

rowid_alex
-
Posts
43 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by rowid_alex
-
-
36 minutes ago, trurl said:
No SMART for parity in those. Check connections and post new diagnostics.
Hello I reboot the server and this time parity disk has SMART data.
I found flag 0x000a UDMA CRC error count added one permanently. But everything else seems fine.
0x06 0x018 4 1 --- Number of Interface CRC ErrorsPlease kindly suggest what should I do to enable the disk.
Thanks!
-
Just now, JorgeB said:
SMART is still available for disable disks, but parity dropped offline, so there's no SMART, you should check/replace cables to rule since that looks more like a connection problem and them and post new diags.
Understood. I will check the cable then. Thanks for the explaination.
-
1 minute ago, trurl said:
No SMART for parity in those. Check connections and post new diagnostics.
My understanding is that since the disk is disabled so SMART is not available. Should I restart the array to get SMART back?
-
Hello guys,
I just found my parity disk sdf has been disabled since midnight.
Here are the syslogs:
May 24 00:53:29 UNRAID kernel: ata6.00: exception Emask 0x10 SAct 0x1c00000 SErr 0x400000 action 0x6 frozen May 24 00:53:29 UNRAID kernel: ata6.00: irq_stat 0x08000000, interface fatal error May 24 00:53:29 UNRAID kernel: ata6: SError: { Handshk } May 24 00:53:29 UNRAID kernel: ata6.00: failed command: WRITE FPDMA QUEUED May 24 00:53:29 UNRAID kernel: ata6.00: cmd 61/40:b0:40:4c:af/05:00:ca:01:00/40 tag 22 ncq dma 688128 out May 24 00:53:29 UNRAID kernel: res 40/00:00:d0:55:af/00:00:ca:01:00/40 Emask 0x10 (ATA bus error) May 24 00:53:29 UNRAID kernel: ata6.00: status: { DRDY } May 24 00:53:29 UNRAID kernel: ata6.00: failed command: WRITE FPDMA QUEUED May 24 00:53:29 UNRAID kernel: ata6.00: cmd 61/50:b8:80:51:af/04:00:ca:01:00/40 tag 23 ncq dma 565248 out May 24 00:53:29 UNRAID kernel: res 40/00:00:d0:55:af/00:00:ca:01:00/40 Emask 0x10 (ATA bus error) May 24 00:53:29 UNRAID kernel: ata6.00: status: { DRDY } May 24 00:53:29 UNRAID kernel: ata6.00: failed command: WRITE FPDMA QUEUED May 24 00:53:29 UNRAID kernel: ata6.00: cmd 61/40:c0:d0:55:af/05:00:ca:01:00/40 tag 24 ncq dma 688128 out May 24 00:53:29 UNRAID kernel: res 40/00:00:d0:55:af/00:00:ca:01:00/40 Emask 0x10 (ATA bus error) May 24 00:53:29 UNRAID kernel: ata6.00: status: { DRDY } May 24 00:53:29 UNRAID kernel: ata6: hard resetting link May 24 00:53:39 UNRAID kernel: ata6: softreset failed (1st FIS failed) May 24 00:53:39 UNRAID kernel: ata6: hard resetting link May 24 00:53:49 UNRAID kernel: ata6: softreset failed (1st FIS failed) May 24 00:53:49 UNRAID kernel: ata6: hard resetting link May 24 00:54:24 UNRAID kernel: ata6: softreset failed (1st FIS failed) May 24 00:54:24 UNRAID kernel: ata6: limiting SATA link speed to 3.0 Gbps May 24 00:54:24 UNRAID kernel: ata6: hard resetting link May 24 00:54:29 UNRAID kernel: ata6: softreset failed (1st FIS failed) May 24 00:54:29 UNRAID kernel: ata6: reset failed, giving up May 24 00:54:29 UNRAID kernel: ata6.00: disabled May 24 00:54:29 UNRAID kernel: ata6: EH complete May 24 00:54:29 UNRAID kernel: sd 6:0:0:0: [sdf] tag#26 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=0s May 24 00:54:29 UNRAID kernel: sd 6:0:0:0: [sdf] tag#26 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00 May 24 00:54:29 UNRAID kernel: blk_update_request: I/O error, dev sdf, sector 0 op 0x1:(WRITE) flags 0x800 phys_seg 0 prio class 0 May 24 00:54:29 UNRAID kernel: sd 6:0:0:0: [sdf] tag#27 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=60s May 24 00:54:29 UNRAID kernel: sd 6:0:0:0: [sdf] tag#27 CDB: opcode=0x8a 8a 00 00 00 00 01 ca af 5b 10 00 00 01 70 00 00 May 24 00:54:29 UNRAID kernel: blk_update_request: I/O error, dev sdf, sector 7695457040 op 0x1:(WRITE) flags 0x0 phys_seg 46 prio class 0 May 24 00:54:29 UNRAID kernel: md: disk0 write error, sector=7695456976I referred some threads in the forum. And I am not sure if I should stop array and to rebuild the parity disk with the same hard disk or not.
Please kindly help check. Diagnostic file is attached.
Thanks a lot!
Alex
-
49 minutes ago, nikizm said:
Hi Jonny,
Is there a way to force update the image? I check for updates but none are available. This is killing access to all my dockers from outside the network!
Alternatively, is there a way to revert to an old version?
I had the same problem and find the way to fix it.
Go to UNRAID docker page, change the view from basic to advanced with the button in the up-right corner, then you will see there is a "force update" for every docker container. Force update letsencrypt and issue is resolved!
-
21 hours ago, bastl said:
@rowid_alex Go to your nextcloud webinterface and as said earlier, login with an admin account and check if an update is available. It should show your current version and available updates. The nextcloud itself has to be updated inside the container.
Übersicht = overview or whatever language you are using.
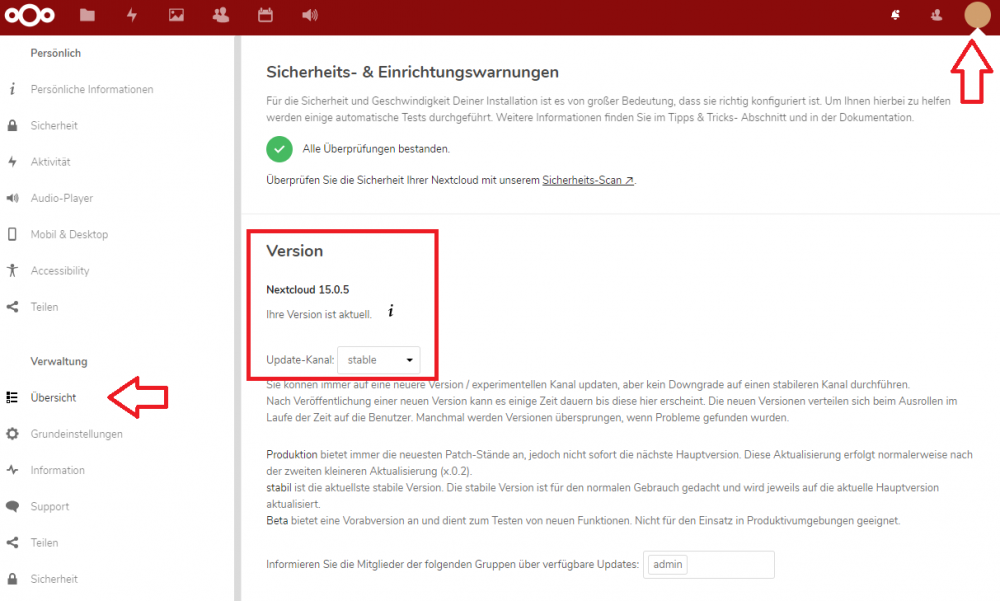
Thanks! I thought this will be updated via docker container. I successfully upgraded to 15.0.5 now.
-
1 hour ago, bastl said:
The docker container I always keep up to date and from time to time I check nextcloud with an admin account if any update is available. 15.05 I got a couple days ago, hit the update button, done. No special procedure. Check for an update with an Admin account in the settings section "overview", download it and install it. If everything works, the updater shouldn't show any errors. If you have issues, post the output of the updater. @rowid_alex
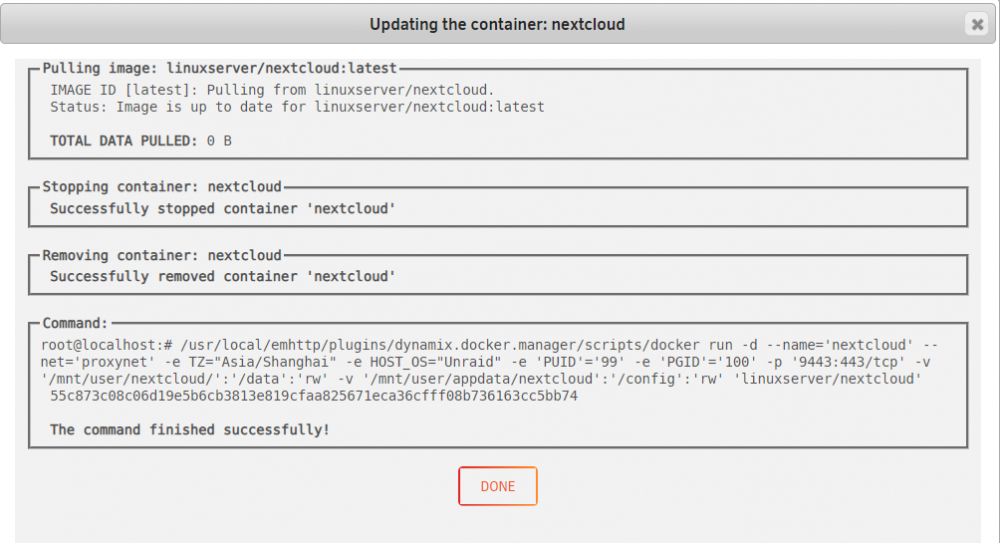
Thanks. I just got the update this evening so this time I tried to use "force update" function in advanced view to update the nextcloud container and the updater said it is up-to-date. So nothing is changed. I am still in 14.0.3 however...
-
Hello, I see people mentioning nextcloud 15.0.5. My docker container recently shows upgrade for this nextcloud a couple of times. But after the upgrade I see I still at 14.0.3. May I know how to upgrade to 15.0.5 as your guys?
Thanks!
-
13 minutes ago, johnnie.black said:
thanks! so it is same as raid6.
-
Just now, johnnie.black said:
Yep.
thank you!
-
8 hours ago, jonathanm said:
One more small thing. Parity slot 2 is calculated completely differently. Net result is that now your disks must stay assigned to the same slot numbers to keep parity valid. If you at some point decide you don't like parity 1 being empty and parity 2 occupied, you will have to rebuild parity 1, either by adding it, or breaking parity and running unprotected for the duration of the build.
thanks. may i know what exactly how the algorithm to calculated parity slot 2 is different than slot 1? personally i don't mind if parity disk is in slot 1 or 2, as long as I have one parity disk.
-
9 hours ago, johnnie.black said:
It will work, I would say there's a little more risk involved since you'll do two rebuilds, or to be more correct, one sync and one rebuild, with a degraded array, to be successful both will need all the other disks to not fail, but as long as everything is healthy you should be fine.
ok. what you mean is:
for parity-swap it contains:
- one parity copy from old parity disk to new disk (this only needs the old parity disk healthy, other than all other disks healthy, since the array is offline)
- one data rebuild afterwards (this requires all disks healthy)
for what I did via parity disk 2 it needs:
- one parity sync for parity disk 2 (this needs all disks healthy)
- one data rebuild afterwards (this needs all disks healthy as well).
is my understanding correct?
-
here the thing:
i have array with parity drive 5TB and data drive 5TB+1.5TB+1.5TB.
a few days ago the 5TB data disk drive failed and I sent it to vendor for RMA.
in the same time i bought two new 8TB drives and want to replace both the failed data drive and the parity drive.
i found out
- i cannot replace the failed data drive with 8TB drive since the new drive 8TB is larger than the current parity drive 5TB.
- of course i cannot replace the parity drive with the new drive directly since there is no way to rebuild the data
unraid suggests to check "parity-swap" procedure so I found it in wiki:
https://wiki.unraid.net/The_parity_swap_procedure
my understanding is that
- I have to swap the old parity disk to the missing data drive entry, then replace the parity disk with my new drive.
- then execute a "parity copy" to copy the parity data from the old parity disk (in data disk entry) to the new parity disk (in parity disk entry)
- once parity data is copied, start the array will rebuild the data in data disk entry.
however i archived with a different way by parity 2 disk since i don't have double parity disks:
- add the pre-cleared 8TB disk to parity 2 entry
- start array and sync the parity data
- once parity 2 disk is ready, stop the array and remove the 5TB parity 1 disk in the configuration and start array again, this removes parity 1 disk from the configuration completely
- stop the array, now I have a parity disk replaced with a larger 8TB disk in parity disk 2 entry.
- add the new 8TB disk into data disk entry
- start the array and rebuild the data.
my questions are
- if my procedure is recommended?
- if any advantage to use parity-swap procedure than my above procedure?
thanks!
Best Regards,
Alex
-
I am searching for thunderbolt 3 support recently in the forums and found most of the answers are "No", except this case:
The poster used a thunderbolt 2 enclosure for the drives and it is working properly with unraid release before (except the booting issue he addressed).
Wondering if anybody tried any thunderbolt 3 external drive enclosure with TB3 device (e.g. intel NUC) actually?
I found the following information in egpu.io:
since in unraid 6.5.2 we are already at Linux Kernel 4.14, and should include the following patch for TB3 security control:
https://lkml.org/lkml/2017/5/26/432
does it mean unraid support eGPU already by:
$sudo sh -c 'echo 1 > /sys/bus/thunderbolt/devices/0-1/authorized'
like this topic:
https://egpu.io/forums/pc-setup/egpu-in-linux-has-anyone-here-gotten-it-to-work/
does anyone ever test it?
-
since in unraid 6.5.2 we are already at Linux Kernel 4.14, and should include the following patch for TB3 security control:
https://lkml.org/lkml/2017/5/26/432
does it mean unraid support eGPU already by:
$sudo sh -c 'echo 1 > /sys/bus/thunderbolt/devices/0-1/authorized'
like this topic:
https://egpu.io/forums/pc-setup/egpu-in-linux-has-anyone-here-gotten-it-to-work/
does anyone ever test it?
-
 1
1
-
-
6 hours ago, gridrunner said:
There can be a problems with AMD GPU reinitialization sometimes, seems like the card isn't resetting correctly leaving the GPU in an initialized state when shutting down osx. Does the same happen if you shut down the windows VM then try and start the OSX VM? Or is it only when going from osx to windows?
When I switch from Windows VM to another Windows VM, it could happen, let's say once in ten times or 15 times.
When the issue happening, usually you just cannot boot the VM and of course you didn't see any output in the monitor as well. (if I use the vbios I might be able to see the UEFI BIOS logo, haven't tried it yet). The worst case, is that the fan of the graphic card is running to its max speed all the time, even after restart the unraid machine. I couldn't boot any VM as the card is not in the system device even. The only way to recover is to shutdown the tower and boot it up again. This occurs, not seldom, but also not often as well.
When I switch from Windows VM to macOS, just like switch from Windows to Windows above, usually it is fine. But there is no way to switch back to Windows VM anymore. With vbios I could see the UEFI BIOS logo then, the monitor starts to display some color blocks, very similar like if you overclocked too much for the GPU memory. Then the boot is stuck. However, it is totally not a problem, if I switch from macOS VM to another macOS VM or I start up the same macOS VM again.
-
3 hours ago, gridrunner said:
Make a Linux VM and try shutting that down then starting a window VM. Also, try passing through the vbios file see if that helps. Easy to do in 6.5 now.
tried vbios file, which helps me to get the boot order screen before booting macOS, quite nice, but it doesn't resolve the problem for switching back to Windows.
uses the vbios file for Windows VM as well. Once used macOS then switch back to Windows VM. I can see the UEFI bios logo, then the screen output become a mess afterwards.
still have to reboot the machine to let the graphic card works again.
-
Yesterday I made little progress with it. I added AppleALC and Lilu kext files into clover EFI partition, which fixed my RX480/580 recognition problem (previously R9 xxx, now RX580 4GB) and also the performance benchmark is back to normal. Now if I shut down the macOS and start up a Windows VM, there is no more one CPU looping 100% but looks more normal start up behavior, however, GPU still doesn't send the display any output yet.
I am feeling this is a kind of hackintosh problem instead of KVM itself...
-
Hello I see others have issue in old release (6.2.4) that macOS is only able to boot once:
But this is not my case. I can boot other macOS VMs after shutting down macOS VM. The only issue is that I cannot boot any Windows VM anymore (with the same graphic card), unless I reboot the unRAID server... This should be related to the graphic cards, because it is totally not a problem if I don't passthru the GPU but use VNC to access macOS.
-
10 minutes ago, Hoopster said:
Yes, the iGPU needs to be specified as the primary graphics adapter in your BIOS and not passed through to a VM. Unless it is the primary graphics adapter (don't choose AUTO if that is an option in the BIOS), the drivers don't get loaded to allow the Plex docker to access QuickSync Video for transcoding.
Thanks! I also found out if I choose AUTO in the BIOS, then iGPU is not loaded at all by unRAID, it seems just ignore it. I have to choose CPU GPU option to let it recognized by unRAID.
-
17 hours ago, HellDiverUK said:
I would assume so, yes.
I have an AMD RX480/580 gpu (passthru-ed) and 4790K iGPU. If I want to use hardware transcode in plex docker, does it mean I have to enable iGPU and leave it to unRAID itself and not pass it thru to any VM, right?
-
Hello,
I am on unRAID 6.5.0 and use it for sometime without any big issue. Last week I followed @gridrunner's spaceinvader guide and set up the macOS high sierra virtual machines which work perfectly with my RX480/580 passthrough as well . After a couple of days I found out one problem, which is a bit annoying:
I am using the single GPU (Sapphire RX480/580 4GB) to passthru to all my VMs since I am not using them together. The cards works well both on Windows 10 VMs and macOS VMs.
However I do notice that as soon as the card has been passed thru to the macOS virtual machines once, I am not able to boot Windows virtual machines with the same card anymore (after shutting down macOS VM). The Windows VM just couldn't boot, and one CPU is looping with 100% usage all the time. Instead, it is not a problem to boot another macOS VM (after shutting down macOS VM) with the same graphic card. It seems like the macOS VM did something to the graphic card and it doesn't like Windows anymore...
The workaround is simple, I just need to reboot the unRAID. As I am the only user for the server so it is not a problem for me at this moment, just annoying.
Does anybody has the similar issue? I am thinking to get another dedicate graphic card to macOS to resolve the issue if your guys have the same problem as well...
supplement:
macOS version: 10.13.3
Best Regards,
Alex
-
hello there,
i am using the unraid server (6.4rc-15e, 4790K/Z97/32GB) and passing through my amd rx480/580 gpu, use it for about 2 months now.
recently just notice that my rx480/580 memory clocks often locks at lowest state, which is 300MHz all the time since the windows starts.
of course it impacts the performance, especially for gaming.
it's easy to find it out. just run gpu-z and start rendering test and check if memory clock jumps up.
i have a workaround, to use cru-1.3.1 to soft reset the display driver then the memory clock is back to normal, that means when gpu has workload, its memory clock up to 1750MHz.
but it seems i didn't have the issue before. yes, of course I updated the graphic driver to the latest recently but I never get the issue in the physical machine running on the windows 10.
does anybody have the same issue?
Best Regards,
alex
-
On 11/13/2017 at 8:23 AM, steve1977 said:
I have two NVME drives. One is 1TB an one is 128GB. Currently, I am using the 1TB as cache disk (VM, very little docker use). I am currently not using the 128GB disk.
I am thinking to move the 1TB to US and instead use the 128GB as cache (and docker?). I am not clear though whether this would do any good?
I think you can assign 128GB NVMe SSD to cache disk too, just change the Btrfs to single mode. So this leverage the different size of SSDs.



Parity disk has been disabled, what should I do?
in General Support
Posted
BTW, I checked the location of the disk and it is connected to the SATA port on the motherboard directly. So it doesn't seems to be a cable issue...unless it happens the next time I think.