

mgranger
-
Posts
168 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by mgranger
-
-
Ok the rebuild just finished. Here is the diags. I think it is ok but just want to check. I am guessing i will get read errors shortly but I guess I will just run the server until that happens. My new cables are supposed to come on Friday and I will be replacing the existing ones then. Will just have to troubleshoot from there.
-
Well maybe this answers something. I was doing a rebuild on Disk 5 (new disk but same slot) and I got more errors on the parity and Disk 4 and Disk 3. This makes me think it has something more to do with a cable, backplane, or HBA. I have 2 power supplies so I hope it is not the but I guess it is possible. I am going to let it rebuild Disk 5 then probably shut it down until I can get new cables unless there is no risk of corrupting the data? Before I tried rebuilding the drive I tried to check all the connections to make sure they were tightly connected.
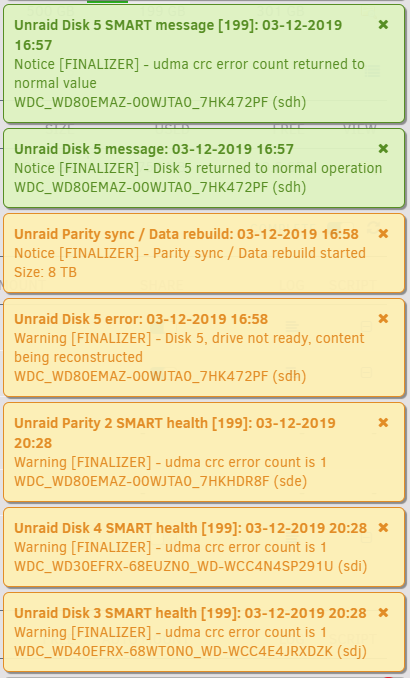
-
2 minutes ago, johnnie.black said:
There are communication issues with multiple disks:
Dec 3 11:52:37 Finalizer kernel: sd 9:0:1:0: attempting task abort! scmd(00000000375afb15) Dec 3 11:52:37 Finalizer kernel: sd 9:0:1:0: [sdd] tag#6528 CDB: opcode=0x85 85 06 20 00 d8 00 00 00 00 00 4f 00 c2 00 b0 00 Dec 3 11:52:37 Finalizer kernel: scsi target9:0:1: handle(0x000b), sas_address(0x5003048001d979ad), phy(13) Dec 3 11:52:37 Finalizer kernel: scsi target9:0:1: enclosure logical id(0x5003048001d979bf), slot(1) Dec 3 11:52:37 Finalizer kernel: sd 9:0:1:0: device_block, handle(0x000b) Dec 3 11:52:38 Finalizer kernel: sd 9:0:1:0: task abort: SUCCESS scmd(00000000375afb15) Dec 3 11:52:39 Finalizer kernel: sd 9:0:1:0: device_unblock and setting to running, handle(0x000b) Dec 3 11:52:46 Finalizer kernel: sd 9:0:7:0: attempting task abort! scmd(00000000ff7cd007) Dec 3 11:52:46 Finalizer kernel: sd 9:0:7:0: [sdj] tag#6568 CDB: opcode=0x85 85 06 20 00 d8 00 00 00 00 00 4f 00 c2 00 b0 00 Dec 3 11:52:46 Finalizer kernel: scsi target9:0:7: handle(0x0011), sas_address(0x5003048001d979b3), phy(19) Dec 3 11:52:46 Finalizer kernel: scsi target9:0:7: enclosure logical id(0x5003048001d979bf), slot(7) Dec 3 11:52:46 Finalizer kernel: sd 9:0:7:0: device_block, handle(0x0011) Dec 3 11:52:48 Finalizer kernel: sd 9:0:7:0: task abort: SUCCESS scmd(00000000ff7cd007) Dec 3 11:52:48 Finalizer kernel: sd 9:0:7:0: device_unblock and setting to running, handle(0x0011) Dec 3 11:59:29 Finalizer kernel: mdcmd (50): spindown 5 Dec 3 12:00:08 Finalizer kernel: sd 9:0:13:0: attempting task abort! scmd(00000000454c3926) Dec 3 12:00:08 Finalizer kernel: sd 9:0:13:0: [sdo] tag#6783 CDB: opcode=0x85 85 06 20 00 d8 00 00 00 00 00 4f 00 c2 00 b0 00 Dec 3 12:00:08 Finalizer kernel: scsi target9:0:13: handle(0x000f), sas_address(0x5003048001d979b1), phy(17) Dec 3 12:00:08 Finalizer kernel: scsi target9:0:13: enclosure logical id(0x5003048001d979bf), slot(5) Dec 3 12:00:08 Finalizer kernel: sd 9:0:13:0: device_block, handle(0x000f) Dec 3 12:00:10 Finalizer kernel: sd 9:0:13:0: device_unblock and setting to running, handle(0x000f) Dec 3 12:00:11 Finalizer kernel: sd 9:0:13:0: [sdo] Synchronizing SCSI cache Dec 3 12:00:11 Finalizer kernel: sd 9:0:13:0: [sdo] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=0x00
So unlikely to be a bad slot, most likely it can be the cables, power issue, backplane expander or the HBA, unfortunately not easy to say which one is the culprit without swapping things around to rule them out.
Any advice on the best way to troubleshoot this? I don't really have any extra of anything to start troubleshooting with a new component. Wouldn't other disks get read errors if it was a cable or HBA issue?
-
Last night I moved all my hard drives over to a new server I built. I finally upgraded to a chassis that has 16 bays and connects to the backplane with 2 SAS cables. I bought the chassis off ebay used but the cables were new. I have been reading that most of these errors are fixed with new cables but this a brand new cable so I hope it is not that and it would seem like it would be more than just disk 5 with errors. I will post my diagnostics but some advice would be much appreciated. I have already rebuilt disk 5 using the same drive and same spot in the chassis. I am hoping it is not a bad spot in the chassis. I noticed the drive showed up in Unassigned Devices while being spun down in the array and then shortly after I got the read error.
-
3 minutes ago, johnnie.black said:
Those MCE errors early in the boot precess seem to happen with some hardware, and usually are nothing to worry about, bios update might help.
I am upgrading in a few days so I guess once that happens I won't worry about it. Just wanted to make sure I was safe until then. Thanks.
-
Well maybe i spoke too soon. I was getting errors where my sever could not be accessed when I woke up in them morning so I have been doing some searching online and noticed that this could be due to having 2 cache drives (both of mine are the samsung evo which could also be an issue) so I tried removing one from the settings but when I did this I know got another machine check event error. I am attaching my diagnostics
-
i have also been having my server locking up in the morning lately. i have recently put a second SSD in my cache in the BTRFS format. here is on of the diagnostics i was able to grab before i shut the computer down.
-
i am now getting this error. is there something i need to fix?
2019-11-26 17:38:32.630108 INFO AppDaemon Version 3.0.5 starting 2019-11-26 17:38:32.630249 INFO Configuration read from: /conf/appdaemon.yaml 2019-11-26 17:38:32.631356 INFO AppDaemon: Starting Apps 2019-11-26 17:38:32.633425 INFO AppDaemon: Loading Plugin HASS using class HassPlugin from module hassplugin 2019-11-26 17:38:32.711857 INFO AppDaemon: HASS: HASS Plugin Initializing 2019-11-26 17:38:32.712072 INFO AppDaemon: HASS: HASS Plugin initialization complete 2019-11-26 17:38:32.712225 INFO Starting Dashboards 2019-11-26 17:38:32.712337 WARNING ------------------------------------------------------------ 2019-11-26 17:38:32.712393 WARNING Unexpected error during run() 2019-11-26 17:38:32.712447 WARNING ------------------------------------------------------------ 2019-11-26 17:38:32.712884 WARNING Traceback (most recent call last): File "/usr/local/lib/python3.6/site-packages/appdaemon/admain.py", line 82, in run self.rundash = rundash.RunDash(self.AD, loop, self.logger, self.access, **hadashboard) File "/usr/local/lib/python3.6/site-packages/appdaemon/rundash.py", line 130, in __init__ dash_net = url.netloc.split(":") TypeError: a bytes-like object is required, not 'str' 2019-11-26 17:38:32.712939 WARNING ------------------------------------------------------------ 2019-11-26 17:38:32.713005 INFO AppDeamon Exited -
On 11/22/2019 at 2:48 AM, johnnie.black said:
Diags are after rebooting so we can't see the errors, but the disk looks fine, replace/swap cables and rebuild, if it happens again grab diags before rebooting.
Thanks @johnnie.black Everything seems to be back to normal now. I switched the bay the hard drive was in (different cable) and that seemed to fix it for now.
-
3 hours ago, cheesemarathon said:
It should take you to the diyhue UI. Did you set the IP variable to the same IP as your unraid machine? You need to set it to a different IP, the same as the one you should have set in the network settings as it must be on the bridge (br0) network. If the link to go to the web UI still doesn't work, then just browse to the IP you set.
I am now taken to the IP address I put in but nothing comes up. I get an error that the site can't be reached.
-
I am having some read errors with disk 6. when i try to move files over to it using unbalance the disk gets read errors and becomes disabled and so i am emulatimg off the parity drive. not sure what is going on here. thos is a brand new 8tb drive. i will post the diagnostics. also what do i have to do to get the drive back in the array? or is that too risky and should i just be avoiding this drive?
-
When I use the diyHue and try to access the webui it just takes me to the unraid page. Is there something that I am doing wrong?
-
i will restart after the parity is run so that it all gets cleared out.
-
25 minutes ago, johnnie.black said:
Docker image is corrupt and spamming the log, you need to delete and re-create.
I noticed that and deleted and recreated it late last night. Hopefully it is not still corrupt. It seems to be working right now.
-
i had a lot pf errors show up on the cache drive and then my disk 6 became disable yesterday due to read errors. so i went in and replaced the sata cables on both those drive hoping that will help. i am currently rebuilding drive 6 because i had to stop and remove the disk from the array and then add it back in. i am hoping this fixes some of my issues but i am a little nervous about it. i also balanced and scrubbed the cache pool. here are the diagnostics from this morning although maybe the parity needs to finish
-
4 hours ago, mgranger said:
For what it's worth I have been running Memtest86 for over an hour now and here is what I have got so far.
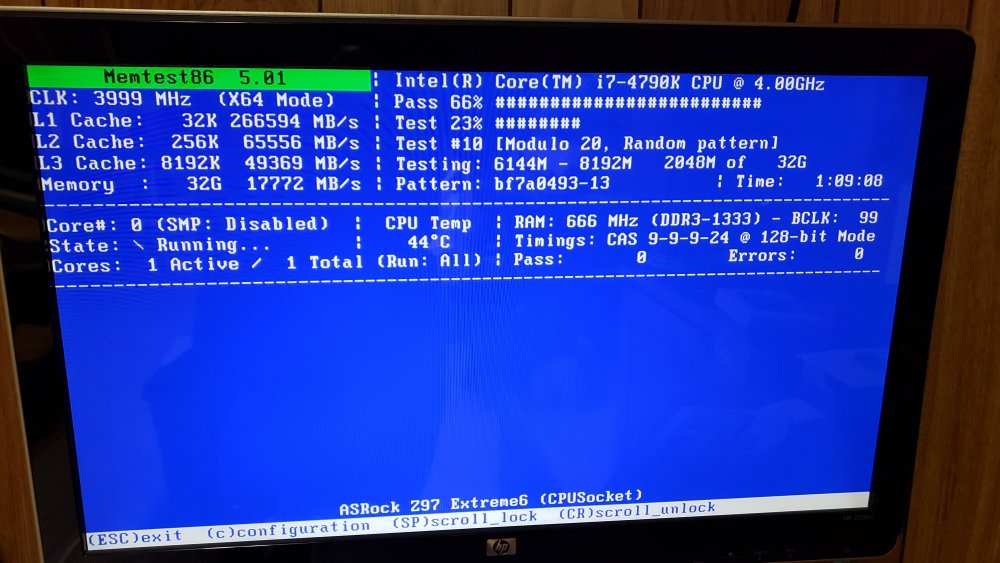
Ok so I did 1 run using memtest86 version 5.01 and got no errors. Then I stopped it and tried version 8.2 of memtest86. I am currently done with 2 runs of this version and have no errors. I will let it finish overnight and update in the morning. It has been taking about 1 hour 45 mins per run so I am a little over 5 hours of memtesting.
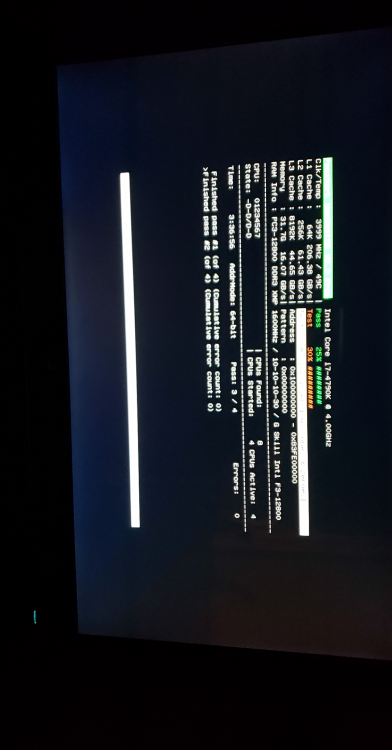
-
For what it's worth I have been running Memtest86 for over an hour now and here is what I have got so far.
-
17 minutes ago, johnnie.black said:
Yes, all data on the array is on xfs disks, xfs can't detect data corruption, data read on cache will be corrected by btrfs if corruption is detected, but new data written can also be corrupted, since the checksum saved by btrfs can be from corrupted data in RAM, you'd need ECC RAM to protect from corruption on write.
So I should shut it down. Is there a way to check if data is corrupted that has been written to the array already.
-
13 minutes ago, johnnie.black said:
These are checksum errors and usually the result of bad RAM.
So am i at risk of bad things happening if I still keep my server up and running at this time. (Corruption?) I would like to keep it up and running if possible but dont want to cause more damage if I can avoid it. When I do the Memtest will it show which stick is bad or do I have to only put one in and do process of elimination to determine which is bad (if this is the case) Is this a common thing to go bad. I have had this computer for a little over a year and a half and doesn't seem like they would wear out this quick.
-
14 minutes ago, John_M said:
It's a hardware fault that takes place as the CPU is starting up:
Nov 19 06:38:07 Finalizer kernel: smpboot: CPU0: Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz (family: 0x6, model: 0x3c, stepping: 0x3) Nov 19 06:38:07 Finalizer kernel: mce: [Hardware Error]: Machine check events logged Nov 19 06:38:07 Finalizer kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 3: fe00000000800400 Nov 19 06:38:07 Finalizer kernel: mce: [Hardware Error]: TSC 0 ADDR ffffffffa00ac3d3 MISC ffffffffa00ac3d3 Nov 19 06:38:07 Finalizer kernel: mce: [Hardware Error]: PROCESSOR 0:306c3 TIME 1574163469 SOCKET 0 APIC 0 microcode 27It might indicate a faulty CPU but I'd do a MemTest first (select it from the boot menu if legacy booting) to try to eliminate faulty RAM. If the RAM passes the test you could use the Nerd Tools plugin to install mcelog, which might reveal more information.
It looks like you also have cache pool corruption
Nov 19 06:39:49 Finalizer kernel: BTRFS warning (device sdn1): csum failed root 5 ino 144339143 off 1912832 csum 0x3d38702b expected csum 0xf33e576a mirror 1with one of the devices showing read errors:
Nov 19 06:39:49 Finalizer kernel: BTRFS info (device sdn1): read error corrected: ino 144339143 off 1916928 (dev /dev/sdp1 sector 3106512)Ok I will try that when I get home. That doesn't sound very good though. I can do an mcelog now but not sure where to go to get that. I have the mcelog installed already but not sure how to use it. What do I need to do for the cache pool corruption. I woke up this morning with my computer locked up and had to reboot it. I assume that is what caused all of this but not sure if I need to do a parity check to fix all this or something else?
-
8 minutes ago, Sic79 said:
I use a UD disk and it works great for event storage.Is there something that you had to change to get event storage on UD disk.
-
2 hours ago, dlandon said:
You are storing your data on a UD mounted disk. I suspect there is a problem with that and the events are being stored in the docker image. You should map your data to an array share. Why are you using a UD disk for events?
My thinking although it is probably wrong was that by using a UD the parity disks would not be spinning all the time. I understand that it is outside the array so I would lose all the data if the disk went bad but I was willing to live with that. But I see this is causing my docker image to become full.
-
I got an error in Fix Common Problems that I had a "Machine Check Events detected on your server" error. Not sure what that means but I will post my diagnostics in hopes that someone can help.
-
I am having a little bit of an issue with Zoneminder taking up a lot of space in my docker container and I am not sure why. Here is my docker container sizes below.
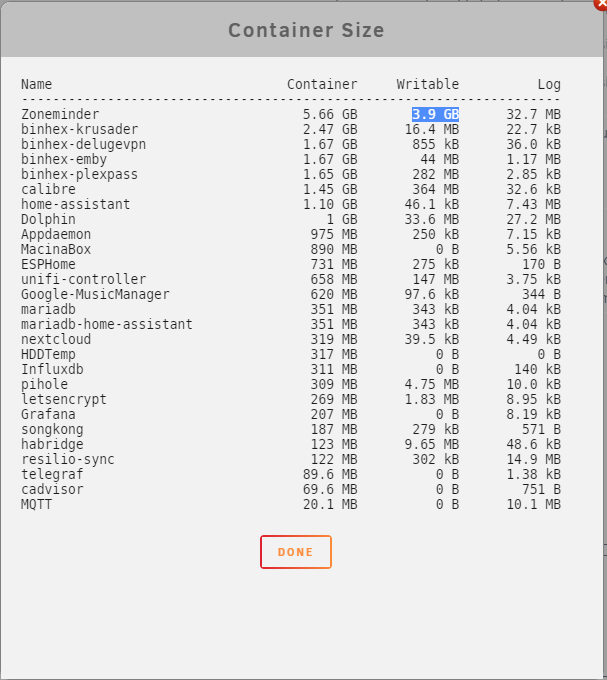
Also here is my config file...
bere is one of the errors i am getting inside of zoneminder which i believe is contributing to it
DiskSpace: Event does not exist at /var/cache/zoneminder/events/4/2019-11-17/231099:ZoneMinder::Event: Cause => Continuous DefaultVideo => 231099-video.mp4 EndTime => 2019-11-17 06:20:00 Frames => 501 Height => 1072 Id => 231099 Length => 247.29 MonitorId => 4 Name => Event- 231099 Scheme => Medium StartTime => 2019-11-17 06:15:53 StateId => 1 Videoed => 1 Width => 1920





Read Errors on New Server Build
in General Support
Posted
So the drive i took out of Drive 5 was a 4TB HGST drive. I have it in the unassigned devices now but it is refusing to mount. Is there a reason that this is happening? I figured I would be able to mount it using UD. I think I can reformat it now that the other disk was rebuilt but just trying to troubleshoot why this would happen.