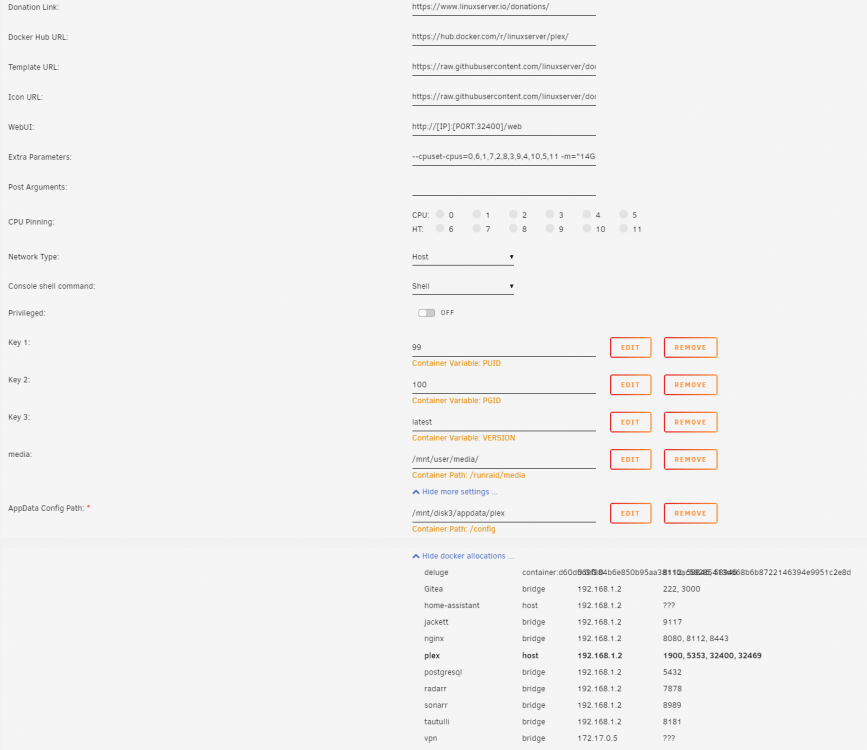
-
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
Min is on auto as well.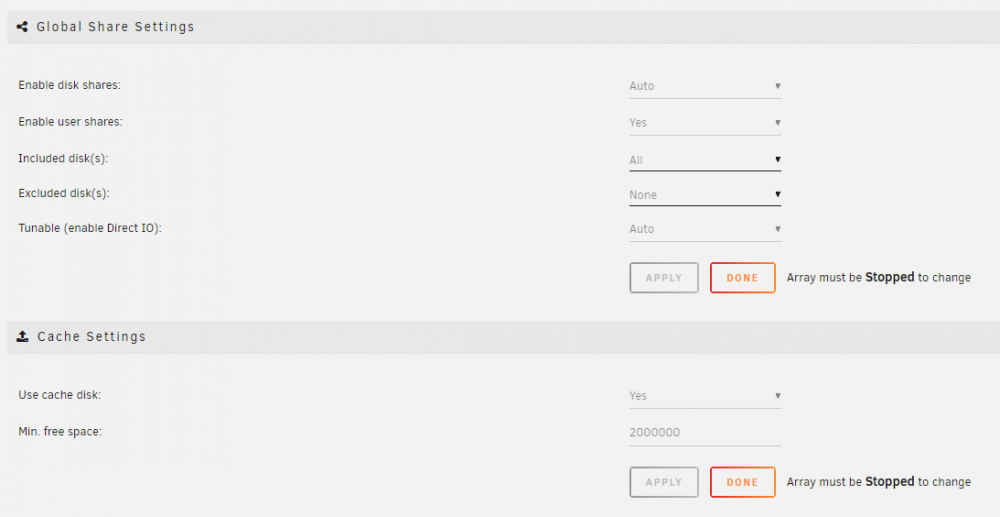
-
Downgraded back to 6.6.7 due to Sqlite corruption
runraid replied to Rich Minear's topic in General Support
Here's a reddit thread on this. There's numerous people suffering from SQLite DB corruption since upgrading to 6.7.0, myself included. For me, Plex, Sonarr, Radarr, and Tautulli all had corrupted databases multiple times. Moving to /mnt/disk1 does solve the issue. I never had this problem prior to 6.7.0. It wasn't until I upgraded until this happened. -
Adding a new TV to Plex corrupts the SQLite db
runraid replied to runraid's topic in General Support
One additional note, /mnt/cache works as well, same permissions issue. add "chmod +w *" on the db files fixed my loading issue. I'll run it on the cache drive for a few days. I guess with this, I'll need to backup to the array manually? -
Adding a new TV to Plex corrupts the SQLite db
runraid replied to runraid's topic in General Support
I was able to get it up and running on /mnt/disk3. Problem was permissions on the db files. Added +w and I'm good there now. I'll see how things go for a few days and report back. -
Adding a new TV to Plex corrupts the SQLite db
runraid replied to runraid's topic in General Support
/mnt/disk3 doesn't work either. -
Adding a new TV to Plex corrupts the SQLite db
runraid replied to runraid's topic in General Support
No luck when using /mnt/cache. I copied everything there and the corruption still occurs, even if I restore from a good copy. -
Adding a new TV to Plex corrupts the SQLite db
runraid replied to runraid's topic in General Support
Thank you very much. I’m out right now but will test this as soon as I return and update this thread with the results. -
I've been facing an issue where my com.plexapp.plugins.library.db DB corrupts. I've narrowed it down with this repro: Download a new TV show Place it in my TV media directory Plex will notice a new show was added and start to add it to my Plex library The DB will corrupt I then need to restore my db files from the previous days backup. I then click "Scan Library Files" in Plex to find the missing TV show, it finds and adds it without issue. Things work great until it automatically finds new media. This is how I restore: DATE="2019-06-01" rm -f com.plexapp.plugins.library.db-shm rm -f com.plexapp.plugins.library.db-wal rm -f com.plexapp.plugins.library.blobs.db rm -f com.plexapp.plugins.library.db cp com.plexapp.plugins.library.blobs.db-$DATE com.plexapp.plugins.library.blobs.db cp com.plexapp.plugins.library.db-$DATE com.plexapp.plugins.library.db Anyone have any idea of what could be going on? I've tried changing my config directory from /mnt/user/appdata/plex to /mnt/user/cache/plex and that causes 100% corruption 100% of the time. I can't even get Plex to start when I point at /mnt/user/cache/plex. I've ran SMART on the disk that contains the DB and there are no errors. I run a VM on the SSD cache drive and have no issues. My cache drive (SSD) has this SMART self-test history: Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Vendor (0x60) Completed without error 00% 4108 - # 2 Offline Completed without error 00% 0 - # 3 Offline Completed without error 00% 0 - # 4 Offline Completed without error 00% 0 - # 5 Vendor (0x54) Completed without error 00% 0 - # 6 Vendor (0xb3) Unknown status (0xe) 60% 211 - # 7 Vendor (0x9d) Unknown status (0xe) 50% 57544 - # 8 Vendor (0xa5) Unknown status (0xe) 50% 57032 - # 9 Offline Completed without error 00% 0 - #10 Offline Completed without error 00% 64 - #11 Offline Completed without error 00% 0 - #12 Offline Completed without error 00% 0 - #13 Offline Completed without error 00% 0 - And this SMART error log: Warning: ATA error count 2830 inconsistent with error log pointer 4 ATA Error Count: 2830 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 2830 occurred at disk power-on lifetime: 37228 hours (1551 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 c3 40 00 30 b3 01 Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ef 02 40 00 30 b3 01 60 00:00:15.776 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.776 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.760 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.760 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.745 SET FEATURES [Enable write cache] Error 2829 occurred at disk power-on lifetime: 37228 hours (1551 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 c3 40 00 30 b3 01 Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ef 02 40 00 30 b3 01 60 00:00:15.760 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.760 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.745 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.745 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.729 SET FEATURES [Enable write cache] Error 2828 occurred at disk power-on lifetime: 37228 hours (1551 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 c3 40 00 30 b3 01 Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ef 02 40 00 30 b3 01 60 00:00:15.745 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.745 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.729 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.729 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.714 SET FEATURES [Enable write cache] Error 2827 occurred at disk power-on lifetime: 37228 hours (1551 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 c3 40 00 30 b3 01 Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ef 02 40 00 30 b3 01 60 00:00:15.729 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.729 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.714 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.714 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.698 SET FEATURES [Enable write cache] Error 2826 occurred at disk power-on lifetime: 37228 hours (1551 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 c3 40 00 30 b3 01 Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ef 02 40 00 30 b3 01 60 00:00:15.714 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.714 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.698 SET FEATURES [Enable write cache] ef 02 00 00 30 b3 00 00 00:00:15.698 SET FEATURES [Enable write cache] ef 02 40 00 30 b3 01 60 00:00:15.682 SET FEATURES [Enable write cache]
-
Support thread for the lidarr Docker template. Application Name: lidarr Application Site: https://www.reddit.com/r/Lidarr/ Docker Hub: https://hub.docker.com/r/volikon/lidarr/ Application Github: https://github.com/lidarr Template Github: https://github.com/rroller/unraid-templates
-
@Squid can you please review?
-
Thanks -- now the process is clear. I've update per the instructions above. No manual edits. I added my repo and tested, works greats. Can you review once more?
-
Please configure https://github.com/rroller/unraid-templates for use with CA. Thanks! I've added a support thread here
-
Support thread for the pgadmin Docker template. Application Name: pgadmin Application Site: https://www.pgadmin.org/ Docker Hub: https://hub.docker.com/r/fenglc/pgadmin4/ Application Github: https://github.com/postgres/pgadmin4 Template Github: https://github.com/rroller/unraid-templates Admins: Please configure https://github.com/rroller/unraid-templates for use with CA. Thanks!
-
Access audio out from inside a Docker container?
runraid replied to runraid's topic in General Support
Thanks. I'm going to do some experimenting. I'm fine with Linux but it's nice not having that VM running and it's nice having the Unraid UI show me when there are updates to the image. I guess I could run a small vm that I use to play the audio through and have home assistant play through that. Thanks again for all of the quick replies. You all are very helpful. -
Access audio out from inside a Docker container?
runraid replied to runraid's topic in General Support
Thanks again. I'm wondering what my options are? I'd like to keep Home Assistant in a Docker container and not in a VM. I currently have it playing audio via a Chrome Cast Audio, but that has about a 3 second delay. I'd like to have a speaker wired up directly. -
Access audio out from inside a Docker container?
runraid replied to runraid's topic in General Support
I see. Thanks. Could the container have the audio drivers? -
Hi, how would I go about accessing the audio out jack on my server from inside a Docker container? I run the Home Assistant Docker container and I'd like to play sound during certain events but I'm not sure how to get access to the audio out inside the container. Thanks!
-
The "dperson/nginx" container latest version no longer runs on unraid because the latest dperson/nginx enabled ipv6. Can we please have ipv6 enabled on unraid? Please see: https://github.com/dperson/nginx/commit/5f06b2b246f9e8c712d8fb8becced3cef2b37b82


