

bobokun
-
Posts
224 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bobokun
-
-
Thanks! Mine says:
May 2 17:58:56 unNAS kernel: mpt2sas_cm0: LSISAS2008: FWVersion(20.00.07.00), ChipRevision(0x03), BiosVersion(00.00.00.00)It's okay that the biosversion is 0 right? Everything seems to be working fine
")
-
I successfully flashed my H200 into IT mode using the bat files. How do I check from Unraid whether or not my controller is the latest firmware version? Under system devices I see
IOMMU group 20:[1000:0072] 07:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)
-
Is anyone familiar with coding rtorrent? I would like to create a cron script that will delete the torrent and data for unregistered torrents. This is a sample code I found but I don't think it deletes the data, just the torrent file. Anyone know how I would modify this to delete data as well? Thanks
https://gist.github.com/onedr0p/8170117d43873c18c34139b7c5904c14
-
Sorry if this question has been asked a lot, is it best practice to use all SATA ports on your motherboard before using the ones on the controller? I have 8 ports on my motherboard, i'm using all 8 (2x for SSD and 6x HDD) but want to add more drives, is it better to use 8xHDD on the controller and leave 2xSSD on the motherboard?
-
13 hours ago, ugp said:
I am also getting the same thing.
Yeah I'm having the same error. Disabling the cloudflare plugin fixes it
-
Anyone getting an error trying to share a folder after updating to 15.0.6? I just receive a generic "Unable to create a link share" message when I try to create a share link. This was working previously prior to the update.
-
I recently upgraded my parity drive by swapping my old parity out and recalculating the parity with the new larger drive and once that was complete I added the old drive back in (Unraid cleared the drive and added it to the array). I noticed that I have a few Buffer I/O errors and other errors like OCSP responder prematurely closed connection while requesting certificate status. Not sure what these are or I should worry about this.

-
My plex docker container has a memory leak and I'm not sure how to fix it. When I restart the docker container it barely uses any memory however it slowly increases and doesn't stop, after 1 or 2 days it's using 5-6GB of RAM. I've tried to delete my docker img and recreate it downloading a fresh docker container for binhex-plex-pass. I would prefer not to start from scratch as I have quite a number of users on my server. Is there anything I can do to figure out what is causing this?
-
you create backups of all your docker containers everyday?
-
In that case should i be using a script to stop all docker containers before invoking mover?
-
I thought invoking the mover every night will automatically stop the docker containers and start them again once mover is completed. Do you run a custom script to stop and start all docker containers?
-
Seems to be plex being the culprit, it has a memory leak. I'm using the linuxserverio docker container. Should I be switching to binhex for plex?
-
No, I need to wait until the next time it happens again for me to find out which one is causing the issue. The problem is when I tried to stop a docker container it just hangs (I think because the cpu and RAM are all 100%), so I can't even kill the docker container or shut it down from the GUI. Is there a way to stop all docker containers using ssh commands? Or if that doesn't work can I kill the process running the docker container?
-
The hard drives start maknig a lot of noise when this happens. I think there is an issue with I/O and it gets stuck? Is there any way I can figure out if it's a hardware issue or software? My drives are all relatively new (1-2years) and have gone through several runs of preclear before using them so I don't think it should be the hard drives. Any way I can check?
-
Unfortunately changing to binhex-sonarr didn't fix the issue. I noticed that all my cpu and ram are being used as well when the docker containers stop responding but htop shows otherwise . Attached are some new diagonostics.
Edit: weird thing happened but once docker containers automatically updated the CPU all went back to normal. The docker containers that got updated were :
Community Applications
Docker Auto Update
normal: airsonic (was stopped), bazarr binhex-sonarr nextcloud radarr rutorrent sonarr (was stopped), tautulli unifi-controller jackett letsencrypt Automatically UpdatedHow can I figure out which docker containers is causing the hang ups?
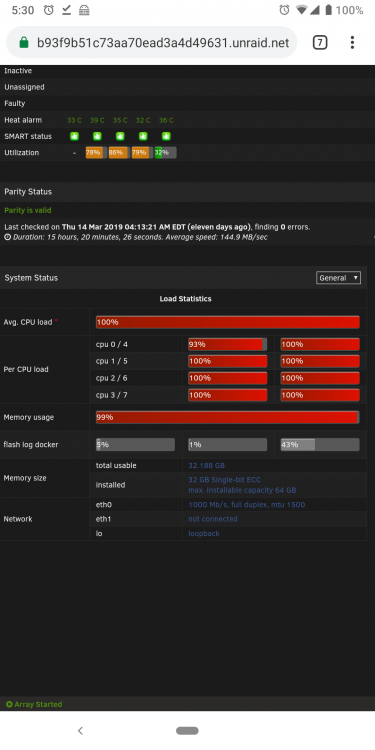
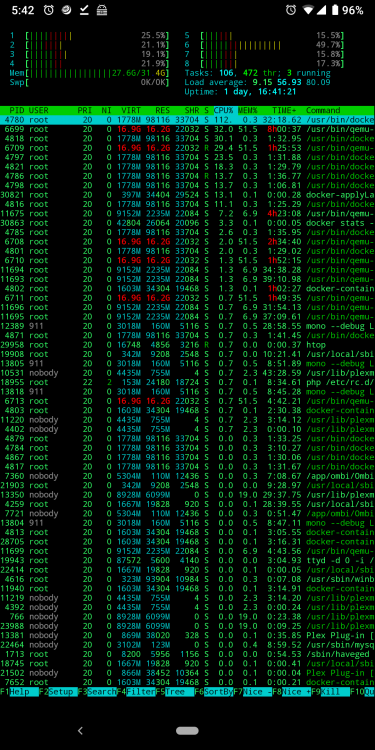
-
Thanks, I'll move my sonarr docker to binhex. Did you do it for just sonarr or for also radarr,jackett,lidarr,plex?
-
I noticed the past couple days after leaving the server running all my docker containers would stop responding and the only way to fix it is to restart the server.
I thought it was a one time thing but it just happened again and I'm not sure what the cause is.
Going on the docker tab takes a longer time to load than usual (around 1min) and then pressing stopping all Dockers just ends up with a looping animation. I can't restart any docker containers and the only option is to restart the server.
-
Did you end up getting this to work with unraid?
-
1 hour ago, CHBMB said:
Try
sudo -u abc php7 /config/www/nextcloud/occ db:convert-filecache-bigintThank you that worked perfectly!

I am also having an issue with not setting up caldav/carddav. I've tried searching through the thread and I've added this code to appdata\letsencrypt\nginx\site-confs\default but it's still giving me the error. I've also tried adding the same code to my nextcloud\nginx\site-config\default and it's not working either. Anyone have an idea on how to fix this issue?
location = /.well-known/carddav { return 301 $scheme://$host/remote.php/dav; } location = /.well-known/caldav { return 301 $scheme://$host/remote.php/dav; }EDIT: I have fixed this issue! for anyone else who is having this error and is using YOURDOMAIN.COM/nextcloud as the URL you need to change it to this code. Very silly mistake of me but I'm glad all issues are resolved now
location = /.well-known/carddav { return 301 $scheme://$host/nextcloud/remote.php/dav; } location = /.well-known/caldav { return 301 $scheme://$host/nextcloud/remote.php/dav; } -
On 1/18/2019 at 10:26 AM, CorneliousJD said:
Sorry to bother, I did try searching for this and found others with the issue but not a resolution.
I had 13.0.0 installed, updated to 14.x and then 15.0.2 after that - all via WebUI and that went very smoothly.
I just now have these warnings, before the upgrades I didn't have any warnings or issues here listed, I also still continue to get an A+ rating on the Nextcloud security scan, but I would like to resolve all of these issues listed here for good measure.
EDIT - got the tables updated w/ the sudo -u -abc command in the docker shell, but still not sure why the refer-policy is kicking that back, i had thought i had that issue on 13.x originally and fixed it. I'll have to look around some more, but if someone has a link or info handy feel free to send it my way!
Any help is appreciated!
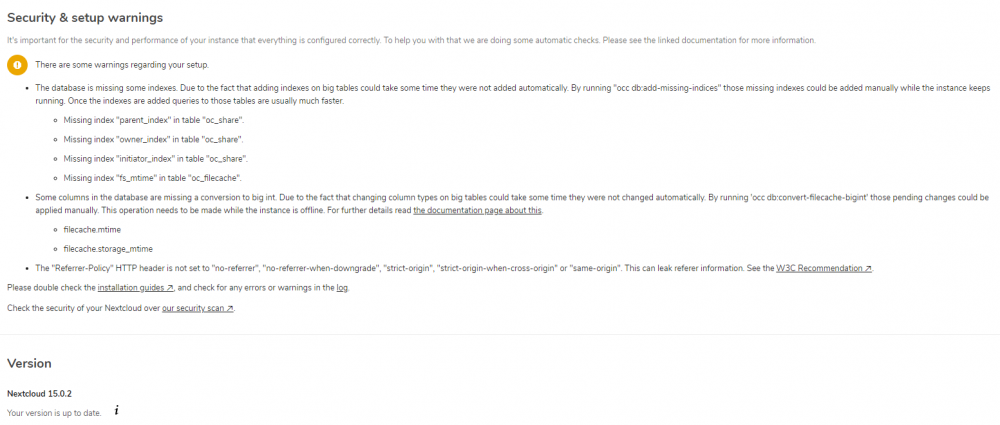
I have this same error, what was the command you used to fix it?
I tried "sudo -u abc php occ db:convert-filecache-bigint" and it gives me an error "Could not open input file: occ"
-
Thanks, is there anything I can do you avoid this situation from happening again?
-
I recently got these out of memory errors found from fix common problems plugin. I've attached diagnostics for your review. Thanks!
-
-
12 minutes ago, johnnie.black said:
While you should avoid preclearing SSDs doing it once it shouldn't kill it, unless it was already failing, try doing a secure erase with the Intel SSD Toolbox, if that fails you'll need a new SSD.
I tried installing the SSD Toolbox and this is what I see... Does any of the logs indicate any failure during preclear? Onc the preclear was complete I checked the smart status and it showed 0 reallocated sectors and nothing unusual from the device failing...
I also tried to boot into intel's firmware update iso but it said it couldn't detect any Intel SSDs..







[DEPRECATED] Linuxserver.io - Rutorrent
in Docker Containers
Posted
I'm actually having some trouble getting the script to work. What port did you use to connect?