
realies
-
Posts
174 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by realies
-
Since it's not possible to create an issue in the repository, I'm writing one here. Consider parsing the whole output of `upsc ups` to a key-value pair array instead of iterating through the keys and making use-cases for individual keys. This way the output from the ups service would be more easily accessible which eases refactoring and introducing new functionality. Would be exciting to see a separation between the front and back end too. In regards to the above, this should be sufficient to generate the array: exec("/usr/bin/upsc ups 2>/dev/null", $stdout); print_r(array_reduce($stdout, function($carry, $line) { list($key, $value) = explode(":", $line, 2); $carry[trim($key)] = trim($value); return $carry; }, [])); A demo can be seen here.
-
It seems nut package has been updated to 2.7.5-pre. Is this replacing the old binary and can the update be reflected in the changelog? Update: usbhid-ups stayed 2.7.4, great to see Nominal Power and UPS Load (W) working on Eaton! Update: As discussed in the package repository, ups.power.nominal/100*battery.charge does not produce the expected results. When using Eaton 5E 650i with the NUT v2 plugin, it reports: Nominal Power: 650 UPS Load: 253 UPS Load %: 39 Eaton UPS Companion (attached to a Win10 VM) reports: Output Load: 203W Usage: 39% Looking into the changes made to estimate Eaton's realpower when it is not available, I am proposing a similar change to the NUT v2 plugin until 2.7.5 or newer are deployed without any issues.
-
Thanks for testing. Could this be reported to the repo? I am currently unable to reproduce, but remember that when the UPS was passed through to a Win10 VM it did reconnect every now and again.
-
Considering this article, it should be safe to assume that the first CCX is from logical cores 0-7 and the second from 8-16.
-
The AsRock X370 Taichi board has a wireless interface that could be useful for a guest VM. It lives in the same IOMMU group as the wired network interface and despite the reported driver in use being pci-stub (lspci -n), QEMU complains. Is there a good way to passthrough the device without having to patch VFIO?
-
Interesting topic to investigate. In a similar scenario I have pinned the last 4 cores to a Windows 10 VM with the hope that this is how it works but have not confirmed that it is the case. If information could not be sourced it should be possible to see potential differences by comparing results from multithreaded benchmarks between different VM core assignment setups.
-
Nevertheless, an option to update all plugins (or selected plugins) would be beneficial.
-
Have the USB resets been addressed? There's some functionality in master that I am hoping to see in unRAID.
-
This message seems to be constatnly repeating in the logs: ==> /var/log/gitlab/node-exporter/current <== 2017-12-02_11:13:22.15422 time="2017-12-02T11:13:22Z" level=error msg="ERROR: mdadm collector failed after 0.000246s: error parsing mdstatus: error parsing mdline: sbName=/boot/config/super.dat" source="node_exporter.go:95"
-
With the latest update docker fails with: /usr/bin/docker: Error response from daemon: endpoint with name Netdata already exists in network host. Removing the container and image and re-adding the app does not fix it.
-
Nextcloud says it's version 12.0.2 and that there is a new version available even after a forced update of the container. Thoughts?
-
It is a valid workaround.
-
Removing the container and image (without orphan containers) and reinstalling worked. Although now I think I am having trouble with the built-in https support of 6.4.0.rc9f.
-
Having issues updating and starting on 6.4.0-rc9f.
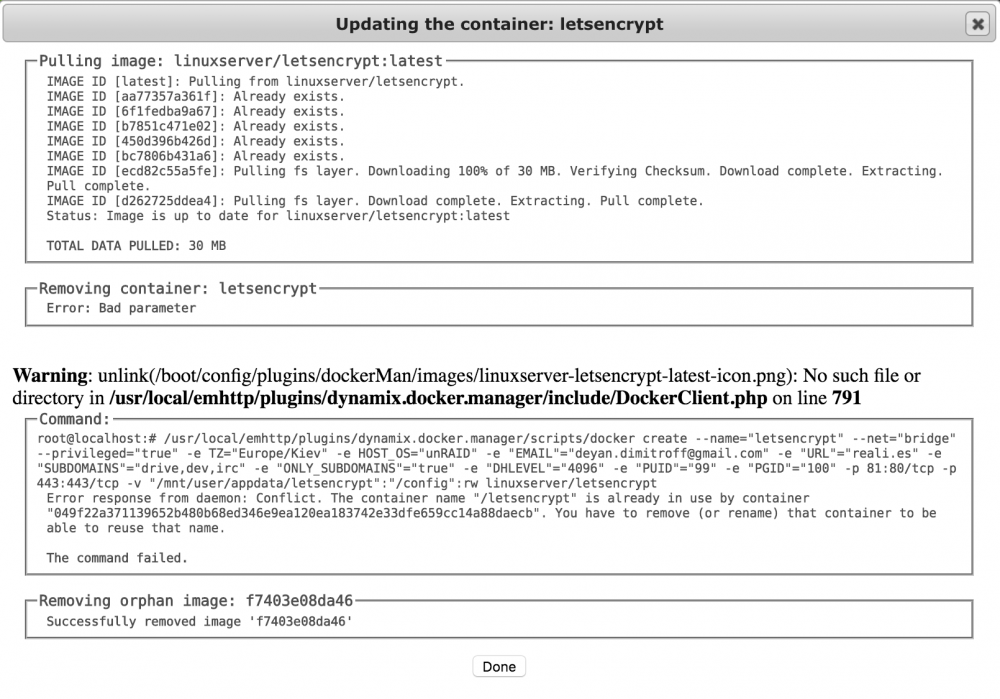
-
Does it mean that if the system is powered off, the ups goes out of power and shuts down, upon the power being restored the computer will not power on? Or is that nothing will power on the computer if power gets restored during the interval of the UPS being still up and the computer being off already?
-
[6.4.0-rc8q] Spinning down parity disk during parity-sync
realies replied to realies's topic in General Support
Most probably it has interfered, there was 64 sync errors on disk1 when parity-sync was interrupted and after a check all of them got fixed. Should there be an idiot proof confirmation box before somehow critical tasks? -
[6.4.0-rc8q] Average disk temperature readings
realies replied to realies's topic in General Support
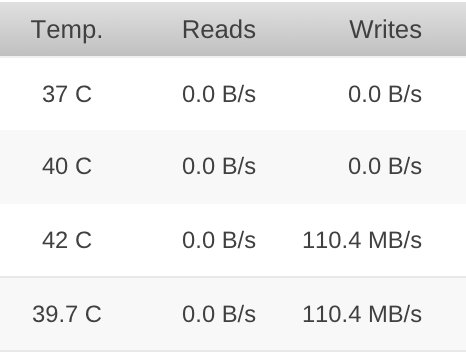
Lost in translation there, I have edited the post. @bonienl, what if one of the disks has an issue that brings its temperature up because of internal mechanical malfunction? This would affect the reading of the average temperature from which you take "hot or cold days". @gubbgnutten, I understand the "if it's not doing any harm, let it be" attitude, but this is the statistics page. Is there any other practical usage of the average, other than assumptions such as "It is a hot day today because my average between all disks is x °C". This indication could be greatly influenced and made even more irrelevant in a case of a system with dynamic fan speeds based off temperature sensor readings. -
[6.4.0-rc8q] Average disk temperature readings
realies replied to realies's topic in General Support
What I mean is that one would be interested in the temperature values for individual disks and never the average between all of them. -
What is the point in having average value for all disk temperature readings? It provides no useful or practical information.
-
Pretty concise, is unRAID capable of utilising the EDAC module? I can see those are not present in the expected directory (/sys/devices/system/edac), but there's error_count, interrupt_enable and threshold_limit files with values of 0, 1 and 4095 respectively. Those are found in /sys/devices/system/machinecheck/machinecheck0/umc_0/ and /sys/devices/system/machinecheck/machinecheck0/umc_1/ which I assume are UDIMMs 1 and 2 installed on my machine. It would be great to release more information regarding ECC memory support from OS stand point and potentially integrate information about it (when available) in the GUI. Would be glad if I can assist with the process.
-
After finally transferring the information from one of both data-mirrored disks from my old server to the newly build unRAID one, I have moved the same in size and type WD Red 4TB. The setup was running with only one 4TB disk, while the data was transferred over by the second 4TB disk, so the array was without a parity disk and no redundancy. After selecting the newly installed party drive from the GUI, I have started the array which has initiated the Parity-Sync / Data-Rebuild process. About 20% in the process I was looking through the GUI and noticed that the parity disk has a non-clickable exclamation mark with a popup text saying "Party is invalid". Assumed this is because the process has not completed, I have moved the cursor to the "Click to spin down device" icon without seeing the alt text and have clicked it with the expectation that it would provide more information about "Parity is invalid". Understanding what I have done about 5 seconds later after hearing the drive spinning down, I have spun it up again, without noticing any drop in the statistics for read and write speeds of both drives. A few hours later in the party-sync process I have noticed that Disk-1 (not the party disk) has come up with a new "197 Current pending sector" value of 1. Assuming this is caused by my interference of the syncing process, I wonder if this would have affected the integrity of the information. Can someone with more experience in the matter provide more information what might have been the effect of this, can the pending sector be remapped and cleared, and will this affect the integrity of the data. The process is still ongoing and will finish in the next couple of hours, when I will update this post with the outcome. Question to the developers: Should it be possible to spin down a disk when a parity sync process is active? Question to the community: Should there be a dialog asking for a confirmation of the disk spin down process?


