

jonfive
-
Posts
69 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by jonfive
-
-
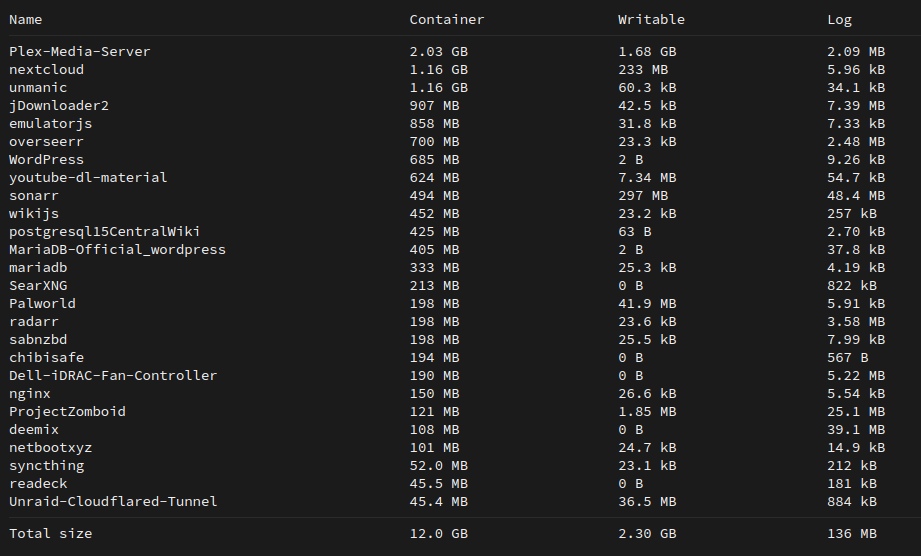
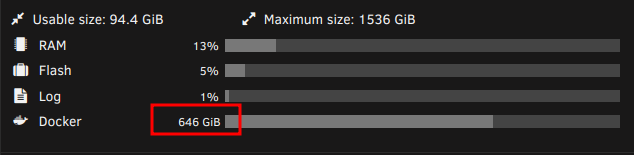
This is what i'm dealing with at the moment.
Anyone have any suggestions on what to change in some of these containers to try to reduce it's dockerimg size?
-
Someone passed this around a discord that i'm in and figured i'd share here given Debian usage. It was posted today Date: Fri, 29 Mar 2024 08:51:26 -0700
https://www.openwall.com/lists/oss-security/2024/03/29/4
Excerpt:
== Compromised Repository ==
The files containing the bulk of the exploit are in an obfuscated form in tests/files/bad-3-corrupt_lzma2.xz tests/files/good-large_compressed.lzma committed upstream. They were initially added in https://github.com/tukaani-project/xz/commit/cf44e4b7f5dfdbf8c78aef377c10f71e274f63c0
Note that the files were not even used for any "tests" in 5.6.0. Subsequently the injected code (more about that below) caused valgrind errors and crashes in some configurations, due the stack layout differing from what the backdoor was expecting. These issues were attempted to be worked around in 5.6.1:
https://github.com/tukaani-project/xz/commit/e5faaebbcf02ea880cfc56edc702d4f7298788ad https://github.com/tukaani-project/xz/commit/72d2933bfae514e0dbb123488e9f1eb7cf64175f
https://github.com/tukaani-project/xz/commit/82ecc538193b380a21622aea02b0ba078e7ade92
For which the exploit code was then adjusted: https://github.com/tukaani-project/xz/commit/6e636819e8f070330d835fce46289a3ff72a7b89
Given the activity over several weeks, the committer is either directly involved or there was some quite severe compromise of their system. Unfortunately the latter looks like the less likely explanation, given they communicated on various lists about the "fixes" mentioned above. Florian Weimer first extracted the injected code in isolation, also attached, liblzma_la-crc64-fast.o, I had only looked at the whole binary. Thanks! -
Just installed, love it. Is the 4gb container size normal? I've got everything pointing to /mnt/user folders
-
1 hour ago, Squid said:
Have you tried clicking "Container Size" on the docker tab?
we were looking into it on discord #containers
Turns out when it's using docker directory it reflects everything on cache.
I'm still going to nuke everything and start clean given i won't lose data -
Just now, jonfive said:

-
-
i was thinking if i go into the console for any of the containers, i would've been able to see what it used *locally*. but it's showing me the entire cache.
Could i somehow get in as the docker user and start flipping through these directories?
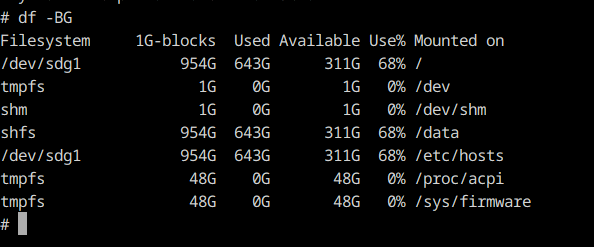
-
Alright. At one point or another, a container was exploding in size. I want to wipe out the entire docker directory and start over one by one to figure out which one had the problematic config.
my issue:I have a few instances of databases renamed for their own usage. How can i reinstall those?
Is there a better way of going about this than nuking it and starting over?
-
UPDATE:
It DOES work. Though, i need to test it's long term viability since there's complaints from people on the forum about i/o errors using scsiblock (see below)For this test, I created another usb with a trial license on bare metal, made a few folders and stuck some isos on it.
Installed proxmox, attached the usb device, set first boot to that usb device.Ran the below qm set line.
Started the vm, disk showed up correctly, pre-placed in the right disk# slot without showing "missing".
Opened the 6.11 file manager, disk 1, files were there.
qm set vm# -scsi# /dev/disk/by-id/YourDiskInformation,scsiblock=1
Without scsiblock, it just shows up as a qemuharddisk, so it's necessary for the time being.
The particular part of the proxmox docs that mentions the scsiblock potential issue:
Quotescsiblock=<boolean> (default = 0)
whether to use scsi-block for full passthrough of host block device
! can lead to I/O errors in combination with low memory or high memory fragmentation on host
If anyone has any further information or knowledge on how high/low memory fragmentation occurs in unraid, that'd be handy")
-
Timestamped - if it doesn't work, 9:08
This virtualized truenas video is the most closely representative of unraid drive usage that i could find for passing through individual drives without the entire controller.
I'm not really looking to pass through the whole controller, as i want remaining drives to be accessible to proxmox. (my unit uses a sas expander, so i'm sorta stuck).
TLDW:
He sorta did stubbing like we would to pass a gpu through, but with the sda/sdb/sdc etc into proxmox's virtIO SCSI by id
So, lsbk to list the drives with model/serial and attach them to the unraid VM's scsi controller.
In my case, this would be the drives that i would potentially pass to the unraid VM's virtio scsi controller.ata-SanDisk_SDSSDH3_1T02_211135801590 ata-WDC_WD80EFBX-68AZZN0_VGKJ451G ata-WDC_WD80EFBX-68AZZN0_VGKJ5H3G ata-WDC_WD80EFBX-68AZZN0_VGKJD86G ata-WDC_WD80EFBX-68AZZN0_VYGAZANM ata-WDC_WD80EFBX-68AZZN0_VYGAZYMM
For those with some experience virtualizing unraid, is this a viable solution?
*added later* I have a new server coming tomorrow, i think i'll grab an unraid trial license and my cold spare, put some data on it, swap to proxmox and try passing that drive directly to unraid vm to see if it can 'remember' it. If it does work, i'll drop an update. -
goes through almost all the cores with this:
PU: 3 PID: 25051 Comm: find Tainted: P D W O 5.15.46-Unraid #1
Can't really make sense of it all.
If you can decipher it, diagnostics attached.
thanks folks. Going to reboot before it fills up and crashes. -
Hey all, been looking up and down the forum looking at solutions to the permissions issues for containers.
Does anyone know if this is on the list of future fixes? Or is it a difference in the way that dockers will need permissions assigned going forward?
I briefly updated to 6.10.1 from 6.9.2, was also hit with permissions issues and rolled back.
Has there been a consensus on the proper solution to give them the 'correct' permissions? I've seen many posts of chmod's and changing owners. -
On 5/23/2022 at 3:10 PM, JonathanM said:
Tools, diagnostics, attach the zip to your next post in this thread.
gah, sorry it took so long to get back to you. things just got crazier. shucked seagates are the bane of my existence

Disregard this whole thing.. in the middle of just copying off remaining files disk by disk to new wd nas drives and replacing the entire array on 6.10. Only ended up losing a few tb, of which are 100% replaceable.
thank you SO much for all your efforts here. you guys are really the stars of the show
-
1 minute ago, JonathanM said:
Which means the replacement will be unmountable as well. Parity, if valid, will rebuild the drive as it is, with whatever corruption is present. Parity doesn't hold files, it works with the entire partition, file system included, so if the file system is corrupt that's what parity will rebuild.
When did that disk become unmountable?
Just as i rebooted. i think i just did too many things at once all willy-nilly
-
I got ahead of myself, wasn't grasping what i should be doing and went ahead with new config. It wanted to erase parity disk which didn't seem right so i rebooted.
I had a flash backup with the original config and loaded that. The disk i wanted to replace is 'unmountable' at the moment, which isn't really an issue because it's going to be replaced and recent parity check was good.
I have the new disk ready to go, listed in unassigned devices.
At the moment, it's going through a parity check. Can i cancel that check?
And just so i don't mess up again:1. Stop array
2. De-assign the disk i want to remove3. Assign the disk that will be replacing that one in the same slot.
4. Start array
Correct? or am i messing up
Thanks a ton folks!
-
Hey, fix for ffmpeg and other installables -
Add Debian (or whatever user you chose) to the sudo group and restart.su to get to root, password Docker! by default.
usermod -a -G sudo Debian (or whatever username)
restart the container
you can install stuff now
These steps from login and opening a terminal:su Docker! usermod -a -G sudo Debian
ps: I'm not sure if you've set the Debian user password at the start, but i changed mine right away after switching to root.passwd Debian password
-
23 minutes ago, jonfive said:
that's awesome.
I seem to have an issue with this particular set of avi's
It processes very fast, looks like it completes and immediately gets grabbed by the worker again and continues to count up
(img)trying to reproduce, but it seems like it's a one-off for some reason. I re-ran the whole folder once again and it didn't do this once and completed successfully
-
that's awesome.
I seem to have an issue with this particular set of avi's
It processes very fast, looks like it completes and immediately gets grabbed by the worker again and continues to count up
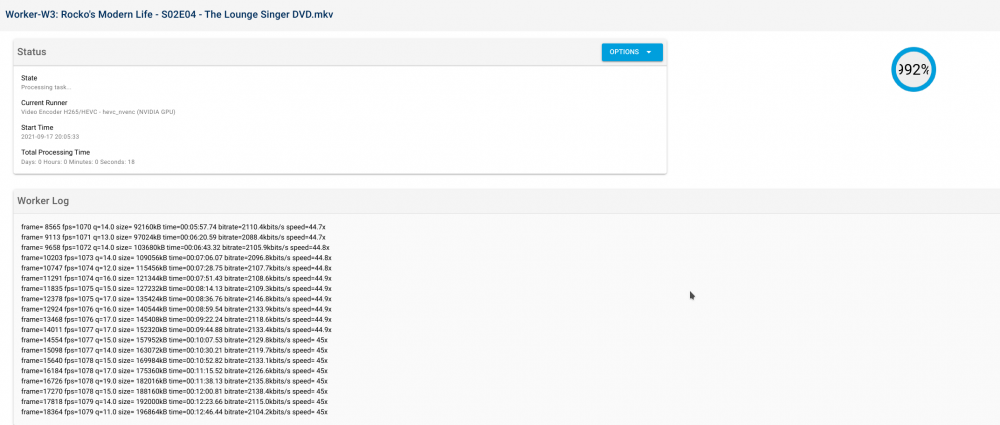
-
Are the default nvidia hevc settings in the plugin the same as the old version's defaults? I'd like to keep the quality consistent if at all possible
-
Is it at all possible to add a "custom" library to watch?
If i were to add another path in the docker config would i be able to select it within unmanic as an additional library - or would that have to be intended in the software to begin with? -
20 hours ago, brownkurts said:
I am having the same issues. It will run just fine for a few hours then max out my ram and cpus. I have 128gb ram and 24 cores with the cpus.
out of curiosity, take a look at the logs. Search for: audio streams (ac3) do not match
For me, when it would fail to convert ac3 to aac, it would hammer the cpu continuously as it was just converting audio, failing and sending it back to the queue again. Perhaps yours was failing to convert ac3 as well?
If so, disable audio transcoding for the time being. that's helped me. -
21 minutes ago, Jurak said:
Hello
I am having the issue where its running through everything that has already been converted. Its filling up the share the temp transcode folder. Also just noticed that its not actually transcoding anything.
that was happening to me earlier in the thread. it was failing to convert ac3 to aac - if you look in your unmanic.log for
the current file's audio streams (ac3) do not match the configured audio codec (aac or whatever you set it to)
you'll see that those files just keep going through. I only got it to stop by disabling audio conversion until it's figured out.
Not a huge deal though, once it's fixed i'll just re-enable it and let it run through the library again -
i've been just messing around with it. I completely removed/reinstalled unmanic (backed up the old unmanic appdata folder just incase you need something from it).
Taking a closer look at the old logs previously sent, it kept cycling through trying to convert ac3 to aac, unsuccessfully i assume.
Same file:
2021-01-29T18:59:39:DEBUG:Unmanic.FFMPEGHandle - [FORMATTED] - The current file's audio streams (ac3) do not match the configured audio codec (aac)
2021-01-29T19:01:06:DEBUG:Unmanic.FFMPEGHandle - [FORMATTED] - The current file's audio streams (ac3) do not match the configured audio codec (aac)
-
1 minute ago, Josh.5 said:
The unmanic.log file would help. Enable debugging beforehand.
unmanic.log
sorry it's rather large from all the restarts to trigger a scan.







Suggestions to reduce container size
in Docker Engine
Posted
Awesome! Just seeing what you've got running and their average size in comparison helped a lot. Perhaps another 10 gigs would be useful. The notification 'docker image is almost full' gets me nervous, I've made that mistake before and it filled up SUPER fast.
My plex is a little big, but i have all the bells and whistles turned on with a sizable library. I just need to get in my head, some dockers are just *big*.