

srfnmnk
-
Posts
195 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by srfnmnk
-
Ah yes, i guess this does make good sense. whoops. Thanks. Is there a good way to set up auto-update for this one container (I don't want to auto-update all my containers)
-
Thanks @MrChunky -- I will do that. Also, for all of you asking good questions about how to set this up, I also had a bit of a challenge, I'll create a video when I set up my next container and provide a link so others can see how I get it running on Unraid with this Docker. One thing I've been doing differently is to actually complete the authorization from within the docker container. The authorize allows you to specify an identity dir location -- then you'll see that it actually creates a prefix_path/storagenode/<6 id files> here. This is what ultimately allowed me to figure out how to organize the prefixes and id files. I'll try to get the video out today or tomorrow but no promises.
-
Anyone have any recommendations on optimizing this container. I'm ready to lend about 80TB across 4 containers...but...I have a few thoughts / concerns / questions. How to minimize pressure across provided disks (i've specified sepcific disks for each container and storj is the only thing that his them. I've disabled cache, any other recommendations to increase disk longevity? I also have the share set to "Fill-Up" to ensure minimum disk spin for new data acquisition. I just started the sync about 3 days ago but it looks like I'm averaging about 3GB/day of new data acquisition. I am allowing 6 cores to the docker container and 24TB with 1Gb/s up/down and unlimited bandwidth...any ideas on how to speed this up? Should I expect ingress to speed up as I gain rep on the network?
-
One more oddity, when I go to mount it as read-only in UD it shows up as "luks" FS? very confused.

-
1 more thing. I have reconstruct write enabled via the turbo write plugin. Should I disable this? Could this be causing bad writes? Is there any chance that something is mis-configured that could be causing bad writes?
-
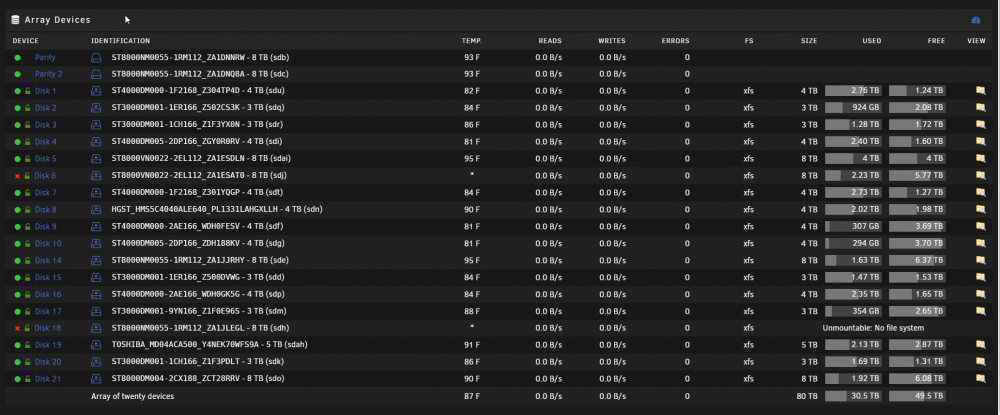
but how does an emulated disk have lost and found items that are missing on the array? For years of using unraid, when a disk is disabled its contents are emulated in place meaning those files would be in the directories they belong, not in lost+found. I'm just completely confused on how the array is in this state. I have dual parities -- I had 2 disks get disabled, why is data missing, that's where i'm lost.
-
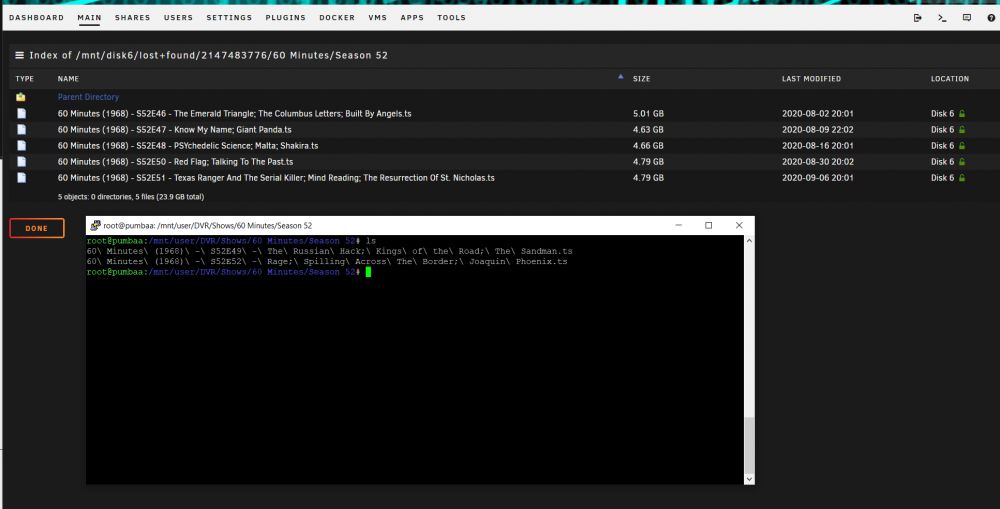
Well, it's still not over. Could the array be corrupted or something? I'm now thinking that a VM or Docker container is causing the issues because last time I reported all good and I couldn't break anything I had all docker containers disabled and all VMs disabled. I rebuilt disks and parity several times without issue. Now, after about 1 day of trying to be back to normal operations two disks went offline again, I tried to rebuild and it completed successfully but later that evening (after it completed successfully, bam, same two disks were disabled again. So, now what I'd like to do is figure out how to get this repaired again...and then review and troubleshoot my VM/docker setups to see if something is causing an issue there. Currently, if we just look at disk 6, as you can see, it's disabled and emulated. The emulated FS has a BUNCH of lost and found, how is that? The disk was not mountable so I started array in maintenance mode, repaired disk with -v (-L was not used), started the array and the FS doesn't say unmountable for disk 6 anymore, it is still disabled/emulated, but there are now all these lost and founds. Upon a check of the actual array, these files are, in fact, missing from the array and the share where they should be as you can see from the screenshot. Is the FS meta of the array corrupted? What are next steps? Lets assume no power issue ATM as I tested that EXTENSIVELY and rearranged mobo components and PSU wires and rails. Thanks again. pumbaa-diagnostics-20200921-0816.zip
-
Cool, that's what i figured. Thank you.
-
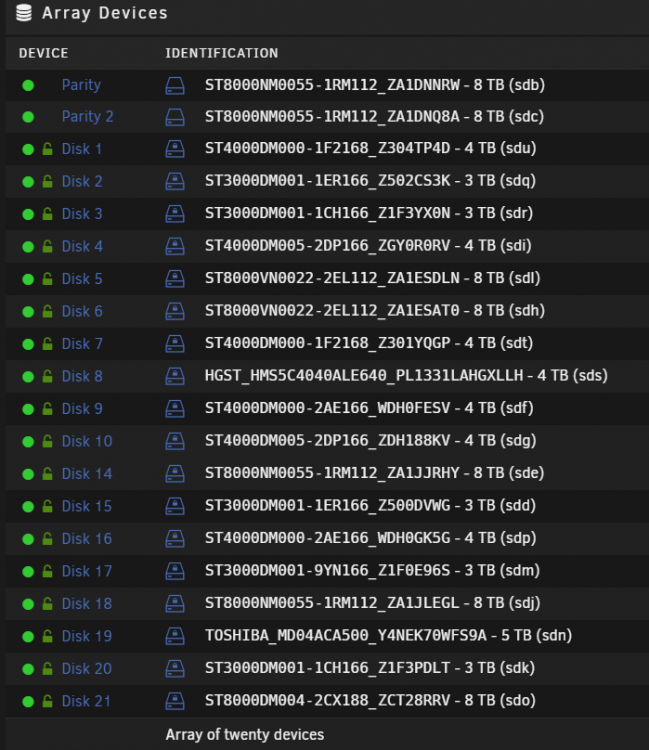
Well, there you have it. I can't seem to break it any more. Thank you so much to everyone for all your help. @trurl I'll be circling back to your docker recommendations now. One last question now that things are healthy again. In the image below, you'll notice that disks 11,12,13 are not in the list. I would like to clean this up (been like this for ages, I just never worried about it). When I stop the array I see 3 empty, unassigned disks but I will never fill these up since i'm at the max # of disks I ever plan to have. What's the best way to get rid of these? Thanks again
-
I can't seem to break it now, knock on wood. I've just reinstalled the LSI 9201-16e and added all my DAS back with the new power config and kicked off another 4TB drive rebuild. Will check back in when it's done and we'll see...if no errors here I'd say we're good. wowzers (crosses fingers)
-
Absolutely nuts...well, the parity sync finished without an issue given the new power config. I have now booted out a 4TB disk and am rebuilding it. If this succeeds, I'll re-install the LSI 9201-16e and do one more rebuild... I will say, there's one more possibility. The SAS Expander card, when I had the issue, I had the card installed differently (not in the PCIe slot) since it was being powered by the molex and didn't need the PCIe slot anymore. The way I had it installed in the case made it possible for the pcie pins to make contact with the metal, so...I wrapped the pcie headers of the card with electrical tape to make sure nothing shorted the pins. I'm wondering if somehow the tape I had was allowing static to cause strange behaviors with the card...not sure...just an alternative theory to the power issues.
-
I like this Idea -- will do it. Perhaps a few corrections. I currently have 4 MOLEX/SATA strings from PSU (modular). 1 3X4 HDD (MOLEX --> Backplane) 1 2X4 HDD (MOLEX --> Backplane) 1 3-drive SSD String (SATA Power --> SSD direct) 1 string to expander card directly from modular output on PSU. Screenshot below shows where all the outputs are coming. I have 1 (bottom left) still open, I will probably run another molex to backplane so that I am powering as suggested 2,2,1 on the backplane. Parity check is still running, of course, but is at max speed and progressing.

-
Right, but a 14.6 watt max TDP pcie card pulling from a molex on a dedicated connection...the only thing I can think of is bad wire, bad PSU slot, bad molex connector on card, or just a bad power rail on the card itself. Do you have any other thoughts/ideas on what could cause it? If you look at the SAS Expander datasheet it shows max TDP is 12v / 14.6w Thanks again @Michael_P

-
Another update removed the SAS expander from PCIe power and put it back on MOLEX power from the SATA slots on PSU. I have not added the new LSI 9201-16e back in yet. I had 2 SSDs running on one SATA power out from PSU and 1 SSD on another. I have strung those together on a single wire all now going into a single out on PSU. This was to open a slot from PSU to try another output I removed the MOLEX cable I was using for the SAS expander card (it was a 4x molex power out string) and have replaced it with a 2 output moled xtring where the first outupt in the serial is connected directly to PSU. The new molex has been plugged into a different output port on the PSU in case there was an issue with the PSU out. All 20 HDDs are on 2 PSU outs. The norco 20 has a backplace with 5 rows each powered by a single molex connector. One PSU output powers 3 and the other powers 2. Running Parity check now to see if I run into any issues. If no issues, I may try to force a rebuild to see if that causes issues...if not I'll have to surmise that one of the changes resolved the issue. Additionally, I have pulled the data sheet for the PSU and the SAS expander to determine if there are any strange power requirements / considerations when running from molex, I found nothing unexpected. max power draw is 14.6W 12v -- no jumpers or anything to switch. The PSU supplies up to 996W on 12v and with 3 SSDs, 20 HDDs, 1 gtx-1060, Ryzen 3900, and the SAS expander card all running at full tilt "should" not exceed 592W as per seasonic's calculator. SAS Expander Data Sheet PSU Data Sheet (1000W) I realize this is not the right forum to troubleshoot power delivery but I figured I'd keep the main thread here for those that are curious in the future.
-
And just like that the array is healthy and parity sync is complete. Wow. I will continue to poke around to see what is causing the power fluctuations. My guess is the molex power to the SAS expander, I will try to dedicate a rail or use the pcie power out from the PSU. @Michael_P thank you so much for chiming in here! That's great to know and it lines up exactly with my situation. I too have the Norco 20 bay and I believe I am using 3 rails to power the 5 layers but I will double check. It seems that using the PSU SATA power out is causing power sags in the SAS expander linked above. I will check back in when I have more details. I will also post diagram of PSU setup after I get time to get back into the server. Not entirely sure how to test this other than create new hardware config and then run full parity check to see if there are issues. This is going to be quite a fun ride but hopefully with the new power out from pcie it will just keep working. Anyone else have more ideas on how to test for power sags other than parity check? @JorgeB -- great insights on the power/hardware issue. I hate that you seem to be right but props to you friend.
-
Back in June (shortly before I started having these issues), I did add a new component. I ran out of pcie slots on my gigabyte mobo and thus powered my SAS expander with a molex instead of from the pcie slot. I did a full power review and here's what I have running off a Seasonic Prime PD-1000 Platinum. Seems like I have plenty of headroom but I'm no expert on calculating watts / rail or anything. If anyone has any insights, I'd love to hear if you think there's a better way way to rearrange the power. Meanwhile, a new config has been launched, everything is mounted, the array seems healthy and the the parity is rebuilding. I'm not entirely sure how to go about debugging where the power issue may be but I figured revert back the newest changes and start from there...perhaps adding the SAS expander to molex and/or adding the LSI 9201-16e to the pcie caused unstable power...so testing that now...after that, I'm not sure. I did the best I could to use the PSU calculators and it seems as though I have sufficient power but would love input if someone else has experience. Seasonic Prime PD-1000 Platinum GIGABYTE X570 AORUS Master Ryzen 3900 H5-25379-00 SAS 9201-16e - powered via pcie4 (temporarily removed) Intel RAID (SAS) Expander Card (RES2SV240) -- powered via pcie4 (temorarily moved -- was on molex as of June 2020) HighPoint RocketRAID 2720SGL 8-Port SAS -- powered via pcie4 GTX - 1660 -- installed on pcie4 powered via 6 pin from PSU 1 Sabrent 1TB Rocket NVMe PCIe M.2 2280 3 samsung 850 pro 500GB 20 7200 HDD Just had a thought as I was putting this list together. This PSU has power output for SATA/IDE/MOLEX which is what is powering my HDDs and SSDs. To accommodate the new LSI 9201, I moved the SAS expander card to molex (from pcie power). I was powering it from IDE/SATA/Molex NOT the CPU/PCI-E rails...wondering if I should have been powering the SAS expander from the PCIE/CPU rails instaed?? Thoughts?
-
Ok, will work on hardware troubleshooting today. One more question. I have a suspicion that my parity is inaccurate and we keep trusting it. What would be an approach to invalidate the parity and trust the disks. All the disks have passed SMART test and seem to have the proper files but the emulated disks seem to have the wrong information. Is there a way to invalidate the parity and rebuild from the disks and their data? Since I have a disabled disk -- I'm thinking I can create a new config and just have the parity rebuild but wanted to confirm. Thanks.
-
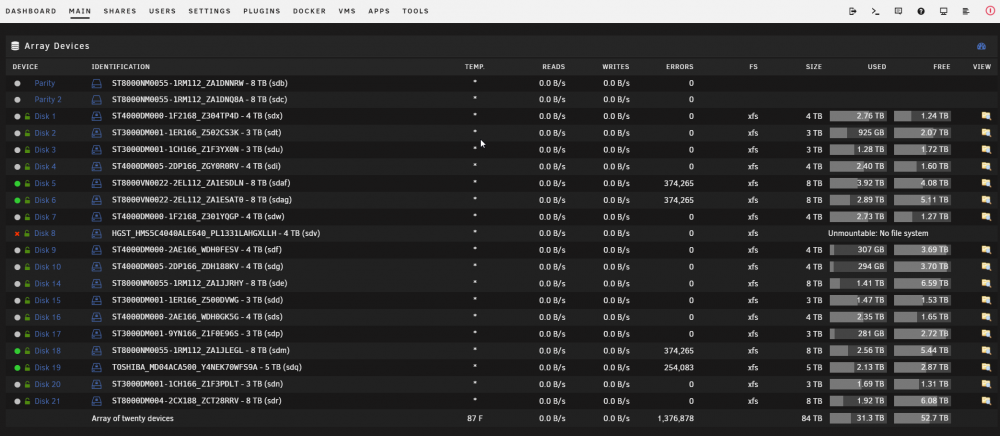
@trurl still struggling. Below is before a reboot. After a reboot and array start Disk 8 is mountable via UD RO and in fact, all of the files that are in lost+found on the emulated driver are here and accessible. Disk 8 also passes SMART self extended.
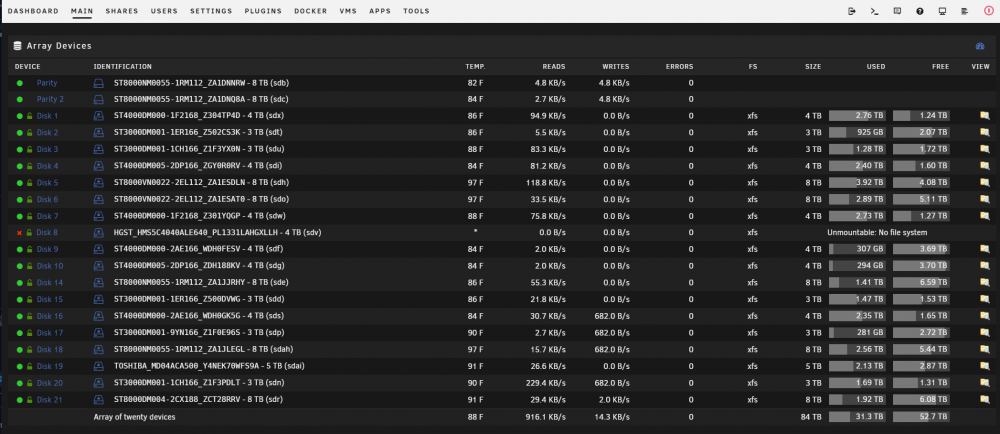

-
that's true and it's fine for a while but then in a day or two i get errors somewhere else. I was wondering if I should try and do a parity check (and repair) and/or xfs_repair on all the disks to see if there's some array error.
-
Gotcha, thanks Johnnie. Michael, i hear you on that. I am using two rails from PSU and it's been fine for many years. That said, the easiest thing to check/replace is the PSU (probably)...I will take a look and do the good ole jiggle everything to ensure everything is seated well. For the errors on disk 5 / 6 (where i had the read errors), I did a check disk -nv from UI and it noted that there were valuable metadata changes. So In maintenance mode (because it's grayed out when array is on) I ran the xfs_repair "check" and it tells me it's not mounted. It is mountable but in maintenance mode it seems as though I cannot do a repair. Should I enable the array and run the xfs_repair -v /dev/mapper/md5 from cmd?
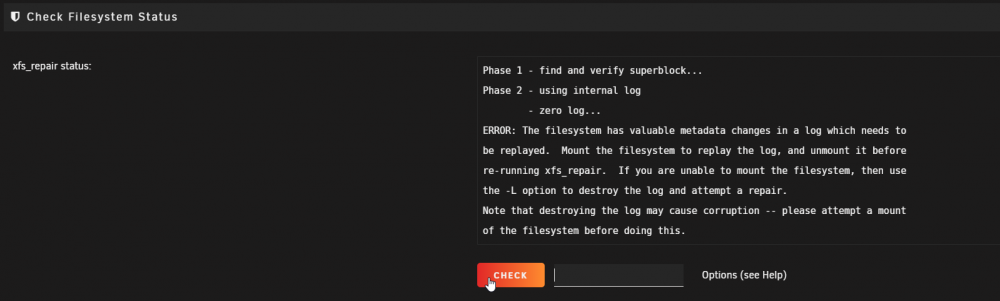
-
There are a LOT of folders but disk 8 is still disabled...so not sure if a new config and rebuild would help it or what. But to Johnnie's point...there may be something going bad hardware-wise. I keep getting different read errors on different drives. As you can see from the image below today it's disks 5 and 6 but I've seen them elsewhere. These read errors...does that mean corrupted data or does it mean it failed to read (maybe not a data error)? If the latter, then I'm guessing that this may happen during rebuild causing the issues and may be intermittent hardware issues as Johnnie is eluding to. man...I have 3 LSI cards in there with dual sas ports each haha...hrmm... Below are some example logs from the errors. Sep 4 04:40:01 pumbaa kernel: md: disk5 read error, sector=10804441552 Sep 4 04:40:01 pumbaa kernel: md: disk6 read error, sector=10804441552 Sep 4 04:40:01 pumbaa kernel: XFS (dm-4): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x21c009460 len 8 error 5 Sep 4 04:40:01 pumbaa kernel: XFS (dm-4): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x21c009460 len 8 error 5

-
Ok, I hear you. I will look around at the hardware and perhaps upgrade the firmware (but it's been working for years)... How does one go about recovering the items in lost+found?
-
This is the same PSU that's been in there for 1.5 years. Are you suggesting that it might be intermittently going out or something? I have UPS connected and am not seeing any issues/fluctuations on input/output power... The server also never turns off -- I just cannot fathom the randomness of the power failures that would be required to make this happen...The failures were across two different power rails too, I did confirm that when you mentioned this earlier. The effort required to replace and rewire the PSU is significant, is there anything else that it could be? I would like to rule out absolutely everything else first. There are some ongoing errors such as the /dev/sdae problem getting id and what not...
-
Hello, I thought this journey was coming to a close but the saga continues... Since the last posts I have received yet another new disk and replaced disk 18. I stopped the array, powered down replaced the drive started the array with the new drive selected as disk 18...the rebuild began and everything completed. Disk was unmountable so I completed the xfs_repair -vL /dev/mapper/md18 as before, it completed and was then able to be mounted Restarted the array in maintenance mode and ran xfs_repair -nv from the gui and everything looked good (completed as expected) I thought that would be the end of it...BUT...that evening a wholly new disk became "disabled" (Disk 8 - SN: PL1331LAHGXLLH). So on I go: I notice that the emulated files from disk 8 are unavailable. I ssh in and verify that I cannot make a copy of any files on disk 8 from ssh console...i tried both /mnt/disk8/... & /mnt/user/<share> xfs_repair in maintenance mode had same superblock issue so -- xfs_repair -vL on Disk 8 (eumulated) just disabled. Ran an extended SMART test and it passed... now xfs_repair -nv looks normal but the drive is still disabled... Restarting the array shows that the files are being emulated but the files are not there. Looked in (from ssh) /mnt/disk8 and /mnt/user/<share>... and they're in neither place...so I proceed to check lost+found and there are 2261 dirs with data in them but they all have IDs...(screenshot attached) The data is all throughout these folders... What the devil is going on?! Ideas? Before I build a new config or do anything else I wanted to check in and get your thoughts. I'm worried that if I do another new config and note that disk 8 is good that we might be going in circles now... It seems I did have 2 bad drives -- both have been replaced and rebuilt -- but why drives keep becoming disabled? How to get disk 8 enabled again and get the array healthy again? Attaching some screenshots and a new diagnostics package of current status. One other note, when the array is stopped, (maybe other times too) I see this scrolling error in the log "device /dev/sdae problem getting id" (screenshot attached) but I don't see any sdae devices anywhere in unraid gui but on ssh it does exist in /dev folder. pumbaa-diagnostics-20200903-1248.zip
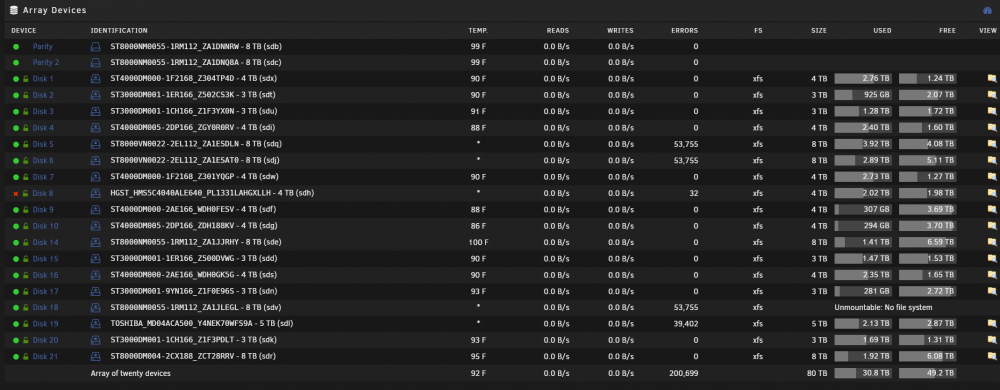

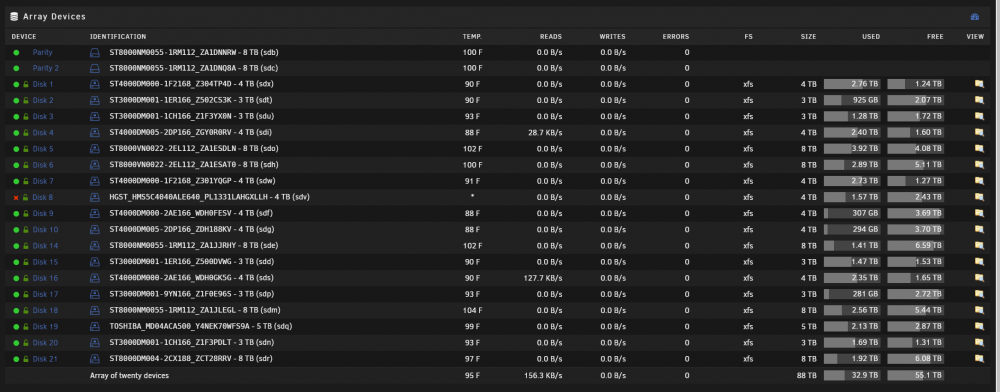
-
Ok, so now 18 is mounted but it's still disabled and emulated. Hoping to receive additional disks tomorrow.















