

bastl
-
Posts
1267 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bastl
-
-
47 minutes ago, DataCollector said:
Wenn Du das nicht akzeptieren wolltest, gibt sie zurück.
Ich bin ja nicht der Käufer, und selbst hab ich bisher immer einen Bogen um solche Angebote gemacht. Ausnahmen würde ich ja noch machen, wenn ich direkt beim Angebot sehe die Platte kommt aus nem Rechenzentrum und hat x Betriebsstunden, x TBW etc. Wenn die SMART Werte wie angegeben zurückgesetzt wurden und ich quasi 0 Möglichkeiten hab deren Gebrauch nachzuvollziehen sind es mir die paar Euro Ersparnis auch nicht wert.
Kannst du in deinem Fall nachvollziehen bei welchen Modellen die hohen Werte vorhanden sind? Scheint ja so zu sein, dass es bei deinen 18TB Modellen auch nicht einheitlich ist. Kommt das nur ab einem gewissen Modelljahr vor, oder bei einer besonderen Firmware Version?
-
12 hours ago, Quarkmax said:
Ist sie denn Schrott? Das ist doch eine Seagate, da läuft das mit den SMART Werten anders.
Ok. Das ist mir auch gerade neu. Die letzten Seagate Platten die ich hatte, zeigten das noch nicht so, allerdings auch schon paar Jahre her. 2-3TB Modelle waren das. Ich habe dennoch Bauchschmerzen bei "recertified" Platten. In einem Kommentar steht folgendes:
QuoteGanz weit unten in der Artikelbeschreibung bei eBay steht dann, Zitat:
Es handelt sich um eine Seagate recertified Festplatte ohne Betriebsstunden.
Das sind gebrauchte Reparatur-Rückläufer mit genullten Betriebsstunden und zurückgesetzten S.M.A.R.T.-Werten. Man hat also keine Information über den tatsächlichen Verschleiß- und Gesundheitsstatus der Festplatte.Stell dir vor du kaufst nen gebrauchten PKW, bei dem einfach mal alle alten Unterlagen gelöscht und der Kilometerstand auf 0 gesetzt wurde für 20-30€ günstiger als Neuware.
-
 1
1
-
-
Wenn mal bei "Raw_Read_Error_Rate" 3-4 oder so steht und nicht hoch geht, würde ich mir garkeine Sorgen machen, aber 37673480 bei gerademal 256h Laufzeit ist nicht ok. Je nachdem wie man die Platte testet, wird es vielleicht garnicht direkt auffallen. Formatieren und Daten drauf kopieren mag vielleicht noch funktionieren, beim Lesen der Daten wird man es dann aber sicherlich merken. "recertified" wird denke mal nen Rückläufer sein. Jetzt weißt du auch warum. Wird keinen Sinn machen nen extended Selftest laufen zu lassen, wenn die Platte intern in ihrem eigenen Log schon Lesefehler verzeichnet hat. Probier mal ohne die Platte ob der Server stabil läuft
-
Eine deiner Festplatten (ST18000NM000J-2TV103) hat in den Smart Werten sehr hohe Werte bei den Fehlerraten. Mit der Platte stimmt definitiv was nicht
Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 076 064 044 - 37673480 3 Spin_Up_Time PO---- 090 090 000 - 0 4 Start_Stop_Count -O--CK 100 100 020 - 17 5 Reallocated_Sector_Ct PO--CK 100 100 010 - 0 7 Seek_Error_Rate POSR-- 079 060 045 - 80588272 9 Power_On_Hours -O--CK 100 100 000 - 256 10 Spin_Retry_Count PO--C- 100 100 097 - 0 12 Power_Cycle_Count -O--CK 100 100 020 - 16 18 Unknown_Attribute PO-R-- 100 100 050 - 0 187 Reported_Uncorrect -O--CK 100 100 000 - 0 188 Command_Timeout -O--CK 100 100 000 - 0 190 Airflow_Temperature_Cel -O---K 075 063 000 - 25 (Min/Max 14/28) 192 Power-Off_Retract_Count -O--CK 100 100 000 - 15 193 Load_Cycle_Count -O--CK 100 100 000 - 27 194 Temperature_Celsius -O---K 025 040 000 - 25 (0 14 0 0 0) 197 Current_Pending_Sector -O--C- 100 100 000 - 0 198 Offline_Uncorrectable ----C- 100 100 000 - 0 199 UDMA_CRC_Error_Count -OSRCK 200 200 000 - 0 200 Multi_Zone_Error_Rate PO---K 100 100 001 - 0 240 Head_Flying_Hours ------ 100 100 000 - 255 (232 238 0) 241 Total_LBAs_Written ------ 100 253 000 - 51453398249 242 Total_LBAs_Read ------ 100 253 000 - 219259610467 -
@KluthR First of all, thanks for the plugin. I'am using it for quite some time now and never had any issues with it.
Yesterday I switched from the old 2.5 version to the new one during the latest Unraid update and tested a bit. So far so good, compression works fine, copy flash backup to different location and also the grouping feature and the autoupdate dockers are working.
Now to my issue I have. I have a mariadb and nextcloud container grouped together, stop-backup-start works, but the available update for the mariadb container isn't applied when grouped together. Is this a known bug or not yet implemented for the grouping feature?
The logs show no errors and no hints that the plugin tries to update the container like it did on the netdata container which is in no group.
-- [21.02.2024 22:20:37][ℹ️][nextcloud] Method: Stop all container before continuing. [21.02.2024 22:20:37][ℹ️][nextcloud][Nextcloud] Stopping Nextcloud... done! (took 1 seconds) [21.02.2024 22:20:38][ℹ️][nextcloud][MariaDB-Official] Stopping MariaDB-Official... done! (took 2 seconds) [21.02.2024 22:20:40][ℹ️][Main] Starting backup for containers [21.02.2024 22:20:40][ℹ️][Nextcloud] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:20:40][ℹ️][Nextcloud] Calculated volumes to back up: /mnt/user/appdata/nextcloud/apps, /mnt/user/appdata/nextcloud/config, /mnt/user/appdata/nextcloud/nextcloud [21.02.2024 22:20:40][ℹ️][Nextcloud] Backing up Nextcloud... [21.02.2024 22:21:37][ℹ️][Nextcloud] Backup created without issues [21.02.2024 22:21:37][ℹ️][Nextcloud] Verifying backup... [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Calculated volumes to back up: /mnt/user/appdata/mariadb-official/data, /mnt/user/appdata/mariadb-official/config [21.02.2024 22:22:20][ℹ️][MariaDB-Official] Backing up MariaDB-Official... [21.02.2024 22:22:30][ℹ️][MariaDB-Official] Backup created without issues [21.02.2024 22:22:30][ℹ️][MariaDB-Official] Verifying backup... [21.02.2024 22:22:33][ℹ️][Main] Set containers to previous state [21.02.2024 22:22:33][ℹ️][MariaDB-Official] Starting MariaDB-Official... (try #1) done! [21.02.2024 22:22:35][ℹ️][Nextcloud] Starting Nextcloud... (try #1) done! [21.02.2024 22:22:38][ℹ️][netdata] Stopping netdata... done! (took 2 seconds) [21.02.2024 22:22:40][ℹ️][netdata] Should NOT backup external volumes, sanitizing them... [21.02.2024 22:22:40][ℹ️][netdata] Calculated volumes to back up: /mnt/user/appdata/netdata/lib, /mnt/user/appdata/netdata/cache, /mnt/user/appdata/netdata/config [21.02.2024 22:22:40][ℹ️][netdata] Backing up netdata... [21.02.2024 22:22:59][ℹ️][netdata] Backup created without issues [21.02.2024 22:22:59][ℹ️][netdata] Verifying backup... [21.02.2024 22:23:02][ℹ️][netdata] Installing planned update for netdata... [21.02.2024 22:23:28][ℹ️][netdata] Starting netdata... (try #1) done! -- -
@GatorMB Do you have a idle session to Unraids WebUI opened somewhere on your network? I have an issue the server freezing randomly if I have a websession opened from a Windows box with Firefox. Randomly every 1-2 days with root logged in to Unraid, the server will freeze without any errors catched in the logs. If I log off or shutdown the Windows pc the server won't crash.
-
If you're on 6.12.5 or 6.12.6 try to downgrade to Unraid 6.12.4. A couple of users reported similiar issues like yours with latest Unraid builds and PCI passthrough
-
1 hour ago, JorgeB said:
usually there's are nchan or similar errors logged
unfortunately not for me. I already checked all the logs for nchan errors. Is there a chance to increase the log level from unraid to get more output?
-
@count-zero I have similiar issues, random crashes and nothing in the logs. For me all started with the 6.12.x builds. What I noticed during the last weeks as long as I'am not logged in Unraids webui it doesn't crash. I now close any VNC VM windows and logout from the webui if I don't need to use it. Firefox on a Windows machine I use tu administrate the server.
@JorgeB did you heared about that "phenomenon"? I have tested basically everything. Disks are ok, no errors. Memtest no errors. Switched to different power outlets, configured all sorts of stuff in the BIOS, with or without virtualisation, different power saving modes, disabled all sorts of devices like wifi or BT cards. Also disabling Docker or VMs or even running Unraid in Save Mode for a couple days didn't help. It always crashes between 4hours uptime up to 3-4 days with nothing logged.
Now the interesting part. During all that crashes I had a Firefox window on another Windows box with different Unraid pages opened. Sometimes the Docker page, next time the Dashboard or the Main tab. As soon as I log out and close the Firefox Tabs surprise surprise crashes are gone.
I saw a lot of threads opened with random freezes and crashes with the 6.12.x Unraid builds. Most people had issues with MacVLAN, switching to IPVLAN didn't help for me. Maybe this is something you can tell the people to test to pin down the problem.
-
10 hours ago, Mainfrezzer said:
https://forums.unraid.net/topic/78993-solved-how-to-create-a-virtual-nic-for-internalisolated-use-only/
Weiter unten in dem Thema wird erläutert wie man Docker den Virtuellen Nic verwenden lässt. Ist ordentliches Gefummel.
Viel Glück mit PFSense, OPNsense hatte mir weniger Kopfweh bereitet.
(Persönlicher Ratschlag basierend auf meiner Erfahrung. Es ist wesentlich einfacher, so lange man nur Webservices braucht und zufälligerweise eine Fritzbox hat, nen USB to Ethernet Adapter zu besorgen. Die Dockercontainer auf den USB NIC zu legen und dann bei der Fritzbox ins Gastnetz zu werfen. Cloudflare ist da tatsächlich auch ein ganz nützliches Tool, da man ja keine Ports freigeben kann, allerdings ja wunderbar raus kommt") )
)
Danke für den Link zu meinem eigenen Thread mit nem ähnlichen Thema 😂
Bin ich irgendwie nicht darauf gekommen, dass dort jemand etwas Ähnliches gefragt haben könnte und habs auch scheinbar verpasst.
docker network create -o parent=virbr9 --driver macvlan --subnet 10.30.10.0/24 --gateway 10.30.10.1 labnetHiermit hab ich mir ein "labnet" erstellt, und erfolgreich getestet. Die Docker sind nun in dem Privaten Netz mit ner Test-VM. Mit "Preserve user defined networks" in den Docker Settings bleibt das Netz auch nach nem Reboot erhalten und ich hab beim Erstellen eines Dockers die Option für das Netz zur Auswahl und brauche nur eine feste IP vergeben. Genau wie ich das wollte.
Gefummel war das garnicht und ne Pfsense VM hatte ich ja bereits für Tests und zum bisl üben was Routing und die ganze Funktionalität angeht. Auch ganz praktisch, wenn man Backups von seiner physikalisch existenten Pfsense Kiste hin und wieder testen will.
Danke nochmal 👍
-
 1
1
-
-
Servus zusammen.
Ich steh gerade auf dem Schlauch. Folgendes habe ich vor. Ich würde gern ein paar Docker Container zum Test in einem separatem Netz betreiben, was keinen direkten Zugang zum Internet hat. Bei Bedarf würde ich eine vorgeschaltete VM wie Pfsense für den Zugang zum Internet nutzen. Mit dem Befehl "--network:netz" kann man einem Container gezielt ein Docker-Netz zuweisen, oder hat in der Gui die Auswahl für den Netzwerktyp. Mir fehlt da aber leider die Auswahl für eine eigens von mir bereits erstellte virbr die ich in meinen VM's zum testen verwende.
Folgendes funktioniert in meiner Testumgebung schon problemlos. Pfsense VM mit 2 Nics. Einmal als Bridge nach draußen und virbr9 für die interne Kommunikation der Vms. Somit können VMs intern untereinander problemlos kommunizieren und ich hab über Pfsense die Kontrolle was rein und raus geht. Wie bringe ich nun einen Docker Container dazu virbr9 zu benutzen? Jemand eine Idee? Oder muß ich die Docker in einer extra VM betreiben?
Dank im Vorraus
-
1 hour ago, Johnny4233 said:
Updated, rebooted. My problem still exist.
Try to disable "netbios"
-
@dlandon Looks like latest update 2023.06.21 fixed my issue (Unraid still on 6.12). 2 tested restarts and the remote NFS shares are auto mounting now like they did before with 👍
-
9 hours ago, dlandon said:
I have found an issue with specifying the FQDN that might be related to what you are seeing. I need to do some more testing before it is released, but it may solve your issue.
If I can help you test something, let me know. 👍
-
22 minutes ago, dlandon said:
I think the issue is that your pihole is supplying the IP address when it is running. I assume it is a Docker Container. And it is the wrong IP address?
piHole is ALWAYS running and no, it's not a Docker. It's a installation directly on Debian on a Raspberry Pi. I have not a single DNS issue on my network and I use piHole for years now with Unraid. Nothing has changed on my setting except of the latest Unraid 6.12 Update.
Does UD always used arp request to check for availability?
Why does it work with Docker service turned of on Unraid and not when its on???
It's confusing.
And another thing what confuses me. If I ping or dig DISKSTATION directly from Unraid I get a response with the correct IP which btw. is a static IP outside of the DHCP area and never changed as long as the NAS exists. Also the Unraid box has a static IP which never changed before. As soon as I ping the NAS from Unraid the greyed out mount buttons become available in the web ui. Somehow UD recognizes the availability almost instant if a ping or dig command from the console is send. How does UD get that info if not with it's own arp request as you mentioned?
-
14 minutes ago, dlandon said:
Is 10.0.0.252 correct for your DNS server?
Yes, it's a piHole on a Pi4.
14 minutes ago, dlandon said:You have a 20 second delay before UD auto mounts the devices.
I never had set that value before, only for troubleshooting today. Doesn't change anything.
15 minutes ago, dlandon said:Remove one of your shares and use the IP address
I changed one of the shares to IP (tried different ones) and after a reboot all shares auto mounted just fine. It's also working if I use the FQDN "DISKSTATION.MYDOMAIN.LOCAL" for the NAS

Now the interesting part. I switched back to the original setting done with the gui to search for servers and shares and only use the DNS name DISKSTATION again like in my first post and after a restart it is working now?!
BUT the difference between working and not working is, I had the Docker service start set to "no" during my last tests to prevent Jellyfin start scanning the media library all the time. As soon as I enable Docker and restart the server, automount stops working with DNS names.
It only works with IP or with FQDN with Docker enabled!!!

I checked under Unraids "Management Access" settings and my TLD is set correctly. Looks like the build in check for reachability of the remote shares in UD somehow ignores the set TLD

-
42 minutes ago, dlandon said:
Post diagnostics.
Diagnostics taken after a fresh restart, 10-15min uptime.
-
1 hour ago, dlandon said:
Is the Synology NAS on the same LAN
Same LAN only a unmanged switch between the 2 devices.
10.0.0.4 - Unraid
10.0.0.5 - NAS
-
Latest Unraid Update 6.12 broke something with UD for me. I have 3 NFS shares mounted with UD hosted by a Synology NAS which auto mounted on earlier Unraid versions without any issues. Now after a reboot the shares won't mount and the mount button is greyed out.

The logs show the remote server is offline which isn't true. I checked a couple of times the NAS is online, reacts to ping and the shares are also accessible from other devices.
Jun 19 15:50:41 mini unassigned.devices: Mounting Remote Share 'DISKSTATION:/volume1/UNRAID'... Jun 19 15:50:41 mini unassigned.devices: Remote Server 'DISKSTATION' is offline and share 'DISKSTATION:/volume1/UNRAID' cannot be mounted. Jun 19 15:50:41 mini unassigned.devices: Mounting Remote Share 'DISKSTATION:/volume1/music'... Jun 19 15:50:41 mini unassigned.devices: Remote Server 'DISKSTATION' is offline and share 'DISKSTATION:/volume1/music' cannot be mounted. Jun 19 15:50:41 mini unassigned.devices: Mounting Remote Share 'DISKSTATION:/volume1/video'... Jun 19 15:50:41 mini unassigned.devices: Remote Server 'DISKSTATION' is offline and share 'DISKSTATION:/volume1/video' cannot be mounted.If I wait and do nothing, nothing changes. Refreshing the main page, nothing. Reboot again, nothing. As soon as I open a web console to the Unraid server and try to ping the IP of the Synology the buttons to mount the shares become available and I can mount the shares by clicking it. Automount don't work
What did I miss? Is this a known issue?
-
First of all, thanks for this container.
I have a question @sdub
In your second post of this thread you showed your config as an example which I used to test it on my system. I have an issue with it. As long as I keep the prefix line in the retention block
retention: keep_hourly: 2 keep_daily: 7 keep_weekly: 4 keep_monthly: 12 keep_yearly: 10 prefix: 'backup-'I get the following error during sheduled backups:
/mnt/borg-repository: Error running actions for repository Command 'borg prune --keep-hourly 2 --keep-daily 7 --keep-weekly 4 --keep-monthly 12 --keep-yearly 10 --glob-archives backup-* --glob-archives backup-* --list /mnt/borg-repository' returned non-zero exit status 2. Error during prune/create/check. /etc/borgmatic.d/config.yaml: An error occurred borg prune: error: argument -a/--glob-archives: There can be only one. Command 'borg prune --keep-hourly 2 --keep-daily 7 --keep-weekly 4 --keep-monthly 12 --keep-yearly 10 --glob-archives backup-* --glob-archives backup-* --list /mnt/borg-repository' returned non-zero exit status 2.The argument "--glob-archives backup-*" is added 2 times somehow.
Why do you add it at the retention section in your yaml file? Is it really needed or is this line save to remove?
-
@Rockikone Kannst du mal zum Test ein paar der Dateien die du sichern möchtest in ein anderes Verzeichnis kopieren, die Berechtigungen auf 777 setzen und dann diese versuchen zu sichern?
-
22 hours ago, mgutt said:
Ich kann mir das nur mit irgendwelchen Berechtigungsfehlern erklären.
Hab jetzt mal folgendes getestet. Aus dem zu sichernden Nextcloud Ordner hab ich ne Video Datei in den test Ordner kopiert. Desweiteren werden nur ein paar Docker Config Ordner gesichert um die tests zu beschleunigen. Hab dann einige Backups nacheinander erstellt ohne was zu ändern. Wie gehabt, bis auf die Datei "virtio.iso" werden scheinbar alle Dateien erneut übertragen. Dauert auch jedesmal identisch lang.
Hab nun die Berechtigungen der Videodatei auf 777 gesetzt und siehe da, Backup is ruckzuck durch und die Datei zählt bei Links hoch.
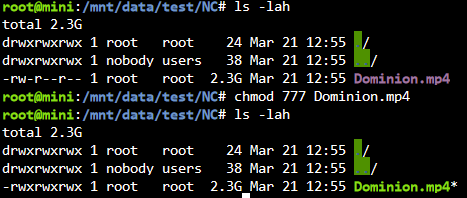
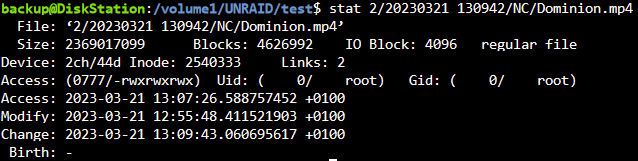
Und siehe da, "du" gibt diesmal auch Werte aus, die Sinn machen. Die 1,8MB sind sicherlich die paar Appdata Files, die erneut gesichert werden.

So und nune?
😂
-
21 hours ago, mgutt said:
Steht in den Logs von dem Skript evtl etwas von Fehlern?
Ich habe das log File "/tmp/user.scripts/tmpScripts/rsyncIncrementalBackup/log.txt" mal grob nach "error", "auth", "authentication", "privilege" durchsucht. Hatte die Datei schonmal gelöscht, aktuell 72MB und fast 900k Zeilen, da wird es schwer den Überblick zu behalten. Treffer sind dann aber nur bei Dateien oder Ordner die so benannt sind. In den Zusammenfassungen nach jedem Pfad beinhalten auch keine Fehlermeldungen.
21 hours ago, mgutt said:Gehört die perms.txt auf der Quelle auch dem User root?
Ja.
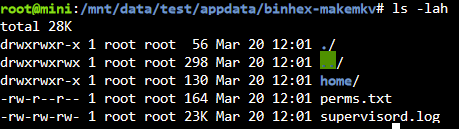
Und hier nochmal zum Vergleich die Berechtigungen im eigentlichen appdata Verzeichnis, was ich als root nach "test" kopiert hatte.

-
1 hour ago, mgutt said:
Die Zielverzeichnisse müssen pro Quellverzeichnis unterschiedlich sein.
Das war doch schon der Fall, ganz zu Beginn. Alles in einen Ordner zu sichern hatte ich nur bei den letzten Tests getan, sry my bad falls das vielleicht verwirrend war, ändert aber nichts an der Sachlage. Gleiches Bild zeigt sich wie folgt:
Hier jetzt nochmal verdeutlicht, was ich gerade teste. Folgende 4 Ordner sollen gesichert werden. Eindeutig 4 verschiedene Ziele.
"/boot" "/mnt/remotes/DISKSTATION_UNRAID/test/1" "/mnt/data/test" "/mnt/remotes/DISKSTATION_UNRAID/test/2/" "/mnt/data/backup/ca_backup/flash" "/mnt/remotes/DISKSTATION_UNRAID/test/3/" "/mnt/data/appdata" "/mnt/remotes/DISKSTATION_UNRAID/test/4"- Es existieren nun von jedem Ordner 3 Sicherungen.
- Es wurden keinerlei Änderungen am Script, Berechtigungen oder Pfaden vorgenommen
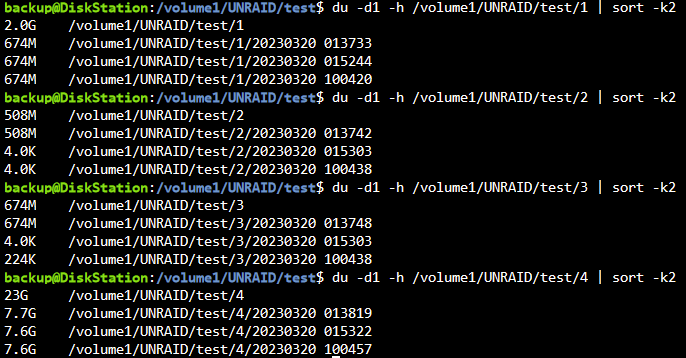
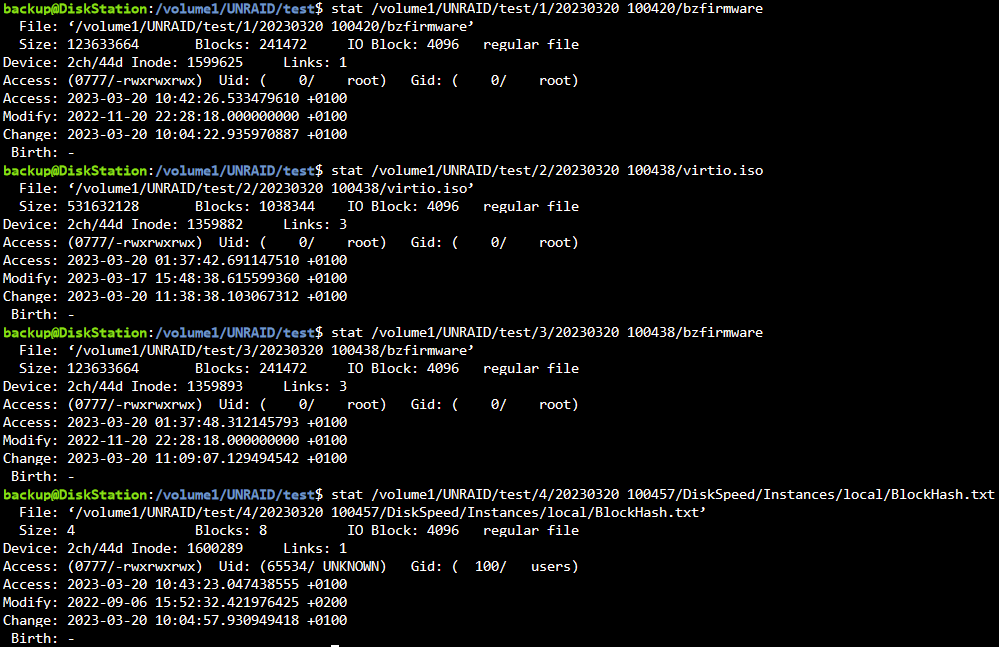
In den ordnern 2 und 3 scheint es Hardlinks zu geben, bei 1 und 4 scheinbar nicht.
Ich hab nun testweise von Hand den "/mnt/data/appdata" Ordner in den zu sichernden Ordner "/mnt/data/test" kopiert und dann 2 weitere Sicherungen von nur diesem Ordner erstellt (die anderen 3 Pfade auskommentiert im Script). Die Datei ".../2/.../virtio.iso" zählt jeweils 1 pro Sicherung hoch bei Links, die Dateien in ".../2/.../appdata/ordner/datei" eben nicht. Beide Inhalte sind zwischen den beiden Sicherungen unverändert.
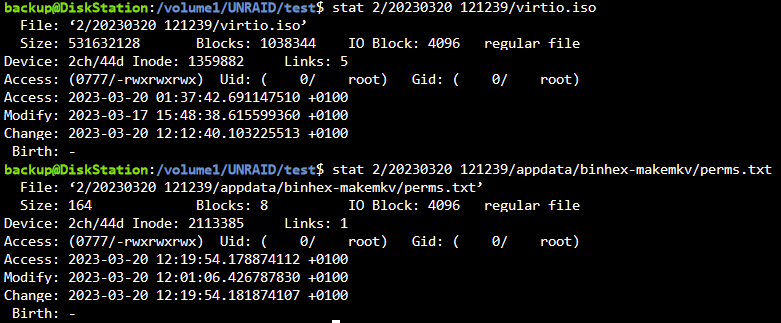

Sollte nicht spätestens bei der 2ten zusätzlichen Sicherung von "/mnt/data/test" wo nun zusätzlich "appdata" hineinkopiert wurde, bei erfolgreich erstellten Hardlinks der Counter hochzählen bei Dateien innerhalb des appdata Ordners?
Woran kann es liegen, dass von der einen Datei ein Hardlink erstellt wird und ein paar Ebenen tiefer in der gleichen Ordnerstruktur auf einmal nicht mehr?
Ich versteh die Welt nicht mehr 😑















Malwieder VM & GPU
in Deutsch
Posted
Servus. Hier wird dein Problem liegen. Beim Boot der VM wird normalerweise die Karte initialisiert allerdings nur, wenn ein Monitor angeschlossen ist. Meine 1050ti funktioniert auch nur in einer Win VM, wenn ein Monitor dran klemmt. Es gibt auch HDMI Dongles, die der Karte einen Monitor vorgaukeln, wäre eine Option, wenn du keinen Monitor anklemmen willst.
Das ist eins der Symptome wenn kein Display dran hängt. Die Karte wird nur als Basic Display Adapter erkannt versehen mit einer Warnung und Treiber lassen sich auch nicht installieren.