

-
Posts
134 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by HNGamingUK
-
-
15 minutes ago, raiditup said:
I had that problem too. Before you do this next step to fix that issue, make sure you stop the delugevpn container in the unRAID webGUI.
After delugevpn is stopped, edit the core.conf file in /mnt/user/appdat/binhex-delugevpn/core.conf
nano /mnt/user/appdat/binhex-delugevpn/core.conf
Change the "enabled_plugins" setting to the following
"enabled_plugins": [
"ltConfig"
],This should enable the plugin on startup.
Okay so I use the Label plugin and it currently has:
"enabled_plugins": [
"Label"
],Do I just change that to:
"enabled_plugins": [
"Label""ltConfig"
], -
20 minutes ago, raiditup said:
The 2.0.4 label is either a typo by the dev team or is an early beta of 2.0.4. In any case that version, it's the version I'm using and it works with the ltConfig plugin. To get the plugin working, you'll need to compile it from scratch using the python version that's used in the container.
Instructions
On the same page you tried download the .egg from, https://github.com/ratanakvlun/deluge-ltconfig/releases instead download one of the compressed Source Code files. Extract the folder and copy or scp it to the plugins folder of the delugevpn container. e.g. /mnt/user/appdata/binhex-delugevpn/plugins on your unRAID server.
Now go to the webGUI of your unRAID server, click on the Docker tab, click on the icon of the delugevpn container and open the Console. In the console, go to the Source Code folder you just uploaded in the plugins directory which will most likely be in /config/plugins. Then compile the plugin.
cd /config/plugins/deluge-ltconfig-2.0.0
python setup.py bdist_egg
The compiled egg will be located at /config/plugins/deluge-ltconfig-2.0.0/dist/ltConfig-2.0.0-py3.8.egg. Copy it to the root of the plugins directory.
cp /config/plugins/deluge-ltconfig-2.0.0/dist/ltConfig-2.0.0-py3.8.egg /config/plugins
You may need to restart your delugevpn container after this, but the plugin should now show in the WebUI of Deluge.
In the Deluge WebUI, go to Preferences -> Plugins and enable the ltConfig plugin. A new ltConfig menu option will become available inside Preferences.
Click ltConfig and make sure "Apply settings on startup" is checked. Scroll down the menu until you locate
enable_outgoing_utp
enable_incoming_utpMake sure these two settings are unchecked and Apply the changes.
Restart the delugevpn container one more time and double check that the ltConfig plugin loaded on startup and the two settings are unchecked.
Enjoy your faster torrent speeds again.
Well I was able to build the plugin and it shows on the plugins tab.
The only issue I have is I can enable the plguin in the plugins tab and do the "Apply settingsd on startup", I make sure enable_outgoing_utp and enable_incoming_utp are disabled.
However when I reboot the docker it disables the plugin in the plugins tab...
-
3 hours ago, raiditup said:
This has been an ongoing issue for a lot of users of PIA and Deluge. You need to install a Deluge plugin called ltConfig, but unfortunately it doesn't work with the latest version of Deluge (2.0.4), which the docker is currently on.
Your only option is to rollback your docker container to the last release of 2.0.3, binhex/arch-delugevpn:2.0.3_23_g5f1eada3e-1-03 and reinstall the ltConfig plugin. The process is a little involved because it requires compiling the beta version of the ltConfig plugin (2.0.0) inside of the docker container. Once the plugin is installed and activated within Deluge, you need to disable the following two settings within the ltConfig settings and your torrent speeds will be back to normal.
Uncheck These
enable_outgoing_utp
enable_incoming_utpIf you need help with any part of this process, let me know. I know how frustrating it can be.
Okay so I have downgraded to the version you mentioned however I did try and be lazy and use the egg https://github.com/ratanakvlun/deluge-ltconfig/releases
Which did not work... If you could kindly describe on what needs to be completed? (On a side note I did downgrade to 2.0.3_23_g5f1eada3e-1-03 but my browser bar is still showing "2.0.4.dev20")
-
 1
1
-
-
Anyone else been having speed issues with this docker and PIA?
I have done a fresh install of the docker and tried each of the endpoints that allow port forwarding.
I then tested using the ubuntu 19.10 iso torrent and the max I got with each endpoint was 1.8MiB/s
I remember before getting 10MiB/s if not more, I have no idea what has changed though.
-
16 hours ago, ezhik said:
This is a solid feature and I can attest to the importance of it. TOTP can be used with Google Auth, but I would strongly recommend Authy as it allows backing up the seeds and encrypting it. There is also multi-device support.
Can we have TOTP for SSH as well? https://github.com/google/google-authenticator-libpam .
NOTE: This will obviously have impact on 'not-so-tech-savvy-users', but those who sleep in tinfoil hats, will definitely appreciate it.
From what I have seen anything that says "Google Auth" you can use Authy.
-
On 2/1/2020 at 3:48 PM, Squid said:
Yes
Thanks Squid the VFIO Bind option has worked and the VM now boots without any issues.
-
12 minutes ago, Squid said:
If you use the VFIO-bind method to block out the other devices from the OS, then they will probably appear in "Other Devices"
Okay, I'm assuming that will also need a reboot?
-
Just now, Squid said:
Doubt if ACS override will help here, but it won't hurt. The problem is that your video card also includes a USB controller which must also be passed through to the VM.
Hmm and how would I go about passing the USB Controller of the GPU to the VM as that doesn't look to be an option within the GUI. I'm guessing I will need to switch to XML view and add it?
-
Hello,
I am getting the following error when trying to pass through my RTX 2060 Super to my virtual machine:
"internal error: qemu unexpectedly closed the monitor: 2020-02-01T14:27:59.749795Z qemu-system-x86_64: -device vfio-pci,host=0000:01:00.0,id=hostdev0,x-vga=on,bus=pci.0,addr=0x6: vfio 0000:01:00.0: group 1 is not viable Please ensure all devices within the iommu_group are bound to their vfio bus driver."
Please see image of my iommu groups:

Virtual Machine configuration:
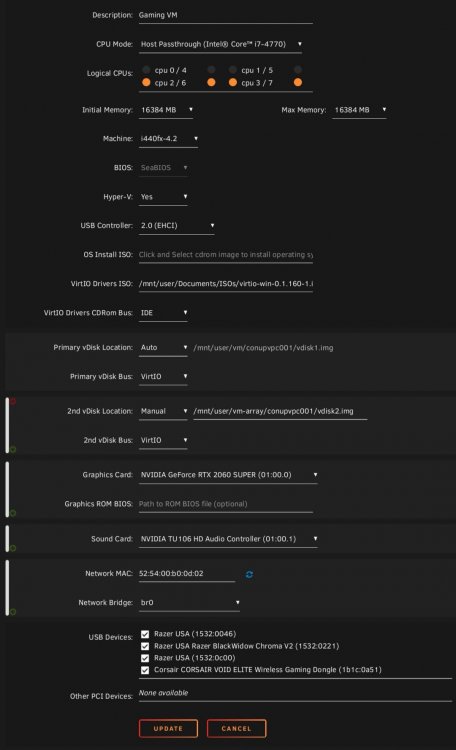
Looking on some other posts it seems to suggest that I will need to turn on PCIe ACS.
Wanted to see if anyone had any other suggestions as currently I'm running a part sync as I'm adding a second parity drive. So can't reboot at the moment.
-
2 minutes ago, BRiT said:
/var/log/ is is RAM.
It will all be removed on reboots.
Since it's in memory, the more you store the more it uses. If you don't have enough memory it will lead to OOM - Out of Memory errors and the kernel will pick randomly what programs to kill.
Thought as much, one of the script has been running since this morning at 8:00 and is at 7.2KB.
Will need to watch it over the next 7 days and see how large the files and rotated logs get.
All it stores in the log is when the move starts and when it finished with how long it took in seconds. So 2 lines. The script is running every 10mins unless it is already moving. So it has the potential to write 2 lines every 10mins.
-
Hello,
I have 2 scripts that automatically move files from local storage to GDrive. I currently have the logs going to a user share under /mnt/user/rclone/logs
I also have setup logrotate in /etc/logrotate.d to rotate the logs daily and keep 7 of them.
I wanted to know if it's okay to store logs in /var/log instead?
-
3 hours ago, Squid said:
Taken from the mover script,
PIDFILE="/var/run/mover.pid" if [ -f $PIDFILE ]; then if ps h $(cat $PIDFILE) ; then exit 1 fi fi echo $$ >/var/run/mover.pid . . .One thing I just noticed is that when you echo the current PID into the pid file you use the full path instead of using the $PIDFILE to reference it?
Equally the same once the script has run I should put rm -f $PIDFILE at the end
-
35 minutes ago, Squid said:
Taken from the mover script,
PIDFILE="/var/run/mover.pid" if [ -f $PIDFILE ]; then if ps h $(cat $PIDFILE) ; then exit 1 fi fi echo $$ >/var/run/mover.pid . . .Sorry I'm failing to understand how exactly that if statement works.
I think if I am understanding it correctly it will check if the pid file exists then if it does it will compare the current pid with the pid in the pid file. However I'm unsure what it does after that...
-
6 minutes ago, Squid said:
What I usually do is
- See if /var/run/scriptName.pid exists
- If it doesn't, write the pid to that file and execute the script
- If it does, read the pid from the file and see if that pid is actually running. If its not then execute the script
Hello,
How would you go about doing this exactly?
-
8 minutes ago, Squid said:
this
Okay, so I added the following to the start of the script that should work right?
if pidof -o %PPID -x "$0"; then
exit 1
fiJust thought I should add that I'm planning on having 2 scripts one for my TV Shows and one for Movies.
-
Hello,
I have a script which moves TV shows from local storage to my Google drive crypt. Can someone explain how the scheding works?
For example I want to set the move script to run every 10mins. However if there are a large amount of files in the directory it could take a while to finish.
How does user scripts handle this? Will it just not run the script or do I need to add some code in my script to handle this?
Hope this makes sense.
-
I love how easy it is to add more storage capacity compared to regular RAID. I also love how much unraid has improved over the years.
In 2020, I would like to see multiple arrays and possibly multiple cache pools. Would be nice to have a share span those said arrays too. That way someone could have 60 or more drives and store close to or more than a 1PB in a 4U chassis.
-
Hello,
UPDATE: So it seems that as I am unable to set static routes within the ISP provided router I would be unable to get this working. As a temporary measure I have put the server back into the working VLAN. I have contacted my ISP to confirm if there is actually a way to set static routes on it and if not then I will need to see if I can set it into modem mode and get a separate wireless router (such as TP Link) which will support static routes.
I recently got a new Ubiquiti EdgeSwitch 48 Lite and it seems that other subnets are unable to access the internet.
Example:
My unRAID server is on VLAN 3 with the IP of 10.0.0.2 with the Switch being 10.0.0.1
My ISP provided router is 192.168.0.1 and connected to port 1 of the switch, which is part of VLAN 2 and has an IP of 192.168.0.2
I have routing on the switch and setup routing for each VLAN however it is still not working. Unsure if someone from here can help?
unRAID network page:

EdgeSwitch Route Table:

-
15 hours ago, PhiPhi said:
I so use Krusader and sometimes the performance is really good but inconsistent especially when moving or copying large amounts of data which can take many more hours than for example; copying the same data within a Windows server running on lesser hardware.
Strange when you think about it, Unraid as a storage/NAS OS but doesn't have a reliable fast and full featured file mover. Sitting at your client unable to close the Krusader tab for 15 hours or close the client machine is far from a good solution.
I mean if you are thinking it to be equivalent to say a Dell storage array, then I can tell you that they don't have file moving facilities. Not to mention you can move/copy files with linux mv and cp respectively.
or there is midnight commander
-
2 hours ago, nfwolfpryde said:
Thanks, that makes sense. My cache disk failed a week or so ago, and I replaced it. Must have rebuilt it wrong. I’ll experiment tonight with the fix!!
If you want to get things within your docker share back on cache then the best method would be to set it to "Prefer" then run the mover this way any files on your disks will be moved to the Cache. It is then up to you if you want to set the Cache to "Only" or leave it to "Prefer"
-
2 minutes ago, Ancan said:
No I think there's room for improvement here. I bit worried about the lack of notifications.
Yeh I'm unsure why it waited for the parity sync for it to display a notification about the removed disk..
Would need a more experienced user with unraid to see why...
-
8 minutes ago, Ancan said:
Parity is now green as well. Just as green as Toshiba disk on my desk here beside me. Perhaps I should post on the bug-forum instead?

I'll stop the array now, and replace the Toshiba with a new disk instead. Let's hope Unraid will let go of it then.
Edit: About time!!!
Ah so likely due to the parity sync running.
Although I don't think that should be the correct course of action by unraid....
-
17 minutes ago, Ancan said:
Kudos on commitment for pulling a drive!
I've got notifications set to "browser" only while I'm testing, and haven't seen anything except the "errors" popup. Disk still green in the GUI, even though it's sitting here on my desk.
I should mention that my paritity is not fully synchronized yet, and was not when I pulled the disk. I'm being cruel I know. I validate enterprise storage installations as part of my job, and am a bit damaged by that probably.
Ah okay, I'm unsure on how it would deal with loosing a drive during a parity sync. As I'm aware most single parity hardware raid (say raid 5) would just die.
And I don't have a system to test that with myself.
-
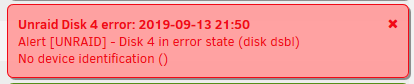
27 minutes ago, Ancan said:
Nothing yet. Except a "*" on the disk temperature and up to 32 errors now. Still green otherwise. By now I ideally should have had a mail in my inbox and be on my way to the store for a replacement. Hmm...

Edit: I *love* how you can just paste images from the clipboard into the forum here (Ok, I somehow get double attachments when I do it but it 10 x beats saving the image and uploading it)
If you setup the notification system under Settings > Notification Settings
Then it should of notified you of the errors on the drive... I would need to test myself though
Edit: After pulling my disk 5, I got a notification within 5 seconds (Discord) This is what my main screen looks like too:

After this I stopped the array, unassigned the device, started the array. Then stopped the array and reassigned the device and started the array.
Data is now rebuilding fine.









[Support] binhex - DelugeVPN
in Docker Containers
Posted
Thanks for the info, I have done this and changed the required settings in ltConfig.
I can confirm that the speeds are now much better in the region of 45 - 50MB/s which is the max speed of my connection.