

semtex41
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by semtex41
-
I am still running 6.12.4, and prior to today my uptime was over 2 months, but unfortunately i have been working with the unraid server webpage open and forgot about checking logs. The system locked up within 5 hours and i had to hard reboot. Are people still seeing this issue on 6.12.6? *** NOTE: My uptime was only that stable because I change the server webpage tab to unraid.net when I am not actively using the web console.
-
6.12.4 - Gets unresponsive (Have to Cut power & hard reboot)
semtex41 commented on casperse's report in Stable Releases
Does an auto logout plugin exist? Not sure if the server will crash with just the login screen though. -
The bug report for this issue is in this thread: 6.12.4 - Gets unresponsive (Have to Cut power & hard reboot) - Stable Releases - Unraid Luckily it has been reopened. Hopefully it will get some visibility.
-
6.12.4 - Gets unresponsive (Have to Cut power & hard reboot)
semtex41 commented on casperse's report in Stable Releases
This is the same issue that others and I are having, in this thread: I have been counting the errors with this one-liner: grep -o 'Increase nchan_max_reserved_memory' /var/log/syslog | wc -l My server will crash if I leave a tab open for 18hrs on accident. Please reopen this issue. Diags upon request, but I will have to recreate as I have been nuking the logs and staying logged out. -
After another week, I have determined a few things: Closing all tabs prevents the errors from building up/cascading. The browser type doesnt seem to matter. Crashes/logs growing happens with Edge, Chrome, and Firefox. My appdata backup (which runs on Monday mornings) has been one of the triggers for the nginx errors in the logs. When the tab is open, the log fills up with the errors while the scheduled job is running. I do not blame the plugin, because when the tab (all tabs) are closed, the errors are not generated. Closing the tab today prevented a hard crash like last week, which required a hard shutdown. This is a webserver based interface. If the primary mechanism for accessing the OS causes the OS to consistently crash, then it is a bug.
-
This is still happening about once every 12 hours, but it alternates between the nginx logs being full and just the syslog being full. Just blindly nuking them at this point. I am using Edge and noticed it is getting faster since the last update. No evidence for that though, just an observation. Still willing to help get this resolved.
-
@martial try stopping and then starting the service, instead of restarting. That kept me from needing to reboot previously.
-
Continued from the last crash/reboot: root@tower:/var/log# ls -lah syslog* -rw-r--r-- 1 root root 1.9K Oct 5 22:12 syslog -rw-r--r-- 1 root root 12M Oct 5 00:00 syslog.1 -rw-r--r-- 1 root root 59M Oct 4 03:00 syslog.2 0 /var/log/pwfail 0 /var/log/swtpm 484K /var/log/samba 0 /var/log/plugins 12K /var/log/pkgtools 11M /var/log/nginx 0 /var/log/nfsd 0 /var/log/libvirt 82M /var/log root@tower:/var/log# grep -o 'Increase nchan_max_reserved_memory' /var/log/syslog.2 | wc -l 81995 root@tower:/var/log# awk -v phrase="Increase nchan_max_reserved_memory" '{count += gsub(phrase, "")} END {print count}' /var/log/syslog.2 81995 root@tower:/var/log# grep -o '"/usr/local/emhttp/us" failed (2: No such file or directory)' /var/log/syslog.2 | wc -l 2 Performed: > /var/log/syslog &\ > /var/log/syslog.1 &\ > /var/log/syslog.2 /etc/rc.d/rc.syslog stop /etc/rc.d/rc.syslog start and that zeroed out the logs.
-
In todays drama, the log hit 100%. What I should have done was cleared them. Instead I restarted. That was a mistake. After about 5 mins waiting for the reboot, I realize my tower was booting into UEFI and not recognizing the USB. After repairing the USB in windows, it did boot successfully but failed to start the docker service. In fact, the docker config seemed to have been factory reset, creating a blank docker.img. Luckily, I am now keeping the docker image in an appdata folder, and after stopping the service and changing it to the right path, got the containers going again. BTRFS scrub did not find any errors. I would like to note this flashdrive is only 2 weeks old and I am certain the fs errors on it are related to the full logs. This really needs to be fixed and I appreciate any help I can get fixing it in the short term.
-
I dont see that plugin installed on my box. Good info though.
-
So is this a bug or user error? Struggle bus here, trying to figure out if its something on my side.
-
Unlimited output of these two types of logs until the web crashes
semtex41 commented on dicry's report in Stable Releases
This is close enough to my problem found here, that I do think it's a bug. I am having to clear log files at least one a day to keep nginx from not responding. See: -
I thought it might have been related to nginx proxy manager, but I disabled the host prior to clearing the logs previously. But there are new error entries related to nginx in unraid itself, and memory. Here are the recent logs. Sep 23 13:33:22 tower nginx: 2023/09/23 13:33:22 [crit] 22809#22809: ngx_slab_alloc() failed: no memory Sep 23 13:33:22 tower nginx: 2023/09/23 13:33:22 [error] 22809#22809: shpool alloc failed Sep 23 13:33:22 tower nginx: 2023/09/23 13:33:22 [error] 22809#22809: nchan: Out of shared memory while allocating message of size 18014. Increase nchan_max_reserved_memory. Sep 23 13:33:22 tower nginx: 2023/09/23 13:33:22 [error] 22809#22809: *5776466 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/devices?buffer_length=1 HTTP/1.1", host: "localhost" Sep 23 13:33:22 tower nginx: 2023/09/23 13:33:22 [error] 22809#22809: MEMSTORE:01: can't create shared message for channel /devices Sep 23 13:41:17 tower emhttpd: spinning down /dev/sdi Sep 23 14:12:13 tower kernel: veth249d8c8: renamed from eth0 Sep 23 14:12:14 tower kernel: eth0: renamed from veth87b2b92 Sep 23 14:18:06 tower nginx: 2023/09/23 14:18:06 [error] 22809#22809: *5805991 "/usr/local/emhttp/api/index.html" is not found (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /api/ HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:06 tower nginx: 2023/09/23 14:18:06 [error] 22809#22809: *5805998 open() "/usr/local/emhttp/status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /status?full&json HTTP/1.1", host: "localhost" Sep 23 14:18:06 tower nginx: 2023/09/23 14:18:06 [error] 22809#22809: *5805999 open() "/usr/local/emhttp/status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /status?full&json HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:06 tower nginx: 2023/09/23 14:18:06 [error] 22809#22809: *5806000 open() "/usr/local/emhttp/server-status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /server-status?auto HTTP/1.1", host: "localhost" Sep 23 14:18:06 tower nginx: 2023/09/23 14:18:06 [error] 22809#22809: *5806001 open() "/usr/local/emhttp/server-status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /server-status?auto HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:08 tower nginx: 2023/09/23 14:18:08 [error] 22809#22809: *5806027 open() "/usr/local/emhttp/server-status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /server-status?auto HTTP/1.1", host: "localhost" Sep 23 14:18:08 tower nginx: 2023/09/23 14:18:08 [error] 22809#22809: *5806028 open() "/usr/local/emhttp/server-status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /server-status?auto HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806035 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 127.0.0.1, server: , request: "GET /admin/api.php?auth=&version=true HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806037 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 127.0.0.1, server: , request: "GET /admin/api.php?auth=&version=true HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock:", host: "localhost" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806039 open() "/usr/local/emhttp/status/format/json" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /status/format/json HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806045 open() "/usr/local/emhttp/basic_status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /basic_status HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806046 open() "/usr/local/emhttp/stub_status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /stub_status HTTP/1.1", host: "localhost" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806047 open() "/usr/local/emhttp/stub_status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /stub_status HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806048 open() "/usr/local/emhttp/nginx_status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /nginx_status HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806049 open() "/usr/local/emhttp/status" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /status HTTP/1.1", host: "127.0.0.1" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806050 open() "/usr/local/emhttp/us" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /us HTTP/1.1", host: "localhost" Sep 23 14:18:09 tower nginx: 2023/09/23 14:18:09 [error] 22809#22809: *5806051 open() "/usr/local/emhttp/us" failed (2: No such file or directory), client: 127.0.0.1, server: , request: "GET /us HTTP/1.1", host: "127.0.0.1"
-
0 /var/log/pwfail 0 /var/log/swtpm 880K /var/log/samba 0 /var/log/plugins 12K /var/log/pkgtools 60M /var/log/nginx 0 /var/log/nfsd 0 /var/log/libvirt 67M /var/log At the same time as the results above: du -sh /var/log/* 4.0K /var/log/apcupsd.events 0 /var/log/btmp 0 /var/log/cron 0 /var/log/debug 4.0K /var/log/dhcplog 72K /var/log/dmesg 52K /var/log/docker.log 0 /var/log/faillog 4.0K /var/log/lastlog 0 /var/log/libvirt 0 /var/log/maillog 0 /var/log/mcelog 0 /var/log/messages 0 /var/log/nfsd 60M /var/log/nginx 0 /var/log/packages 12K /var/log/pkgtools 0 /var/log/plugins 0 /var/log/pwfail 0 /var/log/removed_packages 0 /var/log/removed_scripts 0 /var/log/removed_uninstall_scripts 880K /var/log/samba 0 /var/log/scripts 0 /var/log/secure 0 /var/log/setup 0 /var/log/spooler 0 /var/log/swtpm 5.8M /var/log/syslog 0 /var/log/vfio-pci 0 /var/log/vfio-pci-errors 16K /var/log/wtmp And: Thanks for your help!
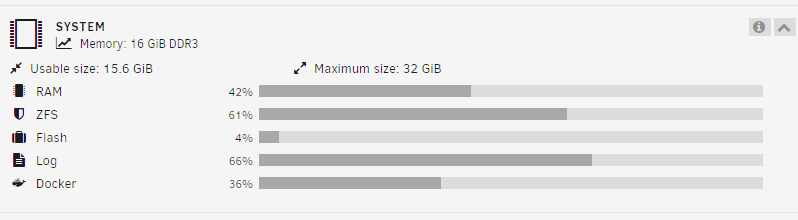
-
Seeing this problem now. Similar to the last post, I was also fine running 6.12.3 but updated to 6.12.4 a few weeks ago. Ran this: > /var/log/syslog /etc/rc.d/rc.syslog stop /etc/rc.d/rc.syslog start It cleared the log file and the web console log is working. But I noticed that the Log utilization bar on the Dashboard isnt reflecting the new empty syslog. uptime: 06:54:26 up 6 days, 18:53, 1 user, load average: 2.18, 2.11, 2.17
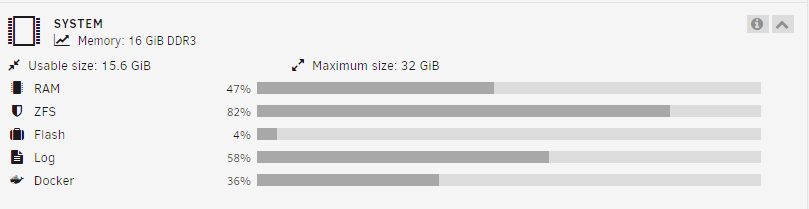
-
Pool selectable for secondary storage (pool-to-pool mover)
semtex41 replied to CanOfSocks's topic in Feature Requests
I would also find this interesting. Like putting a nvme nfs raid0 as primary and a raidz2 pool as secondary. Finally, adding the md array as tertiary. I dont know what the multiple zfs pool overhead would be, but I like this idea. -
Just updated from 6.11.3 to 6.12.4 and so far so good! Previously plagued by crashing problems on 6.11.3, that always happened minutes after the appdata backup service would run successfully. When I heard news that it was related to macvlan, I changed over to ipvlan and it solved my crashing problem with an uptime of over 7 months after that. Now looking forward to learning ZFS. Keep up the good work unraid team!
-
Upgrade from 6.10.3 to 6.11.3 was successful without issues. I dont use VMs but have several macvlan dockers, fwiw.
-
Saw the issue again today, on 6.9.2. I am using the -i br0 switch. -i br0 Edit: Looks like this will be fixed in the future.
-
What is the recommended workflow for upgrading the unraid template? I have been using one that I made long before the pi-hole official image and want to switch over to the supported one.
-
***GUIDE*** Plex Hardware Acceleration using Intel Quick Sync
semtex41 replied to lotetreemedia's topic in Docker Containers
Ok this is not the exact link I was wanting to find from ChuckPa, but this is a recent comment from him: ^ https://forums.plex.tv/t/where-to-obtain-pms-build-4479/715338/6 Ah, I think I found the same info on the dockerhub readme: ^ https://hub.docker.com/r/plexinc/pms-docker#Tags As I understand that, the containers that launch with from the plexpass, public (and I speculate the :Beta tag also) will fetch/download the most current server binary in their channel and will update. Basically those tags are self patching compared to the static tagged images, to included the ":latest" tag, which are locked into a specific stable version. -
***GUIDE*** Plex Hardware Acceleration using Intel Quick Sync
semtex41 replied to lotetreemedia's topic in Docker Containers
Its worth noting that with plexinc/pms-docker:plexpass, I read on the plex forums that this image builds itself when the container is launched. So it will track with latest upon first launch of the container. If I find the source for this, I will edit this post. -
unRAID 6 NerdPack - CLI tools (iftop, iotop, screen, kbd, etc.)
semtex41 replied to jonp's topic in Plugin Support
I will also add I was able to get docker-compose installed with the following: pip3 install docker-compose But I have no idea how unraid stores these nor if it will persist between reboots. Also, I still cant seem to uninstall python-2.7.17-x86_64-2.txz from within the Nerd Pack. -
unRAID 6 NerdPack - CLI tools (iftop, iotop, screen, kbd, etc.)
semtex41 replied to jonp's topic in Plugin Support
On mine, its not letting me uninstall python2, and pip install docker-compose errors out on the same spot: subprocess32 I dont have anything using python myself. Any suggestions how to uninstall python2? (besides just turning the toggle to OFF and hitting apply) -
unRAID 6 NerdPack - CLI tools (iftop, iotop, screen, kbd, etc.)
semtex41 replied to jonp's topic in Plugin Support
You need setuptools Thank you. And done. Sensing the pattern, I searched for json after I saw the following: Traceback (most recent call last): File "/usr/bin/docker-compose", line 6, in <module> from pkg_resources import load_entry_point File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 3252, in <module> def _initialize_master_working_set(): File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 3235, in _call_aside f(*args, **kwargs) File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 3264, in _initialize_master_working_set working_set = WorkingSet._build_master() File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 583, in _build_master ws.require(__requires__) File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 900, in require needed = self.resolve(parse_requirements(requirements)) File "/usr/lib64/python3.8/site-packages/pkg_resources/__init__.py", line 786, in resolve raise DistributionNotFound(req, requirers) pkg_resources.DistributionNotFound: The 'jsonschema<4,>=2.5.1' distribution was not found and is required by docker-compose No dice. Have any advice how I can determine these dependencies and root them out? Thank you again.




