

Saldash
-
Posts
53 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Saldash
-
-
Hi all,
I've started getting periodic systems halts that require a full hard reset to resolve.
The system boots and appears to start normally until I get to entering my array password where after starting the array the UI appears to hang with the unraid logo pulse for a good minute at least before the UI becomes normally responsive again.
I run weekly array health checks that have not reported any issues and after a fresh boot up, I cannot see anything in the system log that would indicate the source of the fault (not that I'd know what I was looking at to be honest).
I've uploaded the diagnostic file in the hopes that someone might be able to point me in the right direction to getting this sorted. The box isn't highly critical but it is starting to get annoying having to hard reset the box and I've now gotten to the point where it's common enough that the server is on a smart plug that I can remotely turn off/on when this issue crops up.
Thanks in advance for your help,
-
Hmm.. I got updated today and now Sonarr won't start.
I get a repeat of this block before it finally gives up and dies.
2021-03-09 21:08:59,097 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22543642412560 for <Subprocess at 22543642413328 with name sonarr in state STARTING> (stdout)> 2021-03-09 21:08:59,097 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 22543642573312 for <Subprocess at 22543642413328 with name sonarr in state STARTING> (stderr)> 2021-03-09 21:08:59,097 INFO exited: sonarr (exit status 2; not expected) 2021-03-09 21:08:59,097 DEBG received SIGCHLD indicating a child quit 2021-03-09 21:09:02,101 INFO spawned: 'sonarr' with pid 68 2021-03-09 21:09:02,113 DEBG 'sonarr' stderr output: Cannot open assembly '/usr/lib/sonarr/NzbDrone.exe': No such file or directory.
Forcing an update seems to have resolved this though. Might be useful for other people having the same issue.
-
Has anyone been able to get the external (remote) client IP address to forward to the proxied server?
I've skimmed a few pages and run a search over this topic but I can't find anything on getting the client's IP address to the server.
For clarity I'm running a site using IIS on Windows Server 2016, with Nginx Proxy Manager fronting the public requests.
My web server only ever sees the IP Address of the docker (my unraid server), which is problematic when my application has IP Address banning implemented for security - I've had to disable it incase someone cottoned on that they could effectively use my own security against me 😐
-
8 minutes ago, itimpi said:
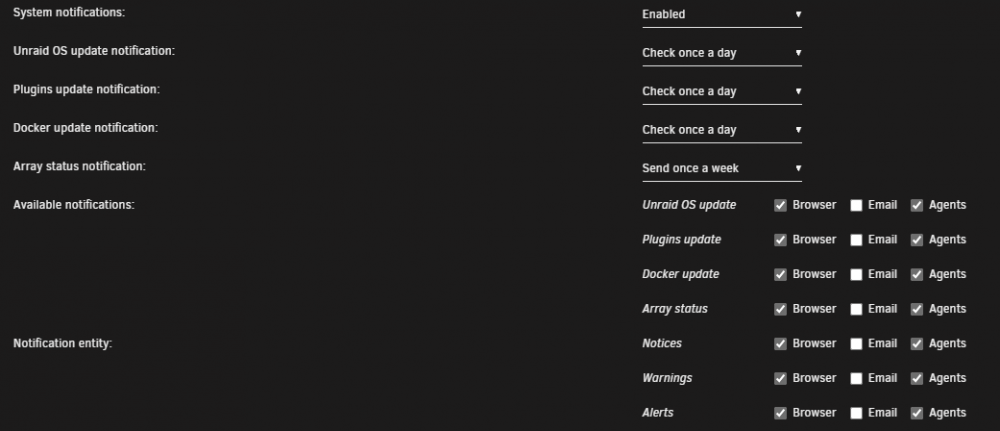
1) and 3) are already available via Settings >> Notifications
So they do, weird I get the plugin and docker updates but I've never had an OS update notification though.
I'll monitor for the next update.
Request two though would still be nice
")
-
Hey all,
Just thought of a potential new feature this morning - had a power cut last night, signed into unraid to start the array this morning and discovered there's a new update available.
-
Does unraid check for updates periodically and if it does, can a new notification option be added so that it sends a notification to configured clients? (I use Pushover which has been flawless so far). - As an additional option to the above, could we have an option to let unraid automatically download (but not install) the update and let us know that (as well as it being available above), that it's now ready to install?
-
Or disable the above all together as I'm guessing some people aren't too bothered.
Edit: 1 and 3 already exist as pointed out.
-
-
7 minutes ago, trurl said:
Do you have a backup of flash?
The last backup I have was taken while the USB device was in this state.
-
On 1/19/2020 at 2:22 AM, trurl said:
Put flash in your PC and let it checkdisk.
Are you booting from a USB2 port? You should.
Hi,
Yes it's booting from a USB 2.0 port.
I've run check disk, I got the message that there were errors and prompted to fix them, which I confirmed to do.
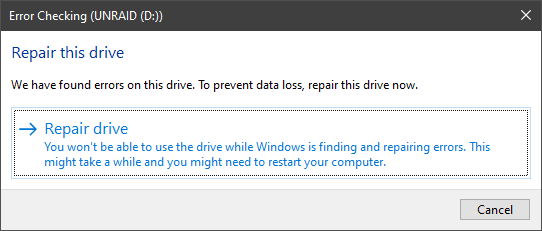
This takes a few seconds before returning this message:
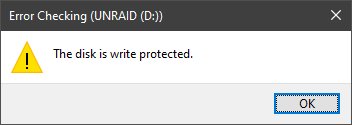
I've gone into CMD prompt, into DISKPART and run to clear the readonly attribute from the drive but it never changes the current read only state from the disk.
-
Hi all,
Pretty sure I've seen this posted before but I couldn't find it.
I've just tried to update my server to the latest version of Unraid but I received an error:
plugin: run failed: /bin/bash retval: 1
Trying to update plugins errored out with either the same error or a general failure:
plugin: updating: community.applications.plg Cleaning Up Old Versions plugin: downloading: https://raw.githubusercontent.com/Squidly271/community.applications/master/archive/community.applications-2020.01.18a-x86_64-1.txz ... failed (Generic error) plugin: wget: https://raw.githubusercontent.com/Squidly271/community.applications/master/archive/community.applications-2020.01.18a-x86_64-1.txz download failure (Generic error)
I've then got a small notification that the USB drive was not read-write.
The server was rebooted "just in case" and on loading, just before the final console login, it listed a bunch of dockers that couldn't open temp folders because of read-only.
I'm a little nervous as this is the first time I've actually had anything "go wrong" with my server.
The server booted up, has let me log into the WebGUI and has begun its usual parity check but the error saying USB was not read-write appeared again.
As a precaution, I've downloaded a flash backup.
The flash drive is only a few years old and is a Sandisk Cruzer Fit 16GB drive from Amazon.
Background aside, is this indicative of a failing USB drive?
Here's the disk log information:
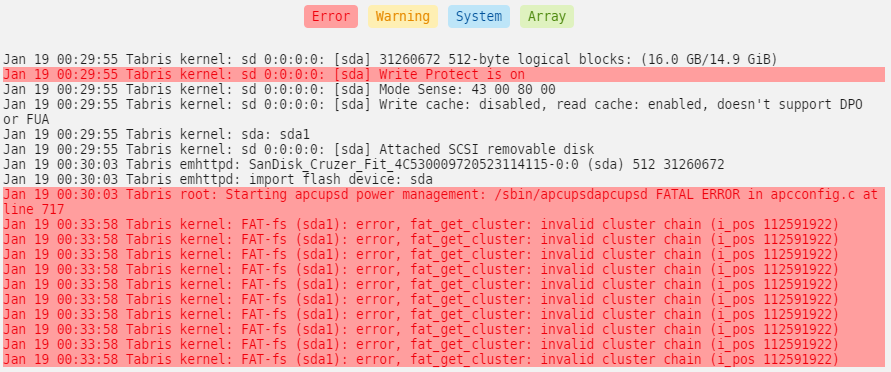
If this disk is failing, can I take the backup I've just made, get a new 32GB cruzer drive from Amazon, copy the contents of the zip over, re-licence the USB drive and carry on like nothing else happened?
Thanks,
S.
-
On 9/16/2019 at 10:43 PM, Michel Amberg said:
Hello I started getting this from my container today after an update:
2019-09-16T21:41:40Z E! [inputs.disk] Error in plugin: error getting disk usage info: lstat /dev/mapper/md1: no such file or directory
Any ideas? I don't get any array information anymore populated in my DB
This is a known issue in the current build and I believe a fix is going to be released on Tuesday for the main project.
When this particular docker will be updated is another story.
https://github.com/influxdata/telegraf/issues/6388
Hope that helps
EDIT:
While I know it's got nothing to do with this docker, this is why I wish unRaid would support an official API endpoint for dashboard information. For right now scraping the dashboard in C# and parsing the DOM using HTMLAgilityPack is having to suffice.. barely
-
On 9/10/2019 at 3:26 AM, Idolwild said:
I know it's been awhile, I have the same use-case (need NGINX to forward to internal IIS server - care to share any pointers? Thanks!
Sorry bud, I didn't even know you'd posted a response - I haven't had any notifications from the forum and only noticed when I popped on to ask a question about Grafana.
I can't remember what is was that I had a problem with for this container, let me post this and I'll have a scroll back and edit this once I've remembered!
-- EDIT
Well I looked back and I haven't got a clue what i was on about!
I do have everything setup and functioning so I would be happy to answer any specific questions you might have re the setup I use at this point.
-
On 8/19/2019 at 11:01 AM, Djoss said:
Did you try to add the settings under the Advanced tab of your host?
I've literally just come back to it today, tried that and was about to post that it's worked for me before I saw your post.

Had no idea if it was going to work or not but it was a shot in the dark that got the mark for me.
Thank you anyway!
-
On 12/29/2018 at 10:07 PM, Djoss said:
This docker is for people with little to no knowledge about nginx. It was not done with manual configuration file editing in mind. Some static configuration files are inside the container itself (/etc/nginx), while generated files are stored under the app data folder.
If you want to migrate from LE docker, you should not try to replicate your config files, but instead, use the UI to re-create the same functionality (again, this container doesn't support subfolders yet).
Hi,
I have a need to access the nginx.conf file to try and fix a problem I'm having with larger header sizes with IdentityServer.
Specifically in relation to: https://stackoverflow.com/a/48971393/4953847How can I set the following values for this container?
http{ ... proxy_buffer_size 128k; proxy_buffers 4 256k; proxy_busy_buffers_size 256k; large_client_header_buffers 4 16k; ... }Currently I'm able to authenticate my app but I immediately get redirected to a 502 Bad Gateway from nginx.
-
Hi,
Just as the title suggests - I'm getting to a point where I'm using a lot of docker containers for various purposes - Ombi, Plex, Sab, Radarr & Sonarr as well as other nginx sites and (thank you linuxserver guys) a Visual Studio Code implementation too. But it's getting really crowded. I don't really need to see telegraf, HDDTemp or influx and without shifting the order around on the Docker tab, there's not really a way to organise things better.
I would like to see some ability to group docker containers, optionally show/hide specific groups from the dashboard (for more critical dockers only).
Being able to start/stop/restart the whole group at once would be an added bonus but not essential.
For some idea of how i would see this being done, is that you could have under Settings/DockerSettings a section to add/remove docker groups, and to add a container to a group would require editing the container, and not being able to remove a group until it was empty, again editing applicable docker containers to either change their group or ungroup them.
I don't know if I'm actually miss-using unRaid or if people don't tend to have 25/30 docker containers running without the need to organise them into groups?
Thoughts?
-
Stupid question numero uno.. how do you "log out" once you're in when password is used to secure?
PS. This is a freaking awesome tool when I'm about with the ChromeBook.
-
Hi,
Not sure if this has been raised before or if other people have just found ways around it, but could we have some method to selectively (per specific container), have an auto-restart if certain conditions are met?
Such as:
- RAM usage above a set limit
- Specific "health-check" port not responding
- On a cron schedule?
I've also noticed some containers fail to start at all sometimes, or a stuck on a startup loop.
In cases like this would there be room to forcibly stop a container and send a notification out if a container is looping or has been forcibly shutdown as a result?
My reason for asking is that occasionally I've had to restart Plex Media Server as it's hogging 4-5GB of RAM while idling, and today SABnzbd-VPN was totally unresponsive on the local port and when checking the log noticed it was continually not seeing DNS for PrivateInternetAccess and looping - a forced stop and start resolved it immediately.
What's everyone else's experience here? Worth a feature add?
-
On 5/12/2019 at 10:44 AM, bonienl said:
You need to create a new container and choose an existing template. Next rename the new container and change settings.
For example I have six Pihole containers running (each network has its own DNS server). They all have a unique name and settings folder.
This is going to sound stupid, but how did you change the setting folder for the new container?
I've got so far as going into the Docker tab, adding a new container, selecting a template from the list of user templates (in my case I'm selecting the Nginx container I already have) and setting the name to something different.
I can't see a setting in either basic or advanced that lets me specify the appdata folder name.
I thought it might be based on the name I enter for the container, but it just uses the appdata folder from the template I selected.
Edit:
Was stupid, found it under the "Show more settings" bit...
-
I'd like to set up email alerts from Grafana but the settings page is read only.
There's a banner that states that the settings are defined in grafana.ini or custom.ini or set as ENV variables.
I've tried looking in the appdata folder for Grafana but I can't see either of the name files.
I've also tried setting up a variable in the docker edit page and restarting the app but it doesn't work.
How do I go about changing the settings for Grafana?
Thanks,
-
Hi all,
Just want to sense check something since I'm not really familiar with hardware support.
I currently have a Gigabyte H81M-S2H motherboard, which has now run out of SATA connections and I'm about to run out of space.
I'm looking at expansion cards and I think an 8-port HBA card is the right option, specifically:
LSI SAS 9207-8i KIT 8-Port 6Gbps SATA+SAS PCI-E 3.0 HBA Kit on Amazon
Before I commit to buying it and a couple of extra drives, I just want to know if the card itself should work without any hassle.
Thanks
-
I've seen this before as well, adblocker was the culprit pulling down whole sections of the unraid ui in error.
Added unraid to the exceptions list and everything works fine again.
-
Just now, eschultz said:
Both of these issues should be solved now, please let us know if it's still not working for you.
Seems all good now.
I haven't seen the template error again and I can view everything else just fine. -
Ah Gotcha,
That will be what this is then.. almost thought for a sec that it was actual content for something until I read it;

-
I'm getting an odd issue where I can't view any of the Bug Reports / Pre-release threads for the the RC releases.
While logged in, I try to view;
But I get an error message like this;
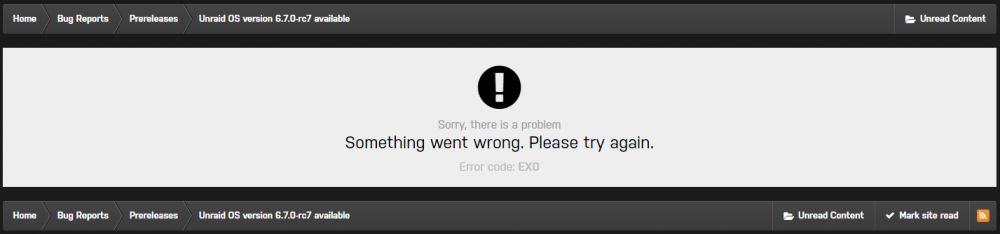
This is only while logged in, if I log out from this error screen, I remain on the thread but I am able to view and navigate through it without a problem.
-
Would you never want to be notified of genuine short outages or just alert if they last longer than a set period?
Perhaps if there was a weekly / monthly digest of un-alerted notifications?
EDIT:
I suppose if you have Grafana in play, you could use its reporting services?
-
Got myself a coffe mug for the growing collection of beverage receptacles today. :)
-
 1
1
-









Full System Halts
in General Support
Posted · Edited by Saldash
Hi All,
I wrote some time ago that I was experiencing what appeared to be somewhat random system halts where the only way to resolve it was a full power off as the plug, wait and reboot.
There would be no apparent cause for this but for a while it stopped happening, so I let the issue go.
It has recently started flaring up again with a vengeance, so much so now I have a smart plug attached to the machine so I can remotely cut power and reboot.
I still don't know for sure why this is happening and I'm not sure where to start.
I've tried looking in the syslog but it only appear to start from the time the system came back online after it's last reboot, which is no good.
I think there may be a correlation between the system halts and disk usage - A parity check is scheduled for 2AM every Sunday morning, and that is roughly when the machine stopped responding.
Looking at the power monitoring data my smart plug provides, you can see the halt, shortly after 2AM when the parity check starts, then a long stretch of idling at ~80 watts before I cut power and rebooted earlier this evening.
My machine typically idles about the 50 watt mark as I'm the only user, it serves very light NAS duties but does handle downloading and local plex media streaming.
All my drives are reporting a healthy state and I've never seem the error count on them above zero.
I've run self tests on all my drives but they all report completed without error.
I'm not sure what to do next with this other than bite the bullet and move to a Synology or QNAP box 😟
EDIT:
I Turned on the SysLog server and pointed Unraid back at itself to log events, then triggered a Parity check.
I got about 0.8% before the server crashed.
It does not appear to have logged the issue though as the crash occurred at 00:34
tabris-diagnostics-20230108-2347.zip