

mishmash-
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by mishmash-
-
Amazing, thanks!
-
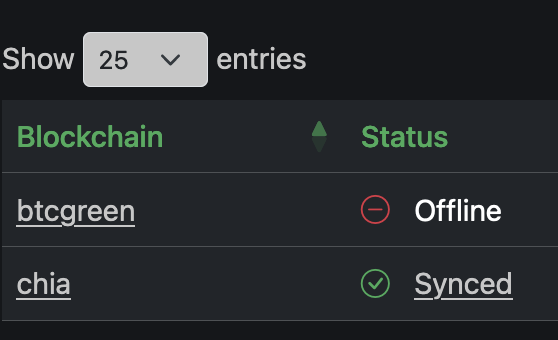
Hello all, I've searched the docs and the config files but cannot find it - how can we remove old forks from the machinaris list? I have an old btcgreen fork in my list I'd like to remove...
-
I never managed to trace the issue. I ended up modifying the container slightly to implement in proxmox - I now virtualise unraid and give the iGPU to a plex container in proxmox. The iGPU is monitored from inside the proxmox plex container. You can see the files here - maybe some mods on your side will help your implementation: https://sorrento-lab.github.io/9_1_PlexLXC.html
-
[Support] MastiffMushroom - TrackerAutoLogin
mishmash- replied to MastiffMushroom's topic in Docker Containers
This is really cool! I can understand the motivation behind it. I can try submit some changes later for some other sites via github, it looks like the details of each site are neatly housed in tracker_config.json, so I'll use an identical definition for the sites I have access to for testing.. -
I think this can be closed - it is not an unraid issue. The issue is with how a mac keeps open its authentication over long periods of time/sleep/disconnect/reconnect etc. A reboot (of the mac) solved the issue immediately. This thread suggested it: https://community.spiceworks.com/topic/133059-files-in-smb-share-on-server-invisible-to-my-mac Thankyou Squid for checking in!
-
Here you go: root@sorrentoshare:~# ls -ail /mnt/user total 16 648799821318062208 drwxrwxrwx 1 nobody users 176 May 20 01:25 ./ 2952 drwxr-xr-x 11 root root 0 May 20 09:19 ../ 648799821480511617 -rw-rw-rw- 1 nobody users 4096 Jul 7 2018 ._.DS_Store 649081296294772867 drwxrwxrwx 1 nobody users 28 Feb 13 2018 Family/ 648799821476992389 drwxrwxrwx 1 nobody users 104 Mar 28 2021 MM-TM/ 648799821318062211 drwxrwxrwx 1 nobody users 94 May 7 06:25 MM-common/ 648799821480320334 drwxrwxrwx 1 nobody users 38 Mar 23 2021 Mary/ 648799821476992390 drwxrwxrwx 1 nobody users 94 Mar 4 09:04 Media/ 648799824900794244 drwxrwxrwx 1 nobody users 49 Nov 21 07:21 MP-TM/ 648799821479492834 drwxrwxrwx 1 nobody users 47 Mar 17 03:19 MP-common/ 14073748835533057 drwxrwxrwx 1 nobody users 260 Mar 13 10:20 appdata/ 648799821332361902 drwxrwxrwx 1 nobody users 153 Oct 17 2021 cachebk/ 14073748835551986 drwxrwxrwx 1 nobody users 0 Nov 7 2021 domains/ 648799822560932645 drwxrwxrwx 1 nobody users 6 Nov 7 2021 isos/ 14073748835551987 drwxrwxrwx 1 nobody users 26 Nov 7 2021 system/ 648799821359679830 drwxrwxrwx 1 nobody users 23 May 10 2021 windows10array/
-
This one is a bit of a different one to all the results I'm finding with search. I have a private unraid share that I am accessing via SMB from a mac. Credentials seem to be ok. The issue I am finding is that I can browse the full share, go into folders, see lists of folders and files, but I cannot open any files (or even preview them, it just shows a file icon) and I cannot copy to the server either. It seems to be applicable for all shares that I try to access, but interestingly, time machine can still successfully backup to the time machine share. I've posted diagnostics below...any ideas? I'm looking into how to reset permissions...but I have not received any permission errors. The error I receive during an attempted copy to server is "The operation can’t be completed because one or more required items can’t be found." Edit1: running docker safe perms did not help sorrentoshare-diagnostics-20220520-0923.zip
-
getting a strange error when trying this container: 2022-01-01T14:21:20Z E! [inputs.exec] Error in plugin: invalid character '}' looking for beginning of value To try and trace it I decided to map both the telegraf.conf and shell file separately into unraid's folders, this way I can modify both accordingly. Unfortunately I can't work out the cause of the error. All the {} brackets seem to be correctly paired, there are no strays. Any idea on this one? The conf and shell file are in @TheBrian's github above...
-
[GUIDE] Virtualizing unRAID on Proxmox 3.1
mishmash- replied to joelones's topic in Virtualizing Unraid
I'm looking at virtualising my unraid and opnsense under proxmox also. My aim is to pass through the onboard sata controller with my drives to unraid (it sits in its own IOMMU group). But then for cache, I would like to partition my NVMe drive for the proxmox partition, opnsense, unraid cache, other guests etc. Is this possible to do? I.e. give unraid a nvme partition to play with as the cache, instead of doing direct passthrough? Edit: answered with google I understand that things like SMART etc won't be available for this partition. Also how does fan control work for array drives? Is it possible to give unraid access to the fan headers, or is temperature management done in proxmox? Edit: some google-fu tells me that fan control will need to happen on proxmox side either via a fancontrol plugin or directly from BIOS. -
My unraid box has a bit of a custom arrangement, where the GPU has 2x oversized fans - one blows on the GPU directly, and the other on the array drives and the GPU. The GPU controls one of the fans, and unraid controls the array fan. I am trying to set up the ability to calculate and compare a required PWM value for the array drives and the GPU, and then decide which is higher and apply it to the array fan. In my windows VM I use nvidia-smi with a timeout -t 5 loop running on a schedule to constantly update a txt file on the cache drive which unraid can read. This part seems to work ok, windows updates the txt file with the fan % value. I have included in the array fan script (which I found on these forums) an arrangement which takes the percentage and converts it to PWM. The issue is - it does not work with the file that is being dynamically updated by windows, but it does work with a static test file which was created by me in windows and is sitting in the exact same location! I'm pulling my hair out on this, I can't work out why it is not working...any thoughts? #!/bin/bash # unraid_array_fan.sh v0.4 # v0.1 First try at it. # v0.2: Made a small change so the fan speed on low doesn't fluctuate every time the script is run. # v0.3: It will now enable fan speed change before trying to change it. I missed # it at first because pwmconfig was doing it for me while I was testing the fan. # v0.4: Corrected temp reading to "Temperature_Celsius" as my new Seagate drive # was returning two numbers with just "Temperature". # A simple script to check for the highest hard disk temperatures in an array # or backplane and then set the fan to an apropriate speed. Fan needs to be connected # to motherboard with pwm support, not array. # DEPENDS ON:grep,awk,smartctl,hdparm ### VARIABLES FOR USER TO SET ### # Amount of drives in the array. Make sure it matches the amount you filled out below. NUM_OF_DRIVES=2 # unRAID drives that are in the array/backplane of the fan we need to control HD[1]=/dev/sdd HD[2]=/dev/sde #HD[3]=/dev/nvme0n1 #HD[4]=/dev/sdc #HD[5]=/dev/sdf #HD[6]=/dev/sdg # Temperatures to change fan speed at # Any temp between OFF and HIGH will cause fan to run on low speed setting FAN_OFF_TEMP=47 # Anything this number and below - fan is off FAN_HIGH_TEMP=60 # Anything this number or above - fan is high speed # Fan speed settings. Run pwmconfig (part of the lm_sensors package) to determine # what numbers you want to use for your fan pwm settings. Should not need to # change the OFF variable, only the LOW and maybe also HIGH to what you desire. # Any real number between 0 and 255. FAN_OFF_PWM=55 FAN_LOW_PWM=55 FAN_HIGH_PWM=255 # Calculate size of increments. FAN_TEMP_INCREMENTS=$(($FAN_HIGH_TEMP-$FAN_OFF_TEMP)) FAN_PWM_INCREMENTS=$(($(($FAN_HIGH_PWM-$FAN_LOW_PWM))/$FAN_TEMP_INCREMENTS)) # Fan device. Depends on your system. pwmconfig can help with finding this out. # pwm1 is usually the cpu fan. You can "cat /sys/class/hwmon/hwmon0/device/fan1_input" # or fan2_input and so on to see the current rpm of the fan. If 0 then fan is off or # there is no fan connected or motherboard can't read rpm of fan. ARRAY_FAN=/sys/devices/platform/nct6775.656/hwmon/hwmon2/pwm7 ### END USER SET VARIABLES ### #GPU1=1 #GPUFAN=1 GPU1=$(cat /mnt/cache/windows10scratch/w10system/nvidiafan/gpufan.txt) #echo $GPU1 #if [[ "$GPU1" == "" ]]; then # GPU1=1 #elif [[ "$GPU1" == 0 ]]; then # GPU1=1 #fi GPU1=$((GPU1 + 1)) GPUFAN=$(($((GPU1 * 255)) / 100)) echo "GPU1 is "$GPU1 echo "GPUFAN is "$GPUFAN # Program variables - do not modify HIGHEST_TEMP=0 CURRENT_DRIVE=1 CURRENT_TEMP=0 # while loop to get the highest temperature of active drives. # If all are spun down then high temp will be set to 0. while [ "$CURRENT_DRIVE" -le "$NUM_OF_DRIVES" ] do SLEEPING=`hdparm -C ${HD[$CURRENT_DRIVE]} | grep -c standby` if [ "$SLEEPING" == "0" ]; then CURRENT_TEMP=`smartctl -d ata -A ${HD[$CURRENT_DRIVE]} | grep -m 1 -i Temperature_Celsius | awk '{print $10}'` if [ "$HIGHEST_TEMP" -le "$CURRENT_TEMP" ]; then HIGHEST_TEMP=$CURRENT_TEMP fi fi #echo $CURRENT_TEMP let "CURRENT_DRIVE+=1" done echo "Highest temp is: "$HIGHEST_TEMP # Calculate new fan values based on highest drive temperature if [[ $HIGHEST_TEMP -le $FAN_OFF_TEMP ]]; then ADJUSTED_FAN_SPEED=$FAN_OFF_PWM ADJUSTED_PERCENT_SPEED=0 ADJUSTED_OUTPUT="OFF" else if [[ $HIGHEST_TEMP -ge $FAN_HIGH_TEMP ]]; then ADJUSTED_FAN_SPEED=$FAN_HIGH_PWM ADJUSTED_PERCENT_SPEED=100 ADJUSTED_OUTPUT="FULL" else ADJUSTED_FAN_SPEED=$(($(($(($HIGHEST_TEMP-$FAN_OFF_TEMP))*$FAN_PWM_INCREMENTS))+$FAN_LOW_PWM)) ADJUSTED_PERCENT_SPEED=$(($(($ADJUSTED_FAN_SPEED*100))/$FAN_HIGH_PWM)) ADJUSTED_OUTPUT=$ADJUSTED_FAN_SPEED fi fi # Adjust fan to GPU output, if GPU is higher set GPU PWM to adjusted output if [[ $ADJUSTED_FAN_SPEED -le $GPUFAN ]]; then ADJUSTED_FAN_SPEED=$GPUFAN ADJUSTED_OUTPUT=$ADJUSTED_FAN_SPEED fi #echo "Adjusted output is "$ADJUSTED_FAN_SPEED echo "Adjusted output is "$ADJUSTED_OUTPUT # Implemenent fan speed change if neeeded CURRENT_FAN_SPEED=`cat $ARRAY_FAN` if [[ $CURRENT_FAN_SPEED -ne $ADJUSTED_FAN_SPEED ]]; then # Enable speed change on this fan if not already if [ "$ARRAY_FAN" != "1" ]; then echo 1 > "${ARRAY_FAN}_enable" fi # set fan to new value` echo $ADJUSTED_FAN_SPEED > $ARRAY_FAN echo "Setting pwm to: "$ADJUSTED_FAN_SPEED fi Output with the "test.txt" file - works as intended: Script location: /tmp/user.scripts/tmpScripts/Case fan control/script Note that closing this window will abort the execution of this script GPU1 is 51 GPUFAN is 130 Highest temp is: 39 Adjusted output is 130 Setting pwm to: 130 Output with the dynamic "gpufan.txt" file - fails to read gpufan.txt... Script location: /tmp/user.scripts/tmpScripts/Case fan control/script Note that closing this window will abort the execution of this script ") ") GPUFAN is Highest temp is: 39 Adjusted output is OFF Setting pwm to: 55
-
So everything works well with Authelia and password based redirection. Only issue is when I try to login via webgui it just redirects me to my domain. I don't have the chance at all to setup other methods as per the tutorial. I have totp enabled in the config file and still nothing...I'm pulling my hair out trying to get totp to work! Any suggestions?
-
I'm stuck on the first setup - mainly logging in via local network to setup 2FA. I can get to the authelia login page locally, but then when I try to login nothing happens. The docker log says "validation attempt made, credentials OK" but then nothing else. Anyone seen this issue before? Edit: all good, changed config to one factor, and it redirects properly after auth. now to work out how to get two factor to work...
-
I found some replies here with users using cloudflare domains - and they are unproxied. Is this less secure than other methods? I guess the only thing happening is exposing your public IP via a sub domain. Are there other methods to get wireguard to work with a cloudflare proxy or otherwise? Apologies for my ignorance, I'm not super well versed in the world of networking.
-
Discussion: Undervolting Intel CPUs with unRAID
mishmash- replied to lionceau's topic in User Customizations
Another grave-dig: I haven't done any consistent temperature or AIDA 64 testing - that will come in a couple of months after work and holidays calm down, but, I have a -100mV undervolt set just to see what happens. No crashes so far. It appears that there is an overall temperature reduction of 2C, but it is hard to tell. So, further testing for later: Boot unraid with all dockers stopped, find an aida64 tester docker Benchmark with a stable ambient temperature and 0mV offset. Begin applying offsets in BIOS (if possible, haven't checked), if not, back to intel-undervolt Re-apply benchmark test, rinse and repeat until instability in AIDA 64 I'd also like to test idle power, specifically if this type of undervolting will interfere with any automatic power stepping in the Haswell CPUs (I'm running a 4770). This is an interesting script, because with user scripts you could in theory apply your own power stepping (say reset offsets to zero when spinning up a VM and then reduce them when the server is unloaded). From what I have read changing offsets disables intel power states, but I am not sure if that happens with this script too. temperature target: -0 (100C) core: -99.61 mV gpu: -75.2 mV cache: -99.61 mV uncore: -99.61 mV analogio: -99.61 mV powerlimit: 105.0W (short: 0.00244140625s - enabled) / 84.0W (long: 8.0s - enabled) -
Discussion: Undervolting Intel CPUs with unRAID
mishmash- replied to lionceau's topic in User Customizations
Thread gravedigging... Managed to get into an interface of some sort using CLI and python3 for undervolting. I haven't tested it yet though. I used this python script, pulled it with git (pip3 did not work for me) and then ran it with python3. https://github.com/georgewhewell/undervolt root@sorrentoshare:~/undervolt# python3 undervolt.py --read temperature target: -0 (100C) core: 0.0 mV gpu: 0.0 mV cache: 0.0 mV uncore: 0.0 mV analogio: 0.0 mV powerlimit: 105.0W (short: 0.00244140625s - enabled) / 84.0W (long: 8.0s - enabled) -
Deterministic SSD Recommendations
mishmash- replied to Skrumpy's topic in Storage Devices and Controllers
Disclaimer: I'm certainly not an expert on this. Support is experimental. TRIM is not available when using SSDs in the array. My basic understanding is the fact that the TRIM command is passed to the SSD controller, and there are different types of methods for performing TRIM, which will invalidate parity. It's speculated that if it ever were implemented, then the TRIM method would be DRZAT (deterministic read zeroes after TRIM), as this would in theory not break parity....or something. DRZAT is also needed for some HBA cards when using them with SSDs in cache and TRIM. So if we don't have TRIM the other thing we rely on is SSD internal garbage collection, overprovisioning and general use case. Garbage collection happens in the background by the controller of the SSD, and modern garbage collection methods (apparently) are quite efficient. For the most part, this does not seem to break parity either - although @johnnie.black reported one or two SSDs that were causing parity errors. Overprovisioning: there's a good few posts on overprovisioning consumer drives using blkdiscard command on this forum (advanced users) or enterprise SSDs can be used, which have higher overprovision. I got a good deal on enterprise SSDs so I went with those. My original plan was to overprovision some WD Blues to enterprise levels, as these still seem to have DRZAT according to a WD Blue forum post. General use case: garbage collection and TRIM requirement is a result of file deletion, so I try and minimise my writes to the drive by keeping the array mainly read data only, and having appdata still on a separate btrfs raid 1 ssd cache. It is a bit of an odd arrangement, having SSD cache and SSD array, but putting in small consumer drives that can be TRIMmed that take most of the writes seems to work OK in this scenario. So far uptime is about 70 days, parity check once a week with no errors so far, fingers crossed. Drives are at about 70% full. Parity check speed on a 6TB (3x2TB+parity) array is about 410MB/s average. Other R/W operations are a lot faster, presumably because it's not a constant 1 hour slog on the system. -
Deterministic SSD Recommendations
mishmash- replied to Skrumpy's topic in Storage Devices and Controllers
Note that partly due to legacy issues from upgrading from HDD to SSD array, I still use a cache drive SSD in BTRFS raid1. But I think I actually like having a cache SSD with an array SSD, as the cache can be trimmed, and is constantly seeing tiny writes etc. I might upgrade it to an NVME for next time. In reality though I think it does not matter at all on having cache+array ssd or just full ssd array no cache. -
Deterministic SSD Recommendations
mishmash- replied to Skrumpy's topic in Storage Devices and Controllers
I have an array of 4x 1.92TB Samsung Enterprise SSDs (PM863a). See hdparm output below. They have DZAT. Note that as they are in the array they do not trim, I rely on the fact that I have minimal drive writes and rely on the garbage collection. No parity errors, running for 4 months now. Maybe one day I'll play with zfs on unraid, but that's for another time long in the future. /dev/sdb: ATA device, with non-removable media Model Number: SAMSUNG MZ7LM1T9HMJP-00005 Serial Number: <redacted> Firmware Revision: GXT5404Q Transport: Serial, ATA8-AST, SATA 1.0a, SATA II Extensions, SATA Rev 2.5, SATA Rev 2.6, SATA Rev 3.0 Standards: Used: unknown (minor revision code 0x0039) Supported: 9 8 7 6 5 Likely used: 9 Configuration: Logical max current cylinders 16383 16383 heads 16 16 sectors/track 63 63 -- CHS current addressable sectors: 16514064 LBA user addressable sectors: 268435455 LBA48 user addressable sectors: 3750748848 Logical Sector size: 512 bytes Physical Sector size: 512 bytes Logical Sector-0 offset: 0 bytes device size with M = 1024*1024: 1831420 MBytes device size with M = 1000*1000: 1920383 MBytes (1920 GB) cache/buffer size = unknown Form Factor: 2.5 inch Nominal Media Rotation Rate: Solid State Device Capabilities: LBA, IORDY(can be disabled) Queue depth: 32 Standby timer values: spec'd by Standard, no device specific minimum R/W multiple sector transfer: Max = 16 Current = 16 Advanced power management level: disabled DMA: mdma0 mdma1 mdma2 udma0 udma1 udma2 udma3 udma4 udma5 *udma6 Cycle time: min=120ns recommended=120ns PIO: pio0 pio1 pio2 pio3 pio4 Cycle time: no flow control=120ns IORDY flow control=120ns Commands/features: Enabled Supported: * SMART feature set Security Mode feature set * Power Management feature set * Write cache * Look-ahead * Host Protected Area feature set * WRITE_BUFFER command * READ_BUFFER command * NOP cmd * DOWNLOAD_MICROCODE Advanced Power Management feature set Power-Up In Standby feature set SET_MAX security extension * 48-bit Address feature set * Device Configuration Overlay feature set * Mandatory FLUSH_CACHE * FLUSH_CACHE_EXT * SMART error logging * SMART self-test * General Purpose Logging feature set * WRITE_{DMA|MULTIPLE}_FUA_EXT * 64-bit World wide name Write-Read-Verify feature set * WRITE_UNCORRECTABLE_EXT command * {READ,WRITE}_DMA_EXT_GPL commands * Segmented DOWNLOAD_MICROCODE unknown 119[7] * Gen1 signaling speed (1.5Gb/s) * Gen2 signaling speed (3.0Gb/s) * Gen3 signaling speed (6.0Gb/s) * Native Command Queueing (NCQ) * Phy event counters * READ_LOG_DMA_EXT equivalent to READ_LOG_EXT * DMA Setup Auto-Activate optimization * Asynchronous notification (eg. media change) * Software settings preservation * SMART Command Transport (SCT) feature set * SCT Write Same (AC2) * SCT Error Recovery Control (AC3) * SCT Features Control (AC4) * SCT Data Tables (AC5) * SANITIZE_ANTIFREEZE_LOCK_EXT command * SANITIZE feature set * CRYPTO_SCRAMBLE_EXT command * BLOCK_ERASE_EXT command * reserved 69[4] * DOWNLOAD MICROCODE DMA command * SET MAX SETPASSWORD/UNLOCK DMA commands * WRITE BUFFER DMA command * READ BUFFER DMA command * Data Set Management TRIM supported (limit 8 blocks) * Deterministic read ZEROs after TRIM #Remaining hdparm notes deleted. See last two bullet points above for DZAT confirmation. -
Ah right, makes sense. I've got 16GB RAM, but I tracked down the issue to a docker that had gobbled up 14GB of RAM. Put a resource limit on it and now cache dirs works. Cheers!
-
I'm using the cache-dirs plugin. Using the open files tool I can see that a "find" service is constantly running on one of my disks, stopping it from being able to spin down. How long does it normally take for cache dirs to finish this "find" process? It's been the better part of 3 weeks for me so far...
-
Update for anyone experiencing similar issues in the future - one of the fixes above has helped (I'm guessing the IOMMU error related fix, which is the Marvell 9230 firmware). I've been running a VM with constant processing and disk load and multiple dockers with no issues. This is with 1x SSD cache in XFS and the other SSD as an unassigned device in XFS for the VM.
-
Made some changes to the system settings and config, hopefully one of these would have fixed the problem: Updated to Unraid 6.5.2 from 6.4.1 (cache drive became visible again) Updated Marvell 9230 firmware as per this thread here and here Updated ASUS BIOS to latest version (from 2014 to 2018!) Didn't disable VT-d as per Marvell thread (apparently disabling VT-d helps) Moved VM disk image off cache and onto unassigned device SSD Will report back if problems persist further.
-
I've been having issues with either my cache pool or docker set up. One or both of them have corrupted twice in the last week, the first time I had a BTRFS cache pool set up, and now I have a single cache drive (XFS). The end result is what appears to be a unmountable cache drive and the inability to start the docker service (both times with BTRFS and XFS). I can't seem to trace the cause of this problem though, has anyone experienced this before, or is able to assist me with diagnostics? The 2x SSDs are mounted on a Startech PCI-e card, and have been giving me trouble free performance up until recently. I've read that perhaps VT-d may be an issue, I only recently started using VMs, but not the VT-d facility itself. Maybe this needs to be switched off? Thanks in advance. sorrentoshare-diagnostics-20180611-0732.zip
-
I'm looking to convert my existing unraid box to host a gaming VM (just one for myself). My daily driver laptop is a lightweight unit - and I'm also weighing up whether it will be cheaper or better to go with an eGPU. My question is will a gaming VM using a i7 4770 and a GTX 1060 mini with passthrough support modern-ish titles? How steep do the hardware requirements get when running games through a VM? Are there any general rules of thumb? (i.e. need 0.5 GHz higher and one level above recommended requirements, etc)?
-
I noticed that all my disks were spinning physically in the server box, but the unraid gui indicated that they were spun down (but reporting a temperature). Looking at grafana and then checking the logs for when they spun up, I find this: Feb 19 12:29:51 sorrentoshare kernel: ata14.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 Feb 19 12:29:51 sorrentoshare kernel: ata14.00: irq_stat 0x40000001 Feb 19 12:29:51 sorrentoshare kernel: ata14.00: cmd a0/01:00:00:00:01/00:00:00:00:00/a0 tag 4 dma 16640 in Feb 19 12:29:51 sorrentoshare kernel: opcode=0x12 12 01 80 00 ff 00res 00/00:00:00:00:00/00:00:00:00:00/00 Emask 0x3 (HSM violation) Feb 19 12:29:51 sorrentoshare kernel: ata14: hard resetting link Feb 19 12:29:51 sorrentoshare kernel: ata14: SATA link up 1.5 Gbps (SStatus 113 SControl 300) Feb 19 12:29:51 sorrentoshare kernel: ata14.00: configured for UDMA/66 Feb 19 12:29:51 sorrentoshare kernel: ata14: EH complete Feb 19 12:29:51 sorrentoshare kernel: ata14.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 Feb 19 12:29:51 sorrentoshare kernel: ata14.00: irq_stat 0x40000001 Feb 19 12:29:51 sorrentoshare kernel: ata14.00: cmd a0/01:00:00:00:01/00:00:00:00:00/a0 tag 5 dma 16640 in Feb 19 12:29:51 sorrentoshare kernel: opcode=0x1a 1a 00 3f 00 ff 00res 00/00:00:00:00:00/00:00:00:00:00/00 Emask 0x3 (HSM violation) Feb 19 12:29:51 sorrentoshare kernel: ata14: hard resetting link Feb 19 12:29:51 sorrentoshare kernel: ata14: SATA link up 1.5 Gbps (SStatus 113 SControl 300) Feb 19 12:29:51 sorrentoshare kernel: ata14.00: configured for UDMA/66 Feb 19 12:29:51 sorrentoshare kernel: ata14: EH complete I've read that apparently this means that the sata controller is choking, but I've never had this happen before until the upgrade to 6.4.1. Any idea what could be happening here and what I should be looking at or trying to fix? Cheers sorrentoshare-diagnostics-20180219-1332.zip

