

-
Posts
134 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by HNGamingUK
-
-
It was mentioned today on the unoffical Discord that when you shutdown the array it has the potential to hang and does not inform you of any open processes and expects you to find them and close them before it will finish the shutdown.
This request is therefore to add a prompt in the GUI (maybe also CLI) that when a user issues a command that will shutdown the array to display a message to the user. This message would be something to the affect of "The following processes are stopping shutdown of the array" at which point it lists the processes and PIDs. (Likely will need to have this auto refresh as other processes could start to use the system)
In addition to the simple message, it could include a prompt asking the user if they would like to kill the processes and force the array shutdown.
I believe adding such a feature will be a very good addition and improve the overall user experience.
-
1 minute ago, wgstarks said:
The first two aren't important. If you scroll up a little you'll see that there has been a bit of discussion about this today. I believe most people solved the last one by switching endpoints.
Yeh I saw the only thing is that due to this being a new setup there is no wireguard .conf file in the wireguard directory for me to be able to change the endpoint....
-
Hello I am trying to start a container from fresh using wireguard and PIA but I am getting the following in the docker logs?
2021-04-15 00:15:40,475 DEBG 'start-script' stderr output: parse error: Invalid numeric literal at line 4, column 0 2021-04-15 00:15:40,600 DEBG 'start-script' stderr output: parse error: Invalid numeric literal at line 1, column 7 2021-04-15 00:15:40,600 DEBG 'start-script' stdout output: [warn] Unable to successfully download PIA json to generate token from URL 'https://143.244.41.129/authv3/generateToken' [info] Retrying in 10 secs...
I assume this just means it's an issue with PIA and I just have to wait? But was also concerned about the previous two parse errors...
-
1 hour ago, Squid said:
I'm aware of it
")
Appologies to sound like an annoying teenager, but do you have an ETA or maybe roadmap of features. Equally is there a github page for this so that maybe people can help develop the feature?
-
Hello Limetech,
Talking in the unoffical discord we noticed when you add a new container and click apply it runs a docker run however when you edit a stopped container it does a docker create
Now this method is okay however some people would like the option to not have a container to start on creation.
Essentially the feature request is to add a tickbox called something like "Start container on creation/edit" on a container creation and edit page. By default this would be ticked so that it does not affect the current usage of the containers and does not cause any confusion.
Potentially in addition an option within the Docker settings page could be added to change how the tickbox works by default.
Hopefully this makes sense.
-
 1
1
-
-
This has been requested atleast once before by @aptalca back in 2018 however this still doesn't seem to have been implemented?
Basically instead of one tarball of all the appdata directories, please could we have the option to have it seperated per directory? This will make a restore much easier for people who only want to restore one application. Currently they would have to manually untarball the file and move the directory.
So the feature request is:
Backup:
In the backup config page have a option called "Backup Directories Seperately"
If this option is selected it will backup each directory in the provided appdata directory into a time and dated folder within the provided backup directory.
In addition to this if the "Compression" option is ticked then compress each directory.
Restore:
When someone chooses the restore option, along with the date/time selection provide a directory selection to restore (using checkboxes to allow for multiple selections and an "all" option to restore everything)
Hopefully this is enough detail for the feature request to be actioned... @Squid
-
4
-
-
3 hours ago, Phaelo said:
Restarted array and I was able to get the SMART data on the drive now, attached.
Reading the SMART data suggests the disk is fine, I would first check the cables to the disk (power and SATA)
If everything looks fine you should be able to:
1. Stop Array
2. Un-assign drive
3. Start Array
4. Stop Array
5. Assign Drive
6. Start Array
Once this has been complete the drive should be added back to the array and any data changes that have happened to the emulated drive in the meantime will be written back to it.
-
+1
This feature is deffinately required from a UX perspective!
-
For reference to anyone in the future I have fixed this by doing the following:
Removed br0.20 from unraid network settings
Set Windows VM network to br0
Set vlan tagging inside the Windows VM for VLAN 20
This has allowed for my Windows VM to connect to the correct subnet and also allows me to manage my unraid webui and docker uis also.
-
9 minutes ago, PeterNet said:
Well, then it no longer works as it used to do in v5.
Turning on the cache, it was transparent with the Disk Array share.
I just saved files to:
192.168.x.x\sharename\folder1\folder2\etc...But instead of being placed directly on the main array, the files were placed on the Cache disk (with a copy of the folder structure).
Then doing the Mover, it would transfer everything to the actual Disk Array.
So that is no longer possible then?
I would check the "Cache" setting of the share in question and confirm that it hasn't been set to "No"
-
Hello,
So as the title suggests I am unable to access my dockers that are in default bridge mode from a Windows VM (on unraid) from a VLAN (br0.20)
Here is what my unraid network config looks like:
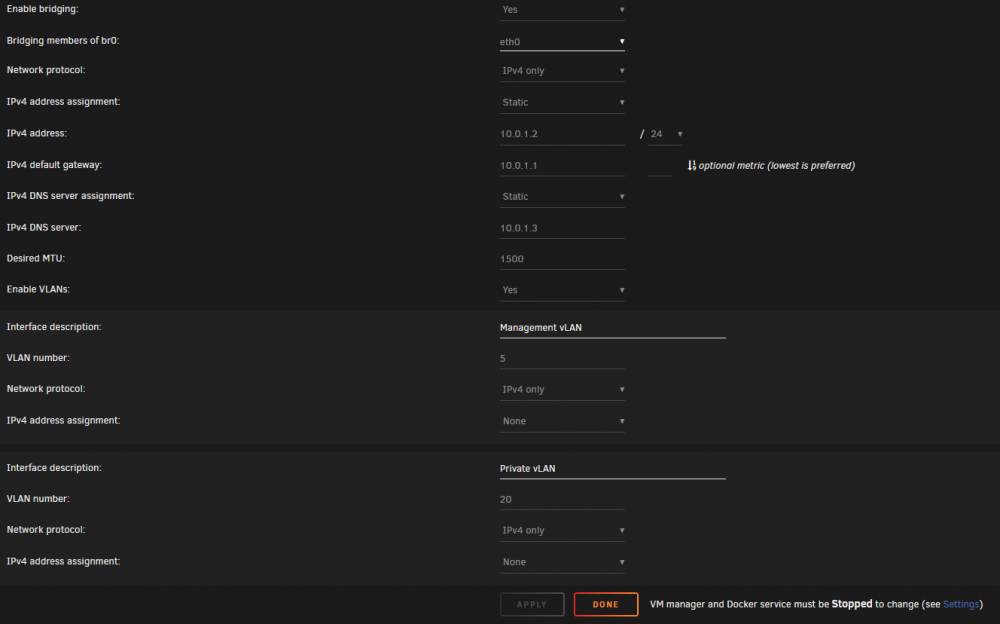
Here is a screenshot of my dockers :
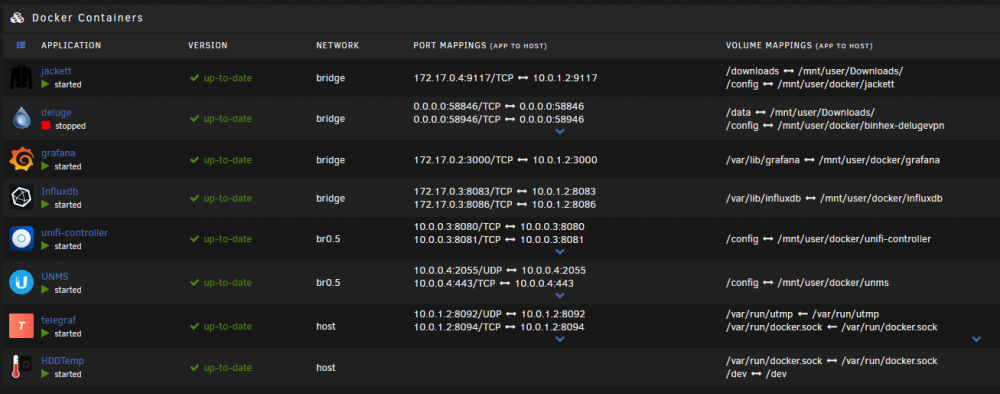
While on my Windows VM (which has it's network as br0.20) I am unable to access the docker containers on the standard bridge mode (eg Grafana) however I am able to access the dockers using custom networks (eg UNMS).
My network setup as follows:
br0 (Standard bridge) is on a 10.0.1.0/24 subnet
br0.20 (VM assigned) is on a 10.0.2.0/24 subnet
br0.5 (2 of the dockers) is on a 10.0.0.0/24 subnet
I am able to access any of the dockers webUIs from a mobile device on the same subnet as my Windows VM. I believe this has something to do with the network isolation between dockers and VMs am I right?
How would I go around allowing access from the Windows VM to the dockers on the default bridge?
-
11 minutes ago, Squid said:
It calls the update script to check for and install updates at the time the backup runs
Okay brilliant so setting the following in Auto Update:

and then the following in backup:
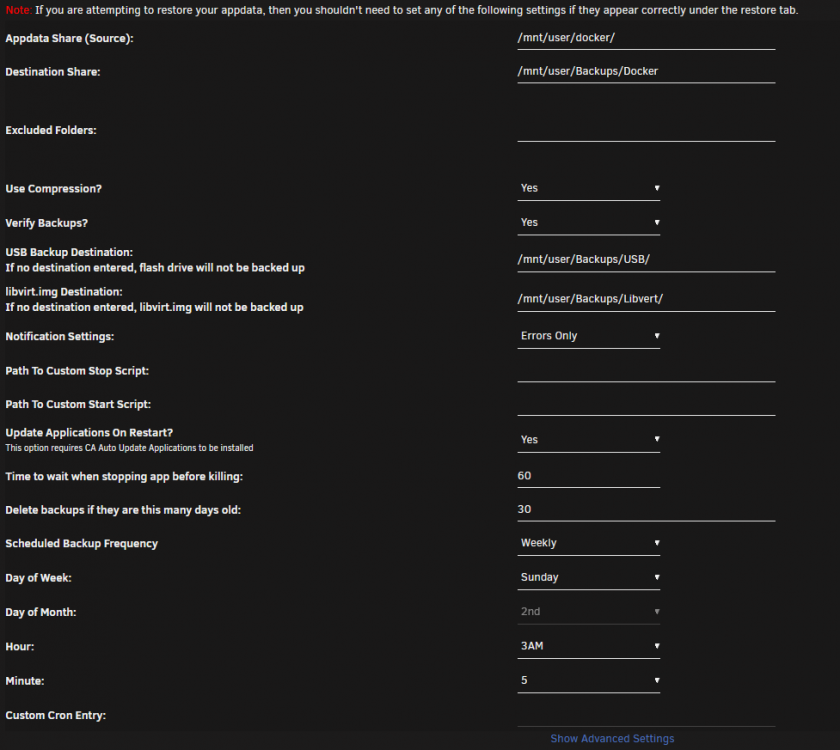
Will backup every Sunday at 3:05 and once complete trigger an update.
-
Could someone explain how the "Update Applications On Restart?" setting works on this plugin?
If I have this set to yes what should I set in the "CA Auto Update Applications" settings?
-
Just now, testdasi said:
Indeed the limit is for the kernel to know when to kill a docker.
I don't think the docker itself is even aware of the limit (perhaps it can be aware but I don't think that piece of code implemented in all the dockers that I can tell).
There's also a side effect for setting docker memory limit is that it is less likely to kill your VM if you actually run out of memory. So don't just go undo all your docker limit.
Yeh I didn't want my VM to die randomly as I use it for gaming.
I will have a look at working out some better docker memory limits. Thanks for helping me understand how it works.
-
7 minutes ago, testdasi said:
The 70% utilisation you see right now is after the offending process has been killed so it's likely a red herring.
OOM error happens if (a) you actually run out of memory or (b) a docker runs over its memory limit or (c) unusual problem
Did you set the dockers memory limits before or after mysql docker was killed?
If before then you need to increase the limit for mysql as it was killed because of reason (b) above.
And OOM is not an urgent issue to fix as long as it doesn't kill your running docker / VM.
Side note: Reason (c) is really unusual and not something you need to worry about. For example, my TR4 server with F12 BIOS will have OOM error if I allocate more than 50% RAM all at once (e.g. start a VM) while having Global C State disabled (enable C state and no more error).
Yes I set the MySQL and other docker limits before MySQL was getting killed.
I assumed that if the container got close to the limit it would just not use more, but reading your messages suggests that if it goes over the limit I set it will just kill the docker?
-
Hello,
For reference my server has 32GB of RAM.
I wonder if anyone else is able to help me, I am unsure on what is causing this and what I can do to stop it.
So far for the past couple of nights I have had fix common problems send an alert about out of memory errors and when I login I see that the MySQL docker has stopped. (Only this one stops so I am guessing OOM killer decides to kill that one for whatever reason)

However my memory on the dashboard is hovering around 70% max so I am unsure on what is causing it.
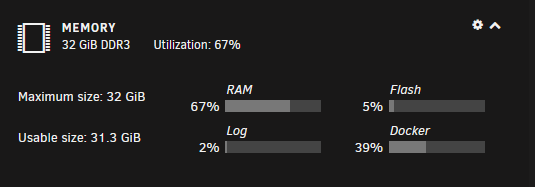
I have set each docker to have max memory so that they can't randomly use more memory, however it still keeps happening.
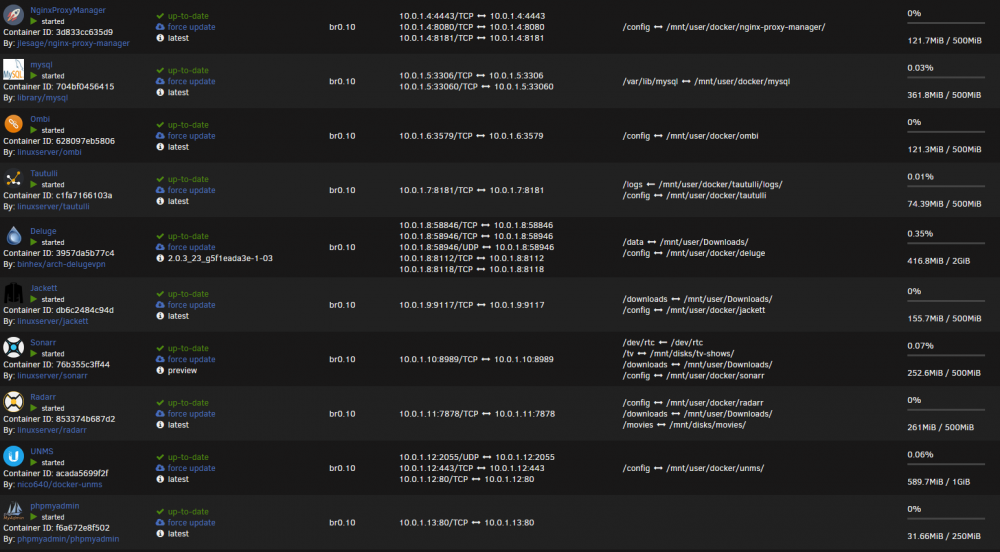
The only other item that I run contstantly is a Windows VM (16GB assigned to it) and as such should leave 16GB for the dockers and system.
I have also attached my diagnostics, if anyone can help me find out what is causing this it would be wonderful. I don't have the capcity to just upgrade my RAM currently and so need to fix this issue. diagnostics.zip
-
7 hours ago, trurl said:
Okay great that information helped.
As I had the secondary cache working and all the data was there I just copied it from the single drive cache pool to the array. I then stopped the array, assigned the primary cache back and started the array. I then ticked the format box and started the format of the primary cache.
As expected this formatted the cache pool, so all I had to do is restore the files to the cache and everything was back to normal.
Just so I know for future, reading the errors shown can someone explain what happened?
-
24 minutes ago, jonathanm said:
It would appear the qm command is specific to proxmox, not a generic QEMU-KVM command.
Yeh it seems that way, unsure if it is possible to do with the current setup unraid/lime tech use. But it would be a nice feature to allow live disk expansion as most newer operating systems would support it.
-
Hello,
Wondering if anyone can help me with an issue I am having with my Cache pool. Basically after a reboot today, when I started up the array I saw the following:

Along side this I see the below asking me if I want to format the primary cache drive. Now obviously I do not want to as I don't want to loose data.

I then ran a btrfs check --readonly /dev/sdb1 which came with the following output:
Opening filesystem to check... Checking filesystem on /dev/sdb1 UUID: ab81d341-8531-4c08-8fa1-645911b301fd cache and super generation don't match, space cache will be invalidated found 310226411520 bytes used, error(s) found total csum bytes: 0 total tree bytes: 90783744 total fs tree bytes: 29900800 total extent tree bytes: 60588032 btree space waste bytes: 16964433 file data blocks allocated: 156191051776 referenced 154714845184
I then did a btrfs check --repair /dev/sdb1 which showed the following:
Starting repair. Opening filesystem to check... Checking filesystem on /dev/sdb1 UUID: ab81d341-8531-4c08-8fa1-645911b301fd [1/7] checking root items Fixed 0 roots. [2/7] checking extents incorrect offsets 12845 12358 incorrect offsets 12845 12358 incorrect offsets 12845 12358 incorrect offsets 12845 12358 Shifting item nr 94 by 487 bytes in block 1254219743232 Shifting item nr 95 by 487 bytes in block 1254219743232 Shifting item nr 96 by 487 bytes in block 1254219743232 Shifting item nr 97 by 487 bytes in block 1254219743232 Shifting item nr 98 by 487 bytes in block 1254219743232 Shifting item nr 99 by 487 bytes in block 1254219743232 items overlap, can't fix check/main.c:4336: fix_item_offset: BUG_ON `ret` triggered, value -5 btrfs[0x42f27d] btrfs[0x43842d] btrfs[0x438960] btrfs[0x43950c] btrfs[0x43d495] btrfs(main+0x90)[0x40ecc0] /lib64/libc.so.6(__libc_start_main+0xeb)[0x1473a7ed6e5b] btrfs(_start+0x2a)[0x40ef4a] Aborted
So at this point I am stumped on what to do to resolve the issue.
I have been able to set the primary cache as no device and then start the array at which point it seems the secondary cache drive is working fine and has all the data I need. However preferably I do not want to run at a reduced redundancy for an extended period of time.
If I am infact being stupid and do need to format the primary cache drive to then make it re-sync the raid I can do that. Any help infact would be very much apprriciated.
Appologies this post is VERY long, I just wanted to make sure that I covered all the options I could find before asking for help.
-
On 4/5/2020 at 2:02 PM, jonathanm said:
Can you link to official documentation that walks through the live expansion? All I can find are work arounds and hacks that come with data loss warnings. I guess my google-fu is failing me.
For Proxmox here is the documentation: https://pve.proxmox.com/wiki/Resize_disks
Although looking further it may seem that Proxmox uses a different vdisk handling method not sure myself. I just know it is possible with Proxmox both in the GUI and via CLI
-
10 hours ago, jonathanm said:
Where are you seeing that it's even possible to expand a KVM guest vdisk without stopping it? The googling I've done suggests it's required to stop the guest.
https://computingforgeeks.com/how-to-extend-increase-kvm-virtual-machine-disk-size/
When the guest is stopped, it's easy to expand the disk from the GUI, on the VM page click on the NAME of the VM, and click on the disk capacity. Enter the new larger number with G modifier and hit enter.
NEVER EVER EVER set a smaller size. I know that's not what you asked, I'm just posting as a reference if someone searches and finds this answer thinking they can shrink a vdisk just as easily. You can, but you will break the vdisk permanently, and probably not be able to recover your data.
Proxmox would be my example of live disk increase, it uses QEMU KVM.
-
Hello All,
I was wondering if someone will be able to help me. I am running a Windows VM and preferably don't want to have to turn it off to increase the disk.
From what I can see it can't be done via the GUI? Is this a new feature that needs to be requested?
In either case what would be the best command to run to increase the disk?
Many Thanks
-
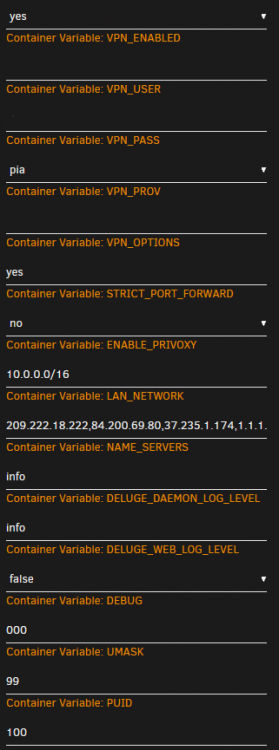
Hello,
Is anyone having issues with PIA (specifically the france enpdpoint) I am getting the following:
2020-03-31 07:16:56,249 DEBG 'start-script' stdout output: [info] PIA endpoint 'france.privateinternetaccess.com' is in the list of endpoints that support port forwarding 2020-03-31 07:16:56,249 DEBG 'start-script' stdout output: [info] List of PIA endpoints that support port forwarding:- [info] ca-toronto.privateinternetaccess.com [info] ca-montreal.privateinternetaccess.com [info] ca-vancouver.privateinternetaccess.com [info] de-berlin.privateinternetaccess.com [info] de-frankfurt.privateinternetaccess.com [info] sweden.privateinternetaccess.com [info] swiss.privateinternetaccess.com [info] france.privateinternetaccess.com [info] czech.privateinternetaccess.com [info] spain.privateinternetaccess.com [info] ro.privateinternetaccess.com [info] israel.privateinternetaccess.com [info] Attempting to get dynamically assigned port... 2020-03-31 07:16:56,254 DEBG 'start-script' stdout output: [info] Attempting to curl http://209.222.18.222:2000/?client_id= 2020-03-31 07:16:56,282 DEBG 'start-script' stdout output: [warn] Response code 000 from curl != 2xx [warn] Exit code 7 from curl != 0 [info] 12 retries left [info] Retrying in 10 secs...Settings:
-
1 hour ago, Turrican said:
Thanks, ill try a new provider. Will go either Mullvad or Surfshark, unless anyone has anything bad to say with them for this setup.
May I ask why you are going for the smaller brand VPN providers as apposed to say PIA, AirVPN or NordVPN?











Prompt on shutdown of the array to close open processes
in Feature Requests
Posted
The plugin would work yes however it automatically stops the sessions without any user input or knowledge.
My feature request is for a prompt and list so the user has full knowledge of the process(es) stopping shutdown of the array and can action it all within the unraid UI.