




ctrlbreak
Members
-
Joined
-
Last visited
Everything posted by ctrlbreak
-
Yeah, I don't have diags from the time unfortunately :(. I did a clean restart from the web UI following the upgrade, which seemed to complete successfully. Those log line excerpts were from trying to bring up the transfer zfs pool after that restart. It's odd that there were no partition tables on the drives at all. I wonder if the original conversion from BTRFS to ZFS somehow never wrote them properly but they were in memory/kernel somehow? Don't know enough about ZFS to really understand... Anyway, maybe not useful in general, but thought I'd post my experience - especially as I was able to recover the data rather than have to reformat.
-
TL;DR: After converting a 2-device mirror pool from btrfs to ZFS (and upgrading to 7.2.7), the pool came up Unmountable: wrong or no file system on the first reboot. Root cause: both SSDs had lost their entire partition table, so sdX1 never appeared and ZFS couldn't find its labels, but every byte of data was intact. Fix was to rebuild the partition table at the exact original offset. Pool imported ONLINE, scrub clean, zero data loss. Posting in case it helps the next person, and to ask whether this is a known conversion/upgrade edge case. Environment Unraid 7.2.7 (kernel 6.12.90), ZFS 2.3.4 (upgrading from 7.2.0) Pool transfer: 2x Samsung 870 EVO 1TB, ZFS mirror, recently converted from btrfs First boot since the btrfs->zfs conversion Symptom GUI showed the pool device as Unmountable: wrong or no file system (fs type zfs). Syslog on array start: emhttpd: /usr/sbin/zpool import -f -m -N -o autoexpand=on (null) POOL-GUID transfer emhttpd: shcmd (155): exit status: 2 emhttpd: transfer: mount error: wrong or no file systemDiagnosis (all read-only) zpool import # state UNAVAIL, "insufficient replicas", both devices "invalid label" zdb -l /dev/sdX # labels 0/1 "failed to unpack"; labels 2/3 present but "Bad label cksum" blkid /dev/sdX # TYPE="zfs_member" on the WHOLE DISK - not on a partition lsblk /dev/sdX # no sdX1 child partition at all gdisk -l /dev/sdX # "MBR: not present / GPT: not present" - no partition table, no backup GPTThe giveaway: zdb showed the pool member was a partition (path: '/dev/sdX1', whole_disk: 0), but there was no partition table, so the kernel never created sdX1. ZFS labels were being read off the whole disk at the wrong offsets (front labels missing, end labels checksum-mismatched). The data was sitting there untouched, just no longer addressable as a partition. It only broke on reboot because the running kernel had held the partition layout in memory until then. Step 1 — find the original partition start (read-only) ZFS label L0 sits at the exact partition start, and its checksum only validates when read at the true offset. I didnt know the correct partition start, so looped over candidate start sectors, dd 256 KiB into a temp file, and zdb -l it: for S in 34 64 128 256 1024 2048 4096; do dd if=/dev/sdX bs=512 skip=$S count=512 of=/tmp/l0 2>/dev/null echo "sector $S:"; zdb -l /tmp/l0 2>&1 | grep -E "name:|Bad label|failed" doneA clean name: '<pool>' with no "Bad label cksum" = the real start sector. Mine was 2048. Then confirm the table format from a healthy drive (sgdisk -p /dev/<good-disk>) so the rebuild matches — GPT vs MBR, type code, and the last-usable sector (from gdisk -l). Step 2 — rebuild the partition (one mirror half first) #start = sector you found; end = last usable sector from gdisk -l sgdisk -n 1:2048:1953525134 -t 1:8300 /dev/sdX partprobe /dev/sdX zdb -l /dev/sdX1 # want: labels = 0 1 2 3Step 3 — read-only import to verify the data, then export zpool import -o readonly=on -R /mnt/verify -f transfer zpool status transfer # DEGRADED (one half) but "No known data errors" zfs list -r transfer # datasets + used space all present zpool export transferStep 4 — repeat on the second disk, import the full mirror, hand back to Unraid sgdisk -n 1:2048:1953525134 -t 1:8300 /dev/sdY partprobe /dev/sdY zdb -l /dev/sdY1 zpool import -o readonly=on -R /mnt/verify -f transfer zpool status transfer # both devices ONLINE, state ONLINE, no errors zpool export transfer Then Stop/Start the array so Unraid imports it normally, and run a scrub. Critical cautions Do NOT click Format on the unmountable device — that's the one button that turns this into real data loss. Import read-only first (-o readonly=on -R /mnt/verify) and verify your data before anything writes. On a mirror, rebuild and verify one disk before touching the second, so you always keep one untouched intact copy. The sector numbers above are specific to a 1 TB 870 EVO — find your own with the probe and gdisk -l. Recreating the GPT only writes the first/last few sectors; it does not touch the data region at 2048+. Resolution (confirmed) Pool imported ONLINE, both mirror halves, mounted at /mnt/transfer. Scrub completed in 00:10:21 with 0B repaired, 0 errors — every block verified across the mirror. Rebuilt partitions are real on-disk GPTs, so they persist across reboots. Net data loss: none. Open question for the community What in the btrfs->zfs conversion (or the 7.2.x upgrade) leaves pool devices with no on-disk partition table, surfacing only on the next reboot?
-
Force update sorted it - now 8.2.0 TRUNK. Odd that it wasn't showing an update available in docker. Thanks!
-
Hey Snoopy. I notice that LMS 8.1.x is now out but the latest container image from your repository seems to be on 8.0.1. Is this something we can manually update or do you have to create a new image? Thanks.
-
Update on this - I've done some more digging and it seems that the problem is exclusive to wav encoding in shairtunes, it's working fine on flac and mp3. Not sure if this is directly a shairtunes issue or a missing/incompatible enconding library, the logs don't seem to help, but will carry on investigating, but for now have it working
-
In host mode. And I've not changed that I don't think. It was definitely all working previously (for years!), so I'm not sure what I've done to mess it up, or whether it's some 8.0/config issue.
-
Thanks for your work on this docker Snoopy86 - I use it daily and did even contribute via paypal once! However, since the 8.0 update (I think - the timing seems to be right) I get errors when I try to send airplay from my phone to one of the players (using shairtunes2 plugin). The player gets all the metadata and tries to play the stream, but can't seem to connect back to the server. Have you seen this? I checked and the shairport is listening on the port that the player is trying to connect (I was surprised to see it uses a random port which isn't explicitly mapped in docker, but it seems to - and I can manually connect and retrieve the stream from a remote command line (using http). Any ideas? Thanks!
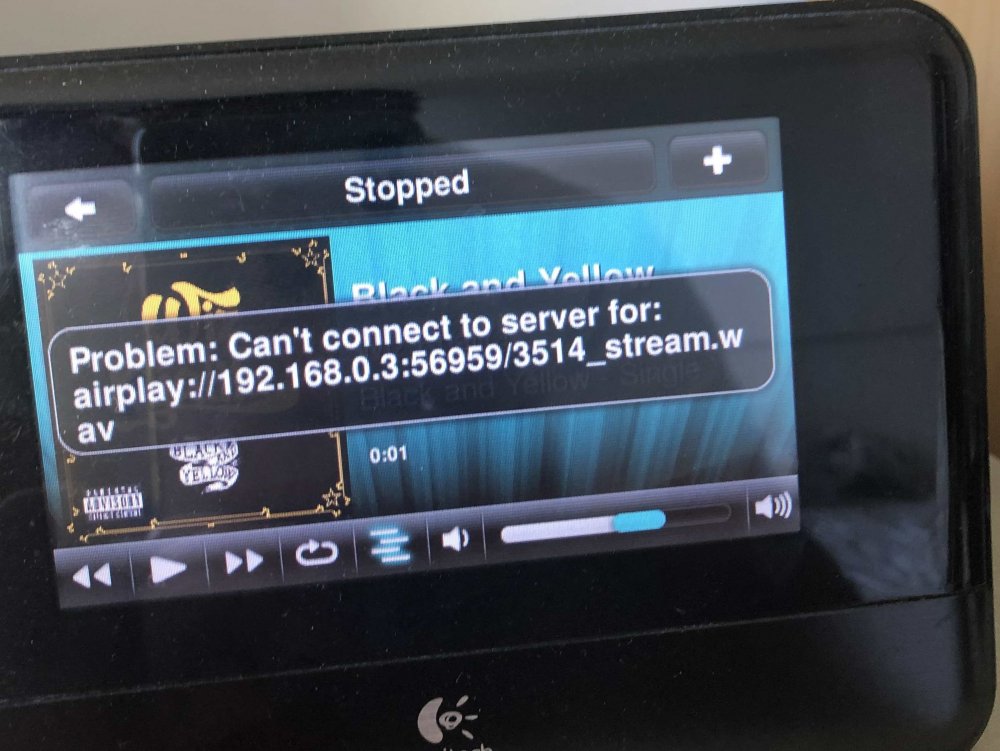
-
Seems that Plex now supports Linux HW decoding AND transcoding on Nvidia: https://forums.plex.tv/t/plex-media-server/30447/286 Will this work with unraid and docker passthrough? What drivers might be required?
-
Ah! Good point... I must have tried with only the old container. Intsalled from http://raw.github.com/disaster123/shairport2_plugin/master/public.xml and it's working great. Thanks! Now that is cool! Been meaning to send you a donation, snoopy. Donation sent! Yes, indeed. Beer donated, thanks Snoopy... Been trying to get this all working for a while
-
Ah! Good point... I must have tried with only the old container. Intsalled from http://raw.github.com/disaster123/shairport2_plugin/master/public.xml and it's working great. Thanks!
-
Hi Snoopy, Great work on these dockers - I recently migrated to your LMS docker from dfjardim's with no issues as I wanted the airplay integration, which is working well. I was also hoping to get airplay working the other way - using LMS as an airplay receiver. It seems that some good work has been done on a plugin that can do this: called Shairport2: https://github.com/disaster123/shairport2_plugin I've had a go at installing but can't seem to work out the dependencies. I was hoping you might be able to add it to your container? Cheers.
-
Thanks PsiCzar, I thought that might well help fix the problem. I was hoping someone might be able to identify the root cause of the issue, so I can understand it better and hopefully avoid it happening again.
-
Forgot to say, using 5.0-rc16c I think this directory may have been corrupt for some time though...
-
I had a directory with some corrupt files in them (a large, 10GB mkv file and some others). I believe they may have been corrupted for some time, as I've been unable to play them. Today I tried to delete the directory (with rm -rf), but kept getting told it wasn't empty. There was a syslog entry: Jul 14 21:23:20 bigboi shfs/user: shfs_rmdir: rmdir: /mnt/disk5/Films/xxx (39) Directory not empty When I went into the directory, I saw: ls -al total 7831015 drwxr-xr-x 1 root root 96 2013-07-14 21:23 ./ drwxrwxr-x 1 nobody users 15680 2013-07-14 21:23 ../ -rwxr-xr-x 1 root root 8011120201 2012-08-29 11:30 .fuse_hidden0000229400000011* When I then deleted the file and did another ls, I get a new hidden file: root@bigboi:/mnt/user/Films/Juno.2007.1080p.BluRay.DTS.x264-CtrlHD# rm .fuse_hidden0000229400000011 root@bigboi:/mnt/user/Films/Juno.2007.1080p.BluRay.DTS.x264-CtrlHD# ls -al total 7831015 drwxr-xr-x 1 root root 96 2013-07-14 21:23 ./ drwxrwxr-x 1 nobody users 15680 2013-07-14 21:23 ../ -rwxr-xr-x 1 root root 8011120201 2012-08-29 11:30 .fuse_hidden0000229400000012* Looks like perhaps the fuse file system has got into a corrupt/inconsistent state? Any ideas what's going on or how to resolve this issue?
