

jbuszkie
-
Posts
693 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jbuszkie
-
-
No... It's set to that..

-
5 minutes ago, spants said:
Is your repository set to nodered/node-red? and docker hub to https://hub.docker.com/r/nodered/node-red-docker/
I have not changed it ever as far as I know.. I'll check..
-
I get this now when I check for updates on my node red docker..

Is there a new docker for this or something?
Jim
-
Ok.. That fixed that one... But now I have this!

LOL...
-
Does anyone else see this issue?

-
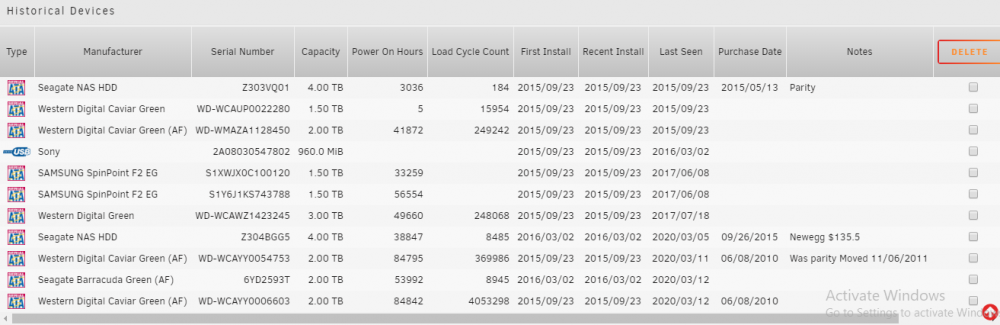
I'm moving over from the server layout plugin. First of all thanks for this plugin!
Second.. Is there a way to manually add a disk to the database? I really like the other plugin's "Historical Drives" section.
It kinda give me a history of what was installed and when it was removed.
-
Quote
You want your docker image on cache so your dockers won't have their performance impacted by the slower parity writes and so they won't keep array disks spinning. There is no reason to protect docker image because it is easily recreated, and it isn't very large so there is no good reason to not have it on cache and plenty of reason to have it on cache.
I guess when I first started using dockers I might not have understood completely how they worked. I also may not have had an SSD cache drive back then?
It make sense to move it to the SSD..
QuoteThere is no requirement to cache writes to user shares. Most of my writes are scheduled backups and queued downloads. I don't care if they are a little slower since I'm not waiting on them anyway. So, those are not cached. Instead, they go directly to the array where they are already protected.
I'll have to go back and see.. My guess is some of my shares can go directly to the array..
My DVR stuff and code/work stuff will stay on the cache/array method though...
I can probably change the mover to once a day... The SSD reliability is good enough that I don't have to be paranoid anymore. I do plan on upgrading to two 500GB NVME cards so I can have them in duplicate mode....
-
Does this plugin normally do more than one rsync at a time? My move seems to be nearly stalled....
This is moving to a SMR drive so I expect it to be slower.. but it seems to be crawling!
root@Tower:~# ps auxx | grep rsync root 7754 0.0 0.0 3904 2152 pts/0 S+ 08:33 0:00 grep rsync root 31102 8.4 0.0 13412 3120 ? S 07:55 3:08 /usr/bin/rsync -avPR -X T/DVD/MainMovie/FILE1 /mnt/disk8/ root 31103 0.0 0.0 13156 2308 ? S 07:55 0:00 /usr/bin/rsync -avPR -X T/DVD/MainMovie/FILE1 /mnt/disk8/ root 31104 9.7 0.0 13240 2076 ? D 07:55 3:38 /usr/bin/rsync -avPR -X T/DVD/MainMovie/FILE1 /mnt/disk8/ root@Tower:~#It did this yesterday too...
Thanks,
Jim
Edit: The sysylog doesn't show any obvious errors...
-
Quote
Not related but why do you have docker image on disk2 instead of cache?
I'm not sure.. It's what I did a while ago.. Maybe because I want it protected? Maybe because my Cache is only 250GB?
QuoteHow often do you have Mover scheduled?
It looks like every 4 hours.. Most of the time it doesn't run long. Crash plan runs at idle time (overnight).. And it seems to take a while to scan everything..
-
I don't see anything in the syslog..

Granted I have a pre-clear running now.. But I was getting these numbers yesterday without the pre-clear..
Edit: Pre-clear Pre-read @178MB/s right now...
-
50 minutes ago, civic95man said:
Is it slow during the entire transfer or starts fast and gradually/suddenly slows down?
Its my understanding that SMR drives leverage a CMR cache area to speed up writes but once it fills then any other writes slows to a crawl.
I'm copying big enough files that get past the cache pretty quick, I imagine.. one thing I noticed when I broke the unbalance into smaller chunks, was that the copy would be "finished" but the remove (rm) command took a while.... or like it was waiting for the disk to be ready again before it could start the next group..
-
53 minutes ago, trurl said:
Not sure why you might think that.
Grasping at straws?? 😄
I think the shingled drive might be my answer...
-
I think my issue might be the fact that my destination drive is an archive (Shingled?) drive? That might be killing my writes?
Jim
-
1 minute ago, sota said:
also what parity write strategy are you using? RMW or Turbo Write? the former would definitely be ugly.
My md_write_method is set to reconstruct write.
-
1 minute ago, johnnie.black said:
Then dual parity isn't the reason for the slower performance, assuming the parity2 disk is working correctly, most likely it's copying small files or from a slower disk region.
No... These are DVD VOB's pretty decent size..
I just upgraded a disk. It finished before I started the move.. Everything is green.. But I wonder if it's still trying to emulate the disk I upgraded...
Maybe I'll try a reboot.
Also, I started a docker upgrade (just recently after I noticed the slow move) and it's taking forever! The dash board said I'm about 50-80% cpu usage...
Extracting is taking forever...
Once that's done I'll try a reboot, I guess...
Jim
-
I even turned off my crash plan docker before I started it...
-
No this is a modern 4 core.. (8 thread) i7..
-
I just added a second parity disk. That went fine. Now I'm trying to empty a disk (using unbalance) so I can finally change the few riserfs's I have left.
Before dual parity, the move was about 30-45MB/s... Now with dual parity I'm hovering 13-15MB/s
Is this expected?
Thanks,
Jim
-
Bump.. I assume this hasn't been implemented yet? I'm rebuilding a data disk and I almost had to reboot the system (I think crash plan was bringing my system to a halt..) I was able to stop crash plan and the system started responding again.. But I'd love for it to remember where is was during a disk rebuild/parity check/Parity build...
Jim
-
6 minutes ago, Squid said:
You *can* however in the plugin's advanced settings set it to not stop the containers
That will work!! I didn't see the advanced settings! Thanks!
-
4 minutes ago, Squid said:
No. You have to do it manually if you want that
*pout* Not what I wanted to hear.. But what I expected to hear...
Thanks for confirming, Squid....
-
On 3/11/2020 at 9:37 AM, jbuszkie said:
Is there a way to just backup the flash drive? The appdata is (supposedly) getting backed up by crash plan. But The flash drive can no longer via crash plan.
So I'd like to use this to just back up the flash drive (then crash plan will backup the backup). I don't really want to stop all the dockers every time I want to back up the flash drive?
Bump...
-
11 hours ago, NitroNine said:
So I just ran this on disk 8 of my array (i first moved all the data off it to the other disks in my array), it completed (5TB drive so it took a while), I clicked Done. I then stopped the array, but when I went to tools>new config and checked all for Preserve current assignments, It didn't give me the option for apply, just Done. And I can't remove the drive from my array. I am using unraid 6.8.3 nvidia and don't have any parity drives at the moment.
Basically this drive is showing old, and before it starts to fail I want to remove it from the array, and replace it with a new 6TB drive.
Am I going about this the wrong way and/or is there an easier way for me to remove a drive from my array without any parity?
If you don't have any parity then you don't have to run this script. With the array stopped just pick no device for that slot and go with the new config keep current assignments.... as I understand it. Now I've never tried this with no parity drive assigned.. So maybe there is a bug there...
The whole Idea with the zeroing drive script is to keep parity valid while you remove a drive from the array. But you don't have parity so you should be able to just pull the drive.
You could also try "new config" without the preserve and just re-assign. Just make sure you take a picture or write down the current assignments so you can duplicate them...
What I did with the array stopped was to remove the drive from the list first, then I did the new config with preserve and it worked fine for me.
Jim
Edit: Now I see this was already replied to! Stupid browser not bringing me to the last message!
-
Quote
Having only 1 parity drive in parity2 works just fine,
That's what I was looking for...
Quoteit's a bit more complex mathematically, so the CPU works ever so slightly harder.
Very interesting and good to know.
I knew that the 2nd parity uses drive position.. But I didn't know that it was the Parity 2 slot.. not just a 2nd parity drive!






[support] Spants - NodeRed, MQTT, Dashing, couchDB
in Docker Containers
Posted
wait.. It's a little different..