

jbuszkie
-
Posts
693 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jbuszkie
-
-
3 minutes ago, ljm42 said:
DNS rebinding protection prevents "yourpersonalhash.unraid.net" from resolving to a LAN IP. So in order to enable SSL for Local Access you must permanently disable DNS rebinding protection.
Yeah.. I figured that out. I was able to setup a DNSMASQ setting to allow unraid.net in my tomato config
Thanks!
-
 1
1
-
-
Update..
I do get the spinning circle every time I try to apply when I change something in my servers area.
If I disable remote access... I get the spinning circle.
But when I go back to something else or refresh, I see the new setting. Same thing if I enable .. I get the spinning applying that never goes away.. But if I refresh, it sticks.
However... If I try to change the port, it never sticks. I always see the 443 port. Double however... if I actually try the remote
access, I see the new port being used and it works fine even though the webpage settings still says port 443.
I do have the flash backup disabled if that has anything to do with this...
Bug? Something with my setup?
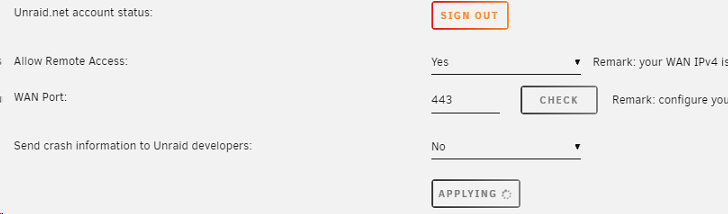
-
Trying to updated the WAN port on myservers and I just get the spinning circle on "applying" button.
If I go to another page and then come back.. I still see the default port of 443.
Second question.. Do I have to keep "prevent DNS rebind attacks" unchecked on my router once I provisioned?
-
21 minutes ago, sage2050 said:
I applied hyperv's fix but im still getting "not available" on all my dockers. Do I need to do anything after I edit the file?
I had the same thing yesterday.. But when I checked it this AM.. It was now working... So it just took some time for me.. I don't know why.. Maybe someone with more knowledge can explain it or show how to get the fix to work immediately ..
-
I tried the manual fix... But it isn't working. I still get the "not available"..
Is there some sort of service I have to restart?
preg_match('@Docker-Content-Digest:\s*(.*)@i', $reply, $matches);That's what's in my file...
-
I've manually changed the Influxdb to 1.8 That fixed my auth issues. But a could days ago or so I have a notice that there is an update to influxdb. If I set the version for 1.8, why is it still saying there is an update available?
-
1
-
-
The only correlation I have figured out might have something to do with using the web browser terminals. I've tried to avoid using them and I haven't had an instance in a while now. I've also made sure they were all closed down right after I used them. Before I was using them and possibly leaving them open on different machines.
Not sure if that's it, but that's the only thing I can think of that might slightly correlate.
-
Ha.. I had to refresh my browser to see there was an OS update! When I wrote the first message the update OS thing only showed 6.8.3
I still prefer to wait to a while before upgrading. So I guess I don't update this plugin until I switch. Oh Well... Thanks for the great plugin though!
Jim
-
On 3/3/2021 at 8:44 AM, olehj said:
Update 2021.03.03
- Commit #161 - FEATURE: Formatting of the comment field has been added, read "Help" for more information under the "Tray Allocations" tab. @shEiD
- Commit #158 - BUG: NVME drives not detected with Unraid 6.9 because of changes in the output of lsscsi. From now on only Unraid 6.9 and above is supported. Older releases has to use the developer build without nvme support or previous Disk Location version. @Woutch @lovingHDTV
is 6.9 released or is it still beta? I can't update because it was restricted to 6.9?
I try not to upgrade until the next unraid version is stable for a while... I guess supporting something in the beta version breaks the current released version?
Jim
-
I'm on 6.8.3 ... Which I thought was the latest stable?? Are you saying we should try the latest beta?
-
My terminal is all messed up when in this state as well... I have to use a putty window to talk to unraid.
-
Ok.. it happened again today! grrr....
I'm posting this here to try for next time so I don't have to reboot..
QuoteTo restart nginx i've been having to use both
/etc/rc.d/rc.nginx restart
and /etc/rc.d/rc.nginx stop
Quite often checking its status will show its still running. So make sure it's really closed. It doesn't want to close gracefully
/etc/rc.d/rc.nginx status
I'll have to see if this resolves the out of memory issue without a reboot...
I'd still like to know what's causing this or how to permanently avoid this...
Jim
-
Mine just happened again today... @limetech, any thoughts on this? It seems like there are several of us that have this issue?
-
Mine just happened again. Is there a way to fix this without re-booting the system?
-
1 hour ago, Skylord123 said:
There aren't really "Best Practices" as it all depends on what you need logged and your use case. I'm using MQTT for my home automation so I really only care about logging what devices connect and error messages. This is what I have my log options in mosquitto.conf set to:
log_dest stderr log_type error connection_messages true log_timestamp true
If you really want to add log rotating it is an option you can pass to the container. Here is a post that describes it very well:
https://medium.com/@Quigley_Ja/rotating-docker-logs-keeping-your-overlay-folder-small-40cfa2155412Thanks for the info. so it was really just as easy as purging the log! I wanted to make sure. Thanks! I'll have to look into the log rotate if I want to do that.
-
52 minutes ago, spants said:
Which file is that size? Can you post your mosquitto.conf file?
I was logging the default which was everything, I believe.. I've recently changed it to just errors and warnings. But I can't figure out how to purge it.. Or, potentially, how to use log rotate to keep it manageable. How do other folks handle the mqtt logging? Do they log everything but put it in appdata area?
What are best practices?
Jim
-
20 minutes ago, Phoenix Down said:
I don't have an answer to your question, but how did you get that output?
-
1
-
-
Another question.. My MQTT log file is > 4GB! how do I get rid of it?
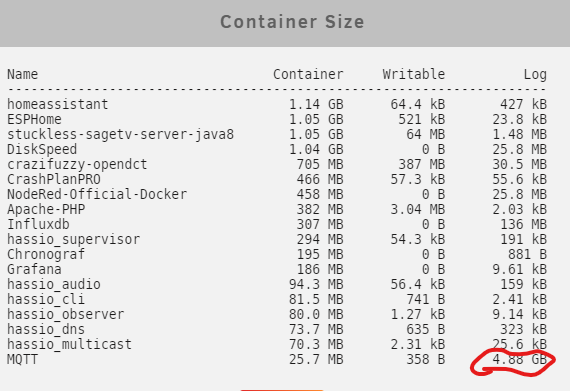
-
I am having this issue too.... 😞
-
So this is the second time this has happened in a couple weeks. Syslog fills up and runs out of space and the system grinds to a halt. Can you guys tell what's going on here?
Here is the last couple lines of syslog before I get all the errors...
Oct 21 06:20:03 Tower sSMTP[3454]: Sent mail for [email protected] (221 elasmtp-masked.atl.sa.earthlink.net closing connection) uid=0 username=root outbytes=1676 Oct 21 07:00:03 Tower kernel: mdcmd (1109): spindown 2 Oct 21 07:20:02 Tower sSMTP[30058]: Sent mail for [email protected] (221 elasmtp-mealy.atl.sa.earthlink.net closing connection) uid=0 username=root outbytes=1672 Oct 21 08:15:32 Tower kernel: mdcmd (1110): spindown 4 Oct 21 08:15:41 Tower kernel: mdcmd (1111): spindown 5 Oct 21 08:20:03 Tower sSMTP[30455]: Sent mail for [email protected] (221 elasmtp-mealy.atl.sa.earthlink.net closing connection) uid=0 username=root outbytes=1680 Oct 21 08:25:01 Tower kernel: mdcmd (1112): spindown 1 Oct 21 09:16:19 Tower nginx: 2020/10/21 09:16:19 [alert] 5212#5212: worker process 5213 exited on signal 6 Oct 21 09:16:20 Tower nginx: 2020/10/21 09:16:20 [alert] 5212#5212: worker process 27120 exited on signal 6 Oct 21 09:16:21 Tower nginx: 2020/10/21 09:16:21 [alert] 5212#5212: worker process 27246 exited on signal 6 Oct 21 09:16:22 Tower nginx: 2020/10/21 09:16:22 [alert] 5212#5212: worker process 27258 exited on signal 6 Oct 21 09:16:23 Tower nginx: 2020/10/21 09:16:23 [alert] 5212#5212: worker process 27259 exited on signal 6 Oct 21 09:16:24 Tower nginx: 2020/10/21 09:16:24 [alert] 5212#5212: worker process 27263 exited on signal 6 Oct 21 09:16:24 Tower nginx: 2020/10/21 09:16:24 [alert] 5212#5212: worker process 27264 exited on signal 6 Oct 21 09:16:25 Tower nginx: 2020/10/21 09:16:25 [alert] 5212#5212: worker process 27267 exited on signal 6That line repeats for a long time then it reports some memory full issue...
Oct 21 13:14:53 Tower nginx: 2020/10/21 13:14:53 [alert] 5212#5212: worker process 3579 exited on signal 6 Oct 21 13:14:54 Tower nginx: 2020/10/21 13:14:54 [alert] 5212#5212: worker process 3580 exited on signal 6 Oct 21 13:14:55 Tower nginx: 2020/10/21 13:14:55 [alert] 5212#5212: worker process 3583 exited on signal 6 Oct 21 13:14:56 Tower nginx: 2020/10/21 13:14:56 [alert] 5212#5212: worker process 3584 exited on signal 6 Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [crit] 3629#3629: ngx_slab_alloc() failed: no memory Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [error] 3629#3629: shpool alloc failed Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [error] 3629#3629: nchan: Out of shared memory while allocating message of size 6724. Increase nchan_max_reserved_memory. Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [error] 3629#3629: *4535822 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [error] 3629#3629: MEMSTORE:00: can't create shared message for channel /disks Oct 21 13:14:57 Tower nginx: 2020/10/21 13:14:57 [alert] 5212#5212: worker process 3629 exited on signal 6 Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [crit] 3641#3641: ngx_slab_alloc() failed: no memory Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [error] 3641#3641: shpool alloc failed Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [error] 3641#3641: nchan: Out of shared memory while allocating message of size 6724. Increase nchan_max_reserved_memory. Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [error] 3641#3641: *4535827 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [error] 3641#3641: MEMSTORE:00: can't create shared message for channel /disks Oct 21 13:14:58 Tower nginx: 2020/10/21 13:14:58 [alert] 5212#5212: worker process 3641 exited on signal 6 Oct 21 13:14:59 Tower nginx: 2020/10/21 13:14:59 [crit] 3687#3687: ngx_slab_alloc() failed: no memory Oct 21 13:14:59 Tower nginx: 2020/10/21 13:14:59 [error] 3687#3687: shpool alloc failed Oct 21 13:14:59 Tower nginx: 2020/10/21 13:14:59 [error] 3687#3687: nchan: Out of shared memory while allocating message of size 6724. Increase nchan_max_reserved_memory.After this I just keep getting these out of memory errors...
Do you guys have any idea what could be causing this?
-
My MQTT log file is huge and growing.. What (and how) do you guys have your log stuff set to? I never messed with this so it's probably set to the default.
This is what is in the conf file.
log_dest stderr log_type all connection_messages true log_timestamp true -
For all you guys running Home assistant and such... I see some are running in a docker and some in a VM and some in a VM on a separate machine.
HA in a docker seems fine except no supervisor. I'm no expert in HA (yet) but it seems I would like the supervisor ability. I tried @digiblur's video and I got it
to install and such.. but it seems kinda pieced together and it didn't seem too robust. I thank him for his effort here to give us that option though...
So I guess my question is.. what are the benefits of running in a docker vs a VM or just running it all (HA, ESPHome, MQTT, NodeRed) on a Rpi4?
I like the idea of a Rpi4 because if it breaks, it's pretty easy to replace the hardware fast. I'm planning on this setup controlling my whole HVAC system. So if something breaks, I need to be able to get it up and running quickly again. Does the Rpi4 just not have enough HP to run all this?
I suppose if I run in a VM on unraid I could always take the image and run it on another machine while I get unraid back up and running is something were to break? (assuming I could get to the image...)
What are most of you guys doing?
Thanks,
Jim
-
1 minute ago, H2O_King89 said:
I think the plugin fixed common things said there was a template update a while back
Sent from my Pixel 4 XL using Tapatalk
huh.. either I dismissed that warning.. or I never got it! :-)
-
Ok.. that was it.. It must have changed from when I first installed it. I changed the repo and now it looks ok...

Thanks for the help.





My Servers Early Access Plugin
in Announcements
Posted
Chrome
I tried that with the same result.
Sure.. I looked in the logs and saw nothing. This is the only spot were I get this. If I change the "Use SSL/TLS" to No.. That change happens just fine.. It's only if I muck with the "My servers" section.
Not sure what the update DNS is supposed to do? (generate a new certificate?) But that seems to not come back either.
tower-diagnostics-20210810-1401.zip