

SiNtEnEl
-
Posts
85 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by SiNtEnEl
-
I'm glad LSIO holds back releases, as for Unifi i check forums before i even press the update button. The amount of annoyance i had with Unifi is quite long, and the work i had restoring it in the past is worth the wait. If u want to go bleeding edge, u should build your own image. So LSIO thank you for your effort, and keeping us safe! As for memory usage, my unifi unstable instance is around 500mb stable past days.
-
@dj_sim U planning to publish and support it in Unraid? I have it on my list as well.
-
@Poprin Are u not confusing used with cached? U could run the following in the console: "top -o %MEM" (with out brackets) it will sort your memory usage. With the "e" u can cycle in unit size. (kb mb gb) The values under RES corresponded with the %MEM, and an accurate representation of how much actual physical memory a process is consuming. PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19019 nobody 20 0 2272.0m 908.7m 16.8m S 1.7 5.7 136:40.05 mono 11112 nobody 20 0 2335.4m 436.6m 41.1m S 0.3 2.8 1:19.72 Plex Media Serv 12899 nobody 20 0 2412.6m 372.0m 6.7m S 0.3 2.3 8:15.03 python2 4878 nobody 20 0 3751.8m 316.2m 19.9m S 0.0 2.0 0:25.01 java My case Radarr and Plex are top consumers. But most of it is cache.
-
Plugin/Docker/app to automatically unpack Archives (Rar mainly)
SiNtEnEl replied to radfx's topic in General Support
Filebot has allot of scripts, including AMC that u could customize to your needs. Some examples u can find here: https://www.filebot.net/forums/viewtopic.php?f=4&t=215. I don't know your exact setup, so its hard to give further advice on that. Unrarall is quite simple and offers less options then Filebot. Basically u have to execute a command on the host "docker exec -t unrarall --clean=all" (Clean all removes the rar files and leaves the clean extract). This can be on a cronjob in unraid or any other thing that triggers the command. Best this is using a event that signals that the sync between your host and seedbox is done. Or u can make a filewatcher script, but if the sync is not complete your extract will fail. -
The IcyDocks are default in a pull configuration, the suck out fresh air from the front of the computer case in to the tray's over the disks in too the case. Swapping it around will lead u blowing warmed air from inside the case over the disks, i wouldn't suggest doing this as its likely to increase the heating issue. The rear fan and the CPU fans should be facing outwards towards the back of the computer. Top fan could add more positive pressure to get the warm air out.
-
Plugin/Docker/app to automatically unpack Archives (Rar mainly)
SiNtEnEl replied to radfx's topic in General Support
In your usecase u could go either Filebot (available in CA) or unrarall https://github.com/arfoll/unrarall (not available in CA). -
[REMOVED] Megatools - Mega.nz sync tool - Docker
SiNtEnEl replied to dee31797's topic in Docker Engine
Rather have no external services passwords in clear on the server. But this is personal. The file gives enough convenience, but using variables makes it easier for novice users to get around with the docker template especially when u add it to Community Applications (CA) later on. On the other hand using secrets is not to novice friendly either, so variables is a good start and maybe adding it to CA as well. -
[REMOVED] Megatools - Mega.nz sync tool - Docker
SiNtEnEl replied to dee31797's topic in Docker Engine
Interesting, i will gave this docker a spin. Works as intended. Are u planning support for docker secrets and variables to store the credentials? Thanks for creating and sharing. -
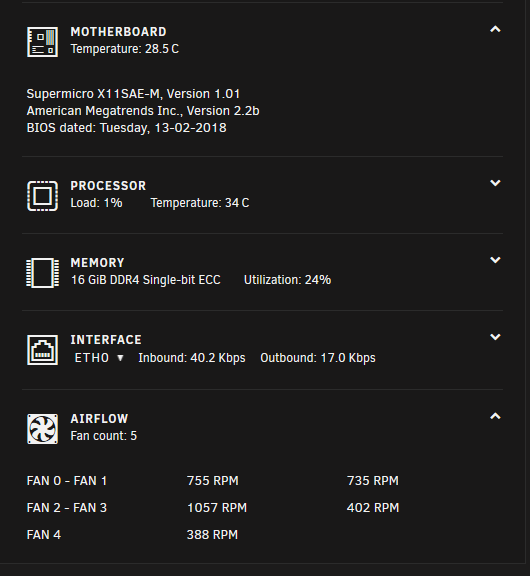
The RC of 6.7.0 gives out of the box sensor information that could be useful analyzing your issue. Our you could install Dynamix System Temperature plugin, on 6.6 and see what other temps are. If the motherboard temperatures are OK, then i'm pretty much sure its the airflow in the docks. The older had better airflow in my opinion, i have used some newer ones and didn't like there cooling. My disks are running at 32c and mainboard about 28,5c with a 24c air temp running full quiet. Only time the fans run faster on my array is when i run my monthly parity check for 16 hours. So if your mainboard is around 30c, at least if u have a sensor that measures it. Im pretty sure your airflow inside the case is alight, and thus your docks are hot inside. If your mainboard is in the 40c range, then hot air is not getting out of your case. Thus adding extra heat to the docks, etc.
-
My experience with icy dock that there is where restricted airflow with 5 drives in them. If i understand correctly u had the same 2 drive bays in a different enclosure running at 30c? About your current setup: Either u go Positive or Negative Pressure with your casing and fans. I would go positive pressure, since with the big mesh on your side panel negative would be hard. So basically your front fans on your drive bays need to push in more air volume then your rear fan does. The PSU if it draws from the bottom of the case will not draw in air into the case, and will exit out rear. But my guess is that the front bay fans don't get enough air in the case. Are the on max RPM?
-
In low memory situations, Linux tries to kill processes that are consuming lots of memory. There are some further conditions that are checked, before the process that will be killed is selected. (i won't sum them). This happened 6 times on a docker instance, in your case the one running Sonarr. Line 3560: Jan 10 19:59:13 ffs2 kernel: Killed process 17778 (mono) total-vm:3574628kB, anon-rss:2057924kB, file-rss:0kB, shmem-rss:4kB Line 3778: Jan 14 21:09:07 ffs2 kernel: Killed process 15431 (mono) total-vm:3158360kB, anon-rss:2034704kB, file-rss:0kB, shmem-rss:4kB Line 4029: Jan 17 21:53:00 ffs2 kernel: Killed process 6146 (mono) total-vm:3016800kB, anon-rss:2049280kB, file-rss:0kB, shmem-rss:4kB Line 4260: Jan 21 19:31:30 ffs2 kernel: Killed process 25086 (mono) total-vm:3102052kB, anon-rss:2041428kB, file-rss:0kB, shmem-rss:4kB Line 4479: Jan 24 17:25:16 ffs2 kernel: Killed process 13894 (mono) total-vm:3638768kB, anon-rss:2048868kB, file-rss:0kB, shmem-rss:4kB Line 4619: Jan 27 00:18:22 ffs2 kernel: Killed process 24288 (mono) total-vm:3546380kB, anon-rss:2043724kB, file-rss:0kB, shmem-rss:4kB There are plenty of complaints on the internet about mono + sonarr combination eating up memory. U could try restarting the docker instance on regular basis before the system runs out of memory or mono hogging to much memory. Trying a different sonarr docker template, could be a option too. Could be a bug as well in sonarr / mono it self that happens on your configuration or content.
-
Feature Idea: Grouping Docker containers into groups/apps.
SiNtEnEl replied to benyanke's topic in Feature Requests
Docker Compose would be a nice feature, but if Unraid is not going that way i would vote for "Grouping functionality" in the docker web interface. -
I found this a good read: https://access.redhat.com/security/vulnerabilities/L1TF-perf
-
Jul 8 18:45:22 DeusVult kernel: Call Trace: Jul 8 18:45:22 DeusVult kernel: local_pci_probe+0x3c/0x7a Jul 8 18:45:22 DeusVult kernel: pci_device_probe+0x11b/0x154 Jul 8 18:45:22 DeusVult kernel: driver_probe_device+0x142/0x2a6 Jul 8 18:45:22 DeusVult kernel: __driver_attach+0x68/0x88 Jul 8 18:45:22 DeusVult kernel: ? driver_probe_device+0x2a6/0x2a6 Jul 8 18:45:22 DeusVult kernel: bus_for_each_dev+0x63/0x7a Jul 8 18:45:22 DeusVult kernel: bus_add_driver+0xe1/0x1c6 Jul 8 18:45:22 DeusVult kernel: driver_register+0x7d/0xaf Jul 8 18:45:22 DeusVult kernel: ? 0xffffffffa02dc000 Jul 8 18:45:22 DeusVult kernel: do_one_initcall+0x89/0x11e Jul 8 18:45:22 DeusVult kernel: ? kmem_cache_alloc+0x9f/0xe8 Jul 8 18:45:22 DeusVult kernel: do_init_module+0x51/0x1be Jul 8 18:45:22 DeusVult kernel: load_module+0x1854/0x1e3f Jul 8 18:45:22 DeusVult kernel: ? SyS_init_module+0xba/0xe0 Jul 8 18:45:22 DeusVult kernel: SyS_init_module+0xba/0xe0 Jul 8 18:45:22 DeusVult kernel: do_syscall_64+0x6d/0xfe Jul 8 18:45:22 DeusVult kernel: entry_SYSCALL_64_after_hwframe+0x3d/0xa2 Jul 8 18:45:22 DeusVult kernel: RIP: 0033:0x14bb588958aa Jul 8 18:45:22 DeusVult kernel: RSP: 002b:00007ffeacc548c8 EFLAGS: 00000246 ORIG_RAX: 00000000000000af Jul 8 18:45:22 DeusVult kernel: RAX: ffffffffffffffda RBX: 0000000000625e50 RCX: 000014bb588958aa Jul 8 18:45:22 DeusVult kernel: RDX: 0000000000629be0 RSI: 00000000002202e8 RDI: 0000000000f1fa80 Jul 8 18:45:22 DeusVult kernel: RBP: 0000000000629be0 R08: ffffffffffffffe0 R09: 00007ffeacc52a68 Jul 8 18:45:22 DeusVult kernel: R10: 0000000000623010 R11: 0000000000000246 R12: 0000000000f1fa80 Jul 8 18:45:22 DeusVult kernel: R13: 0000000000625f80 R14: 0000000000040000 R15: 0000000000000000 Jul 8 18:45:22 DeusVult kernel: Code: 00 e8 6a c7 e7 ff 8b 83 28 06 00 00 83 e8 16 83 e0 fd 0f 84 16 02 00 00 48 c7 c6 aa cf 4c a0 48 c7 c7 a7 c9 4c a0 e8 d4 32 c6 e0 <0f> 0b e9 fc 01 00 00 66 3d 00 a3 75 4e 48 c7 c2 49 d0 4c a0 be Jul 8 18:45:22 DeusVult kernel: ---[ end trace 3f2b0267604ec704 ]--- I'm getting also call traces on the i915, noticed since 6.5.3 series. Did a post here: https://lime-technology.com/forums/topic/72427-call-trace-on-653-series/ Looks like the i915 driver / module is funky after 6.5.2 for more users other then me on unraid. Since hardware transcoding is still working properly, i muted the error.
-
Hi all, Well if been struggling with this issue, since the introduction of the 6.5.3 series of Unraid. Since im not sure if its a user, kernel or firmware issue due to Unraid i'm posting this in general support. I have been reading similar issues on various linux distro's on the DC state mismatch, but not quite sure how to combine this with Unraid. Anyone got idea's? If full diagnostics log is needed let me know, i will upload it. Thanks! Jun 24 08:23:08 UnNASty kernel: ------------[ cut here ]------------ Jun 24 08:23:08 UnNASty kernel: WARNING: CPU: 0 PID: 3 at drivers/gpu/drm/i915/intel_runtime_pm.c:614 skl_enable_dc6+0x76/0xf2 [i915] Jun 24 08:23:08 UnNASty kernel: Modules linked in: i915(+) iosf_mbi drm_kms_helper drm intel_gtt agpgart syscopyarea sysfillrect sysimgblt fb_sys_fops nct6775 hwmon_vid bonding igb i2c_algo_bit e1000e ptp pps_core x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel pcbc aesni_intel aes_x86_64 crypto_simd glue_helper cryptd intel_cstate intel_uncore intel_rapl_perf i2c_i801 i2c_core ahci libahci wmi video backlight fan acpi_pad thermal button [last unloaded: pps_core] Jun 24 08:23:08 UnNASty kernel: CPU: 0 PID: 3 Comm: kworker/0:0 Not tainted 4.14.49-unRAID #1 Jun 24 08:23:08 UnNASty kernel: Hardware name: Supermicro Super Server/X11SAE-M, BIOS 2.2 12/13/2017 Jun 24 08:23:08 UnNASty kernel: Workqueue: events i915_hpd_poll_init_work [i915] Jun 24 08:23:08 UnNASty kernel: task: ffff880460189a00 task.stack: ffffc900018f8000 Jun 24 08:23:08 UnNASty kernel: RIP: 0010:skl_enable_dc6+0x76/0xf2 [i915] Jun 24 08:23:08 UnNASty kernel: RSP: 0018:ffffc900018fbd38 EFLAGS: 00010292 Jun 24 08:23:08 UnNASty kernel: RAX: 0000000000000025 RBX: ffff88045e428000 RCX: 0000000000000000 Jun 24 08:23:08 UnNASty kernel: RDX: ffff88047241d001 RSI: ffff8804724164b8 RDI: ffff8804724164b8 Jun 24 08:23:08 UnNASty kernel: RBP: ffff88045e428000 R08: 0000000000000003 R09: ffffffff81fefe00 Jun 24 08:23:08 UnNASty kernel: R10: ffff880461896be8 R11: 00000000000104b4 R12: 0000000020000000 Jun 24 08:23:08 UnNASty kernel: R13: ffff88045e42ca98 R14: ffffffffa043195f R15: 0000000000000001 Jun 24 08:23:08 UnNASty kernel: FS: 0000000000000000(0000) GS:ffff880472400000(0000) knlGS:0000000000000000 Jun 24 08:23:08 UnNASty kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Jun 24 08:23:08 UnNASty kernel: CR2: 000000000076c8a8 CR3: 0000000001c0a004 CR4: 00000000003606f0 Jun 24 08:23:08 UnNASty kernel: Call Trace: Jun 24 08:23:08 UnNASty kernel: intel_display_power_put+0xa9/0xc7 [i915] Jun 24 08:23:08 UnNASty kernel: intel_dp_detect+0x428/0x43c [i915] Jun 24 08:23:08 UnNASty kernel: drm_helper_probe_detect_ctx+0x54/0xb8 [drm_kms_helper] Jun 24 08:23:08 UnNASty kernel: ? __switch_to_asm+0x24/0x60 Jun 24 08:23:08 UnNASty kernel: drm_helper_hpd_irq_event+0x6c/0xeb [drm_kms_helper] Jun 24 08:23:08 UnNASty kernel: i915_hpd_poll_init_work+0xb3/0xc0 [i915] Jun 24 08:23:08 UnNASty kernel: process_one_work+0x155/0x237 Jun 24 08:23:08 UnNASty kernel: ? rescuer_thread+0x275/0x275 Jun 24 08:23:08 UnNASty kernel: worker_thread+0x1d5/0x2ad Jun 24 08:23:08 UnNASty kernel: kthread+0x111/0x119 Jun 24 08:23:08 UnNASty kernel: ? kthread_create_on_node+0x3a/0x3a Jun 24 08:23:08 UnNASty kernel: ret_from_fork+0x35/0x40 Jun 24 08:23:08 UnNASty kernel: Code: 55 04 00 48 89 df e8 b6 b9 46 e1 a8 02 74 1e 80 3d 29 dd 0d 00 00 75 15 48 c7 c7 6e 15 43 a0 c6 05 19 dd 0d 00 01 e8 0a 7e ce e0 <0f> 0b 48 89 df e8 53 e5 ff ff 48 c7 c2 95 15 43 a0 be 04 00 00 Jun 24 08:23:08 UnNASty kernel: ---[ end trace 238ac015519e427b ]--- Jun 24 08:23:08 UnNASty kernel: [drm:gen9_set_dc_state [i915]] *ERROR* DC state mismatch (0x0 -> 0x2) Jun 24 08:23:08 UnNASty kernel: [drm] Initialized i915 1.6.0 20170818 for 0000:00:02.0 on minor 0 Jun 24 08:23:08 UnNASty kernel: ACPI: Video Device [GFX0] (multi-head: yes rom: no post: no) Jun 24 08:23:08 UnNASty kernel: acpi device:0f: registered as cooling_device10 Jun 24 08:23:08 UnNASty kernel: input: Video Bus as /devices/LNXSYSTM:00/LNXSYBUS:00/PNP0A08:00/LNXVIDEO:00/input/input5 Jun 24 08:23:08 UnNASty kernel: [drm] Cannot find any crtc or sizes Jun 24 08:23:08 UnNASty root: Starting emhttpd Jun 24 08:23:08 UnNASty emhttpd: unRAID System Management Utility version 6.5.3 Jun 24 08:23:08 UnNASty emhttpd: Copyright (C) 2005-2018, Lime Technology, Inc.
-
How much RAM do you have installed in your unRAID server?
SiNtEnEl replied to harmser's topic in Unraid Polls
Kingston VR ECC UDIMM DDR4-2400 16GB Micron, had to upgrade my memory due to memory starvation related crashes. -
Got the same behavior on my plex instance, the use 32400 or what ever port u use in your configuration. https://support.plex.tv/articles/200484543-enabling-remote-access-for-a-server/
-
Drive performance testing (version 2.6.5) for UNRAID 5 thru 6.4
SiNtEnEl replied to jbartlett's topic in User Customizations
Just tested the docker approach by running dd from a container and i'm getting same disk performance as the alpha version of diskspeed. Was concerned it may influence the benchmarks. -
(Solved) Unraid OS not booting correctly
SiNtEnEl replied to chrishorton7's topic in General Support
Glad you found the issue, well at least u confirmed the memory is OK. -
(Solved) Unraid OS not booting correctly
SiNtEnEl replied to chrishorton7's topic in General Support
Memtest cycle can run a while, if its running a memtest it won't show up in the network. If memtest is OK, boot the OS with out the new disks see if its OK. Then add the disks one for one. (offline and then see if it boots) -
(Solved) Unraid OS not booting correctly
SiNtEnEl replied to chrishorton7's topic in General Support
I would do a Memtest, and check if the memory is working correctly. If that doesnt work, disconnect the new drives and try a Memtest. Proceed from that if it's ok. -
Supermicro boards have a long history of not having a correct scaling lm-sensors and need to be offset. I had this in the past on other linux distribution, but this probably would be the case with your machine. You can correct this by setting the correct offset values in the sensors configuration. Guide for this u can find here, not for Unraid but should do the same with sensors 3.4 on Unraid: https://wiki.archlinux.org/index.php/lm_sensors#Example_1._Adjusting_temperature_offsets (If it does not correct it directly after placing the file, it could be that u need to run sensors -s.) Some configs u can find here: https://github.com/groeck/lm-sensors/tree/master/configs/SuperMicro Mainly for the older boards, u could try supermicro support as well to get a config solution. Some boards don't report to well with out superdoctor being installed on the system. But i would try the offset route first, and see if that corrects the issue your having.
-
Glad we found the root cause, i used the cli mostly as well. For me is was a good docker documentation recap. My wifi vlan has internet access and can access google trough the vpn tunnel.
-
Currently cheapest "dumpster" drives are €0,026 per gigabyte, still would hit me for 850 euro in disks. (need to by a extra disk due to overlap) Cheapest NAS capable disks that i would consider are €0,029 per gigabyte, so i rather save a bit more and do a larger NAS solution. Older disks will be kept for offline backup, what i'm doing at the moment, but that is always less then the size of my current storage.
-
https://docs.docker.com/engine/userguide/networking/configure-dns/ In the absence of the --dns=IP_ADDRESS..., --dns-search=DOMAIN..., or --dns-opt=OPTION... options, Docker uses the /etc/resolv.conf of the host machine (where the docker daemon runs). While doing so the daemon filters out all localhost IP address nameserver entries from the host’s original file. The information in this section covers the embedded DNS server operation for containers in user-defined networks. DNS lookup for containers connected to user-defined networks works differently compared to the containers connected to default bridge network. if there are no more nameserver entries left in the container’s /etc/resolv.conf file, the daemon adds public Google DNS nameservers (8.8.8.8 and 8.8.4.4) to the container’s DNS configuration. If IPv6 is enabled on the daemon, the public IPv6 Google DNS nameservers are also added (2001:4860:4860::8888 and 2001:4860:4860::8844). The embedded DNS server provides service discovery (i.e. it allows you to resolve hostnames of other containers on the same network), and acts as a forwarder for external DNS servers you configured. So if there is nothing left, its forwared to google, but that should be reachable from your VLAN i presume. My host config has a internal and external backup address in it, that is reachable from my VLAN. Wonder if this could be the case, in your setup @mifronte

