

Rich
-
Posts
268 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Rich
-
-
Did anyone get to the bottom of this? I’m shopping around for a CPU upgrade and had my eye on a 13700.
-
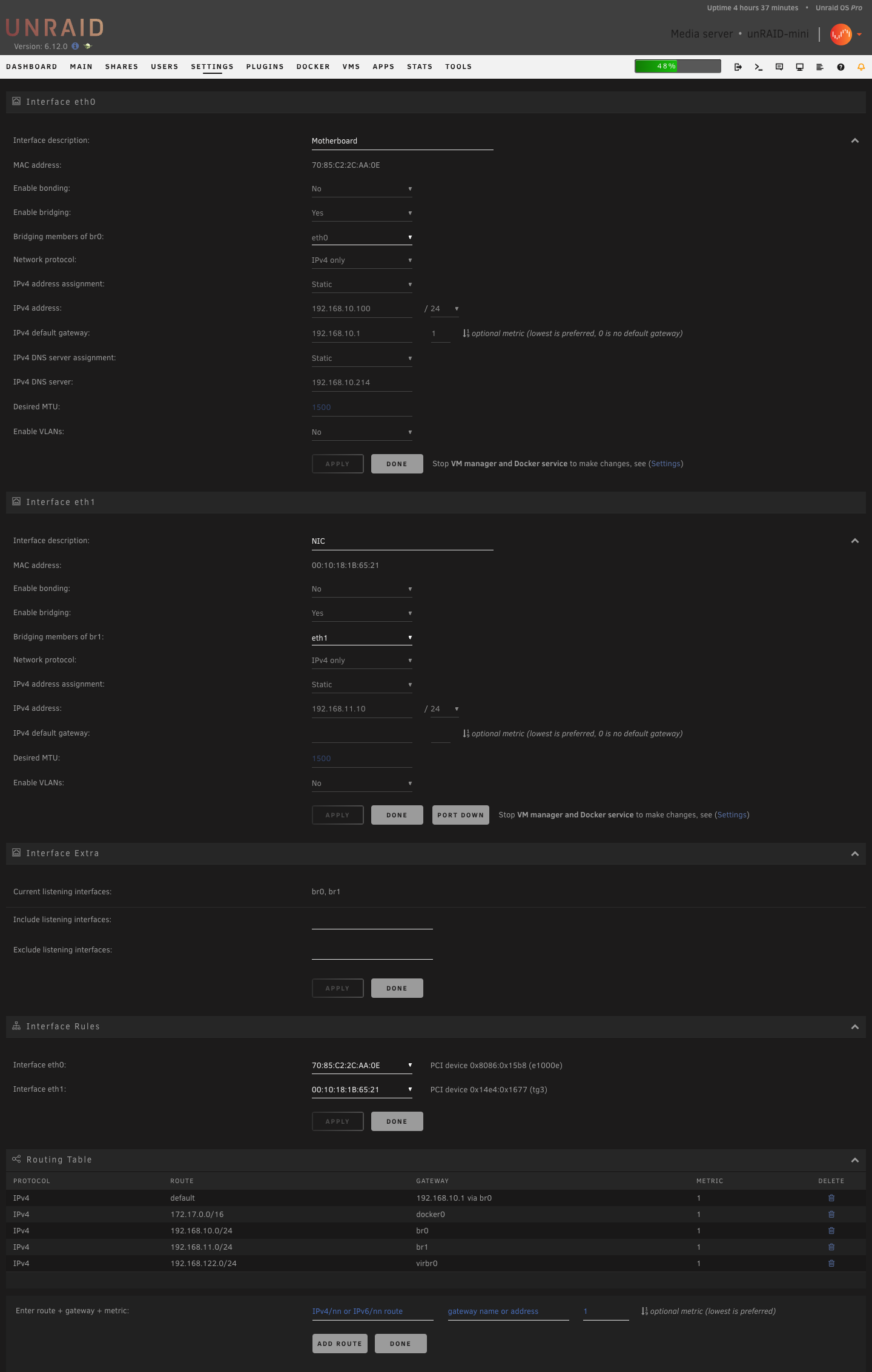
Understood. So DNS isn't passed through to br1, br1 simply uses the same DNS address that br0 has been set to. Assuming i've understood things correctly, i just need to add a firewall rule to allow my br1 network access to the DNS IP on br1. Thanks for your help.
-
That's what i had gathered from reading different posts; DNS is effectively passed-through / inherited from system level and not configured locally (eth1).
But why isn't is working in this case?
-
If i run, docker network ls
and then, docker network inspect xxxxxx on the bridge, none of the eth1 dockers appear in the list. Assuming this is why the dockers aren't getting DNS?
-
Ok, so i can now ping the gateway and 1.1.1.1 from the docker console connected to the NIC. What isn't working is pinging an address, e.g. google.com, which points towards a DNS problem. Is that likely, as i'd read that eth1 should use the DNS settings from eth0?
-
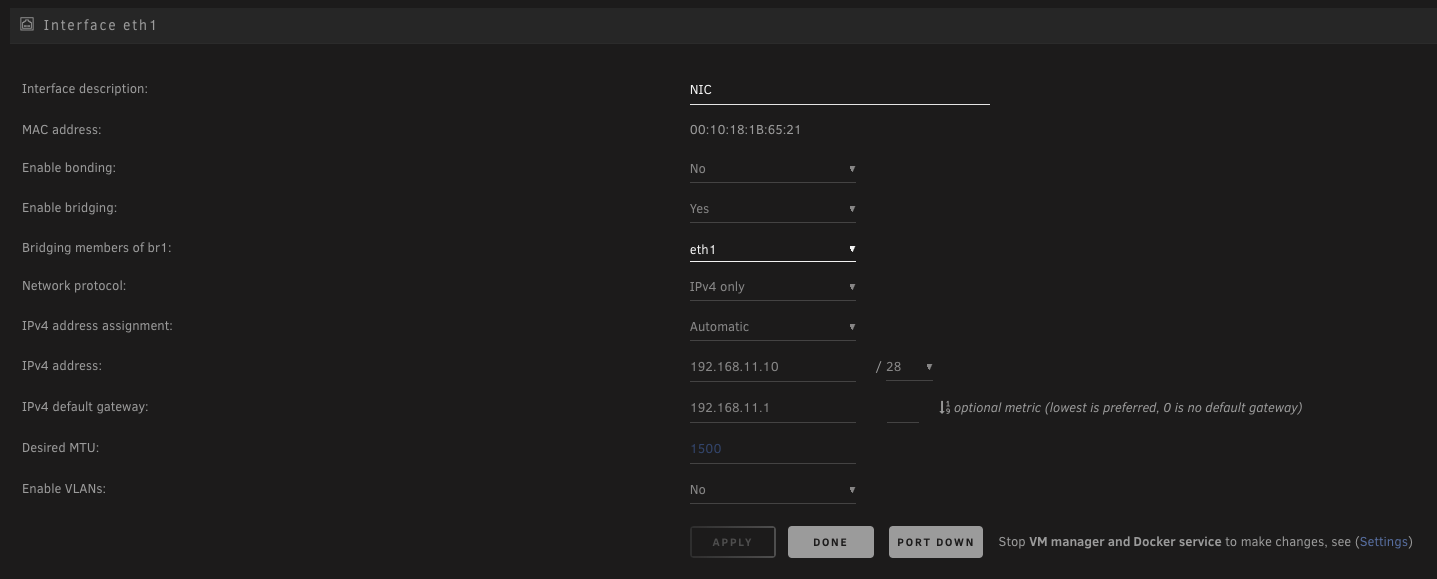
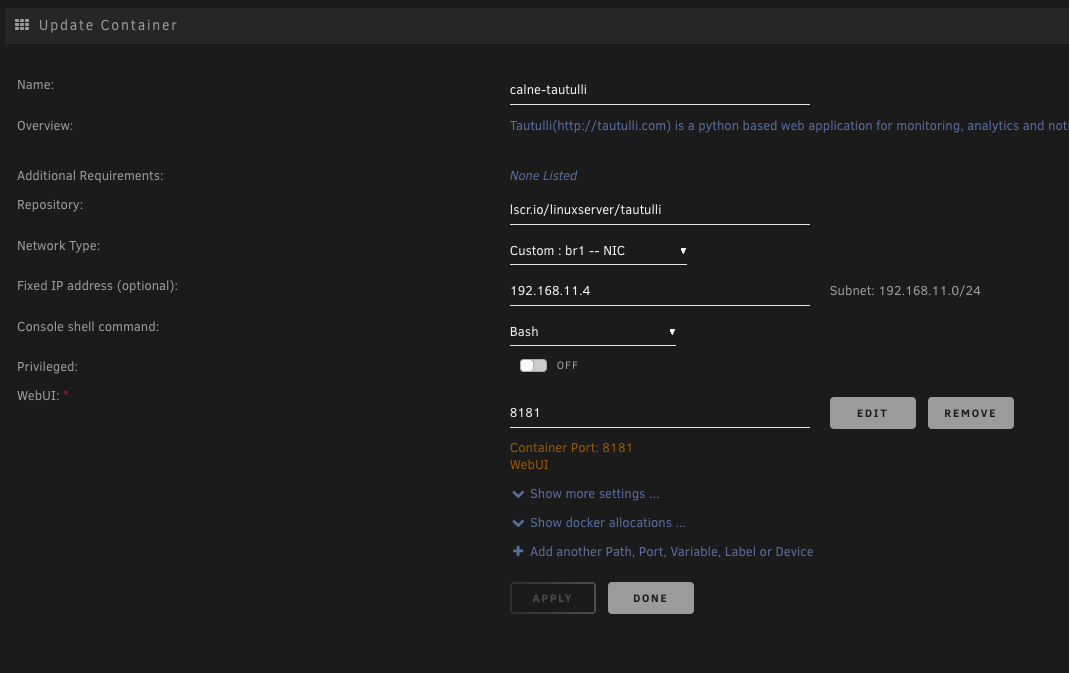
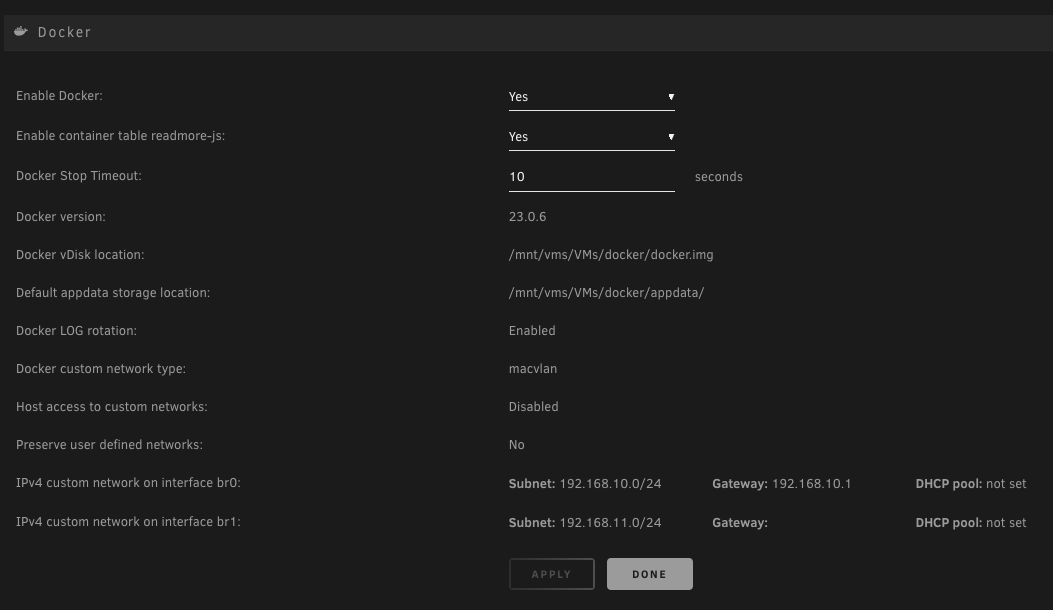
For clarity, what i am trying to do it add a NIC to the server, set it up as eth1 and then set 5ish dockers to use br1 so they can use the NIC to access a separate network and get internet access via the that network / eth1/br1. Is that actually possible?
The settings i have currently are as pictured.
From the Docker console, for a docker on eth0/br0 i can ping it's gateway and 1.1.1.1. For a docker on eth1/br1, with the pictured settings, i cannot ping it's gateway but can ping 1.1.1.1.
Really appreciate any help provided.

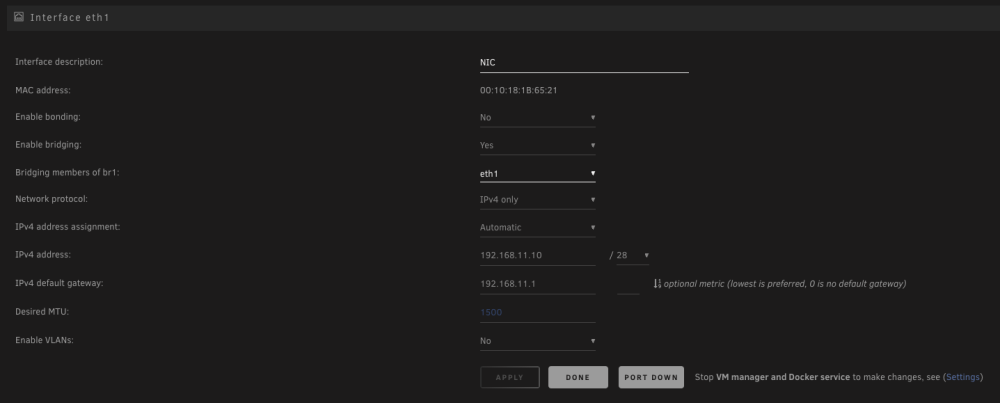
-
Tried again with and without a gateway for eth1 and still no luck. What am I missing?
-
Thanks for the reply. I'm confused at why other posts say the gateway should be empty? Also i have a UDM Pro setup with multiple subnets, the two in question are visible in the screenshots above. I started with the gateway populated and still no internet access for the dockers. I have triple tested that a laptop on the new subnet can access the internet, which it can, so it doesn't appear to be an issue with UDM Pro network settings.
-
I've just added a (working) NIC to my server to function at eth1, however after setting up and installing dockers on br1 i realised nothing on the network has internet access. I can ping from outside the network inward and from inside the network to other local IPs, however i am not able to get access out of the network. After a quick google i found results saying i needed to keep the gateway for eth1 blank in network settings, which i thin did, however no luck with outward access.
Settings are as below. Would really appreciate some pointers here as i've been at this for hours with no luck.
Thanks.

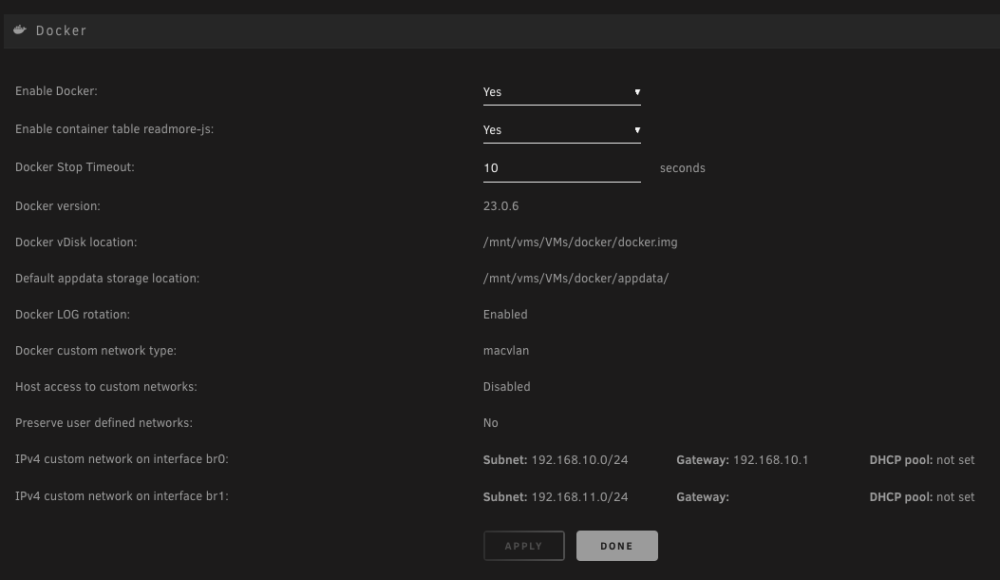
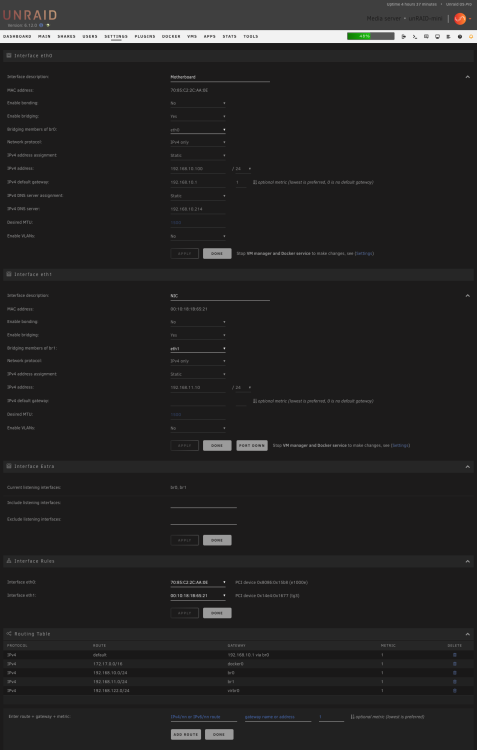
-
Hi there, is it possible to add netcat to the nerdtools plugin, please?
-
Is anyone able to help me out here, please?
-
It doesn’t appear in nerdtools, that’s why I’m installing it via the extra folder, on boot.
-
Would really appreciate some help with this one, please.
-
Would appreciate some help with this one: I have a bash script that runs, via User Scripts, each time the array is started to turn on a TP-Link smart plug. To get the script working i had to install the netcat pkg, which is now done automatically by placing the txz in flash/extra/. All worked well, however at some point over the last few weeks, the script stopped running and when i manually test i now get this error,
nc: error while loading shared libraries: libmd.so.0: cannot open shared object file: No such file or directoryI have seen a previous post HERE where a similar issue was fixed, but my understanding of Linux isn't good enough to be able to adapt the fix, if possible?
Can anyone give me some pointers? Thank you.
-
Ok, i'll focus on verifying that it's the disk. Thanks for your help.
-
So i moved the disk to a separate bay in the server with different data and power cables and 156 error occurred over night.
That says to me the disk is probably the issue, but as it passed the extended smart test and i'm not a pro on backplanes and expanders, should i consider anything else, or is the obvious indicator the one to go with here?
-
Will do. Thank you
-
The extended smart test came back as "Completed without Error", which surprised me.
The read errors are up to 2964 now. Does any of this indicate what the most likely cause could be?
Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 5 02:09:48 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#6594 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=6s Sep 5 02:09:48 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#6594 Sense Key : 0x3 [current] [descriptor] Sep 5 02:09:48 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#6594 ASC=0x11 ASCQ=0x0 Sep 5 02:09:48 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#6594 CDB: opcode=0x88 88 00 00 00 00 05 1d 0a 23 38 00 00 04 00 00 00 Sep 5 02:09:48 unRAID-mini kernel: blk_update_request: critical medium error, dev sdh, sector 21962041088 op 0x0:(READ) flags 0x0 phys_seg 7 prio class 0 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041024 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041032 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041040 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041048 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041056 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041064 Sep 5 02:09:48 unRAID-mini kernel: md: disk0 read error, sector=21962041072 -
Ok, will do. Thank you.
-
Hi All,
Since it's last reboot (100ish days ago) my server has been running without any problems (that i've noticed), until yesterday when I saw a few errors appear during it's monthly parity check.
During the parity check, i noticed that parity drive 1 had some read errors. The syslog showed the below, which i assume is referring to the disk errors. This has since occurred multiple times which has increased the error count on the main unRAID page to the current total of 1618 for parity 1.
I have THIS case, which i have been using since February this year, without any issues.
Appreciate that there are likely several potential causes, e.g. cables, backplane or hard drive, however before i start taking things apart to test, i wanted to post here and see if the error indicates one cause to be more likely than the others and if there could be any likely causes that i have not listed above.
Any help is greatly appreciated.
Thanks.
Rich
Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: mpt3sas_cm0: log_info(0x31080000): originator(PL), code(0x08), sub_code(0x0000) Sep 1 14:20:01 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#9374 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=11s Sep 1 14:20:01 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#9374 Sense Key : 0x3 [current] [descriptor] Sep 1 14:20:01 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#9374 ASC=0x11 ASCQ=0x0 Sep 1 14:20:01 unRAID-mini kernel: sd 2:0:5:0: [sdh] tag#9374 CDB: opcode=0x88 88 00 00 00 00 02 ce 67 06 70 00 00 04 00 00 00 Sep 1 14:20:01 unRAID-mini kernel: blk_update_request: critical medium error, dev sdh, sector 12052793040 op 0x0:(READ) flags 0x0 phys_seg 116 prio class 0 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052792976 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052792984 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052792992 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052793000 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052793008 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052793016 **** edited for length as also in attached syslog **** Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052793888 Sep 1 14:20:01 unRAID-mini kernel: md: disk0 read error, sector=12052793896 Sep 1 14:21:01 unRAID-mini sSMTP[20478]: Creating SSL connection to host Sep 1 14:21:01 unRAID-mini sSMTP[20478]: SSL connection using ECDHE-RSA-AES256-GCM-SHA384 Sep 1 14:21:02 unRAID-mini sSMTP[20478]: Sent mail for ********** (221 2.0.0 csmtp7.tb.ukmail.iss.as9143.net cmsmtp closing connection) uid=0 username=root outbytes=797unraid-mini-diagnostics-20210902-1536.zip unraid-mini-smart-20210902-1531.zip
-
/usr/local/bin seems to be the better location for macOS BigSur, due to System Integrity Protection on /bin.
-
 2
2
-
-
10 hours ago, ryoko227 said:
Most likely what is happening is that efi-framebuffer is being loaded into the area of memory that the GPU is also trying to use when unRAID is booted in UEFI mode. This thread explains the who, how, what, why and how to fix it if your issue is the same as mine was.
Thanks for the heads up ryoko. I gave the three commands a shot and it did sort out the syslog flooding, but sadly didn't solve the single thread at 100% or allow the VM to boot, so looks like i'll be continuing with UEFI disabled for the moment.
-
I'm seeing this as well now. With UEFI boot enabled, a VM with iGPU passthrough doesn't boot, maxes out a CPU thread and totally fills the syslog with,
kernel: vfio-pci 0000:00:02.0: BAR 2: can't reserve [mem 0xc0000000-0xcfffffff 64bit pref]Disabling UEFI boot stops the problem and allows the VM and passthrough to return to working as expected.
Rich
-
Awesome, thanks a lot.



Why only boot from BIOS? + never rebooted from within the Unraid GUI
in General Support
Posted
After 10 hours of troubleshooting post upgrading my server, this was the solution i needed. Thank you so much for posting, you've allowed me a good nights sleep after a crappy day.