

mgranger
-
Posts
168 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by mgranger
-
-
10 hours ago, mgranger said:
My processor load seems all over the place. Before I updated to 1.32 the load in zoneminder was 1 or 1.5 with my 4 cameras now after the update it seems closer to high 4 or middle 5's. This is with Mocord. If I set it to just record it does come down quite a bit (which makes sense) my first to cameras say they are at or below 2 fps within zoneminder. My 3rd camera says around 140 fps and the 4th is 1000 fps which is wrong. All are actually set at 2fps in the camera so not sure why they say they are so high.
So is there a way to go back to 1.30. I don't even care if i have to do a new database and just start from scratch. i am too frustrated with 1.32.
-
9 hours ago, BilboT34Baggins said:
Have you checked your processor load? When I was first setting up my two cameras I had to change the resolution and shrink the zones on the feeds I was using for motion detection to reduce the load on the processor. Also this last week I had a Vm take up too much processor power and it screwed up my zoneminder instance (apis wouldn't connect to zmninja).
My processor load seems all over the place. Before I updated to 1.32 the load in zoneminder was 1 or 1.5 with my 4 cameras now after the update it seems closer to high 4 or middle 5's. This is with Mocord. If I set it to just record it does come down quite a bit (which makes sense) my first to cameras say they are at or below 2 fps within zoneminder. My 3rd camera says around 140 fps and the 4th is 1000 fps which is wrong. All are actually set at 2fps in the camera so not sure why they say they are so high.
-
37 minutes ago, dlandon said:
Have you looked at any possible networking issues?
I have not looked at any ne gr working issues yet but if I pull up the video feed of the camera from the website I get a feed no problem and at the same time I look at the zoneminder image and I am having a problem so it makes me think the network is not the issue. It seems like it is something in zoneminder/unraid somewhere.
-
17 minutes ago, dlandon said:
Just thought of something. Several days ago, when Zoneminder was updating after a docker restart or an initial install, the Ubuntu php repository was passing php 7.3RC to the docker as the latest php version. Zoneminder is not compatible with php 7.2 or higher. This might be an issue for you. The thing to do is remove the docker and the re-install it. This would clear up any improper php 7.3RC update.
I have also been doing some changes to the docker creation file and there have been some mistakes along the way. It should be all cleared up now.
I just deleted it and reinstalled and it is already failing. I am using ffmpeg and tcp. i didn't see anything that looks different/wrong but obviously something is off.
-
2 hours ago, dlandon said:
No. Once the databases are updated, you can't go back.
What frame rate is set on your cameras?
They are set at 2 fps on the camera
-
Is there a way to go back to the old repository before 1.32? I was just going to see if going back helped fix the issue.
-
9 minutes ago, dlandon said:
Take the SHMEM% to 25. Zoneminder does not need that much shared memory. What version of Unraid are you on? 6.6 has a CPU pinning page so you can do it through the gui.
Ok i took the SHMEM% to 25 and pinned 2,6 and 3,7. (Yes i am on 6.6) My /dev/shm went up to 35% which makes sense since i lowered the SHMEM% but I am still seeing the same problem on my images.
-
8 minutes ago, dlandon said:
On the zoneminder console, you should try to keep /dev/shm under 70%. I would run /dev/shm around 40 to 50% (This is the /dev/shm on the zoneminder console, not the SHMEM% setting in the docker xml). You might be taking too much memory for zoneminder and not leaving enough for Unraid. Try to cut it down.
This looks like a processor loading problem. You may need to pin some CPUs to the zoneminder docker.
Ok i turned down the SHMEM% to 50% which was the default. My /dev/shm percent is hovering around 18% which seems good enough. I will try to pin some CPUs to zoneminder if I can figure it out.
-
On 10/16/2018 at 1:26 PM, dlandon said:
Nothing in the docker should be causing this issue and I don't know of any issues with the latest version.
You might want to confirm your camera resolution is set correctly.


This is what I am seeing. I restart the docker and it seems to fix it for awhile but then it eventually goes to this or sometimes worse. This happens to all 4 of my cameras or sometimes just a portion of them. I have already increased the SHMEM to 60% (I have 32 GB on the system)
-
So i updated to the new 1.32.2 and now I am having issues with the images being blurry. The update before the new layout i didn't have any problems with the blurry images. Is there something that changed that is causing this?
-
I figured it out. In my default ovpn file i had to list out the password.txt file next to authentication line. Seemed to fix it.
-
When i use the transmission_vpn i keep getting the following error
Using OpenVPN provider: NORDVPN Starting OpenVPN using config default.ovpn Setting OPENVPN credentials... adding route to local network 192.168.1.0/24 via 172.17.0.1 dev eth0 Wed Sep 26 04:42:04 2018 OpenVPN 2.4.6 x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Apr 24 2018 Wed Sep 26 04:42:04 2018 library versions: OpenSSL 1.0.2g 1 Mar 2016, LZO 2.08 Wed Sep 26 04:42:04 2018 neither stdin nor stderr are a tty device and you have neither a controlling tty nor systemd - can't ask for 'Enter Auth Username:'. If you used --daemon, you need to use --askpass to make passphrase-protected keys work, and you can not use --auth-nocache. Wed Sep 26 04:42:04 2018 Exiting due to fatal error -
3 hours ago, Gog said:
No I did not but that seemed to fix it. Thanks
-
I have been trying to get nextcloud set up with a reverse proxy with the spaceinvader tutorial however when I do this I keep getting a '500 internal server error' I take a look in the error.log and there is nothing there. What could I be doing wrong?
Here is my nextcloud.subdomain.conf:
# make sure that your dns has a cname set for nextcloud # edit your nextcloud container's /config/www/nextcloud/config/config.php file and change the server address info as described # at the end of the following article: https://blog.linuxserver.io/2017/05/10/installing-nextcloud-on-unraid-with-letsencrypt-reverse-proxy/ server { listen 443 ssl; server_name nextcloud.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_nextcloud nextcloud; proxy_max_temp_file_size 2048m; proxy_pass https://$upstream_nextcloud:443; } }Here is my config.php file: I changed my url from what it actually is to test.:
<?php $CONFIG = array ( 'memcache.local' => '\\OC\\Memcache\\APCu', 'datadirectory' => '/data', 'instanceid' => 'oc5vpjwh780k', 'passwordsalt' => 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', 'secret' => 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', 'trusted_domains' => array ( 0 => '192.168.1.100:448', 1 => 'nextcloud.test.com', ), 'overwrite.cli.url' => 'https://nextcloud.test.com', 'overwritehost' => 'nextcloud.test.com', 'overwriteprotocol' => 'https', 'dbtype' => 'mysql', 'version' => '13.0.5.2', 'dbname' => 'nextcloud', 'dbhost' => '192.168.1.100:3306', 'dbport' => '', 'dbtableprefix' => 'oc_', 'dbuser' => 'user', 'dbpassword' => 'XXXXXXXXXXXXXXX', 'installed' => true, );
-
On 3/23/2018 at 5:53 PM, hernandito said:
Hi Gang,
I have found that since upgrading to 6.5, I also cannot edit files anymore using Notepad++. When I try to save I get:
Please check if this file is open in another program.Files are not open anywhere.
Any file in appdata I have tried gives me this message when saving. Even php files (stored in the apache/www folder) which I created and edit on a regular bases in my Win Notepad++
I will be very cumbersome to edit all now via CLI or CA Config File Editor plugin.
How can I get editing back on in "appdata". Do I remove the CA Config File Editor? Is there a chmod I need to run on the appdata directory?
Many thanks,
H.
I have the same issue. Did you ever figure it out?
-
I am getting an issue where one or two of my cameras seem to be failing quite often. I don't think my system is overloaded but something seems to be happening. I only have 4 cameras that I am using and 32 GB of RAM which I am sharing 65%. My "South Cam Day" seems to be dropping intermittently as well as my "Driveway Cam Day"
Here is a portion of my log file. Not sure if anyone on here can help me out.
-
I went back to 0.61.1 and it seems to be working so it must be something changed within the docker which causes the error.
Edit: Well i am still getting the error in 0.61.1 however it seems to be less often and the automation seems to still work probably because it doesn't cut out as often and not at the time it was running the automation. Not sure why it seems better in 0.61.1 but it does seem a little better
-
I am having a lot of issues with this container. The honeywell component went seem to stay connected
2018-04-14 09:06:34 WARNING (MainThread) [homeassistant.helpers.condition] Value cannot be processed as a number: 2018-04-14 09:06:34 WARNING (MainThread) [homeassistant.helpers.condition] Value cannot be processed as a number: 2018-04-14 09:06:34 WARNING (MainThread) [homeassistant.helpers.condition] Value cannot be processed as a number: 2018-04-14 09:52:52 ERROR (MainThread) [homeassistant.components.sensor.wunderground] Error fetching WUnderground data: ContentTypeError("0, message='Attempt to decode JSON with unexpected mimetype: '",) 2018-04-14 10:06:43 ERROR (SyncWorker_7) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 10:16:45 ERROR (SyncWorker_37) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 10:26:48 ERROR (SyncWorker_34) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 10:30:19 ERROR (SyncWorker_22) [homeassistant.core] Error doing job: Task was destroyed but it is pending! 2018-04-14 10:30:19 ERROR (SyncWorker_22) [homeassistant.core] Error doing job: Task exception was never retrieved RuntimeError: cannot reuse already awaited coroutine 2018-04-14 10:36:47 ERROR (SyncWorker_16) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 10:56:51 ERROR (SyncWorker_11) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 11:06:52 ERROR (SyncWorker_7) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 11:26:56 ERROR (SyncWorker_36) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 11:46:33 WARNING (MainThread) [homeassistant.helpers.entity] Update of sensor.dark_sky_precip_intensity is taking over 10 seconds 2018-04-14 11:46:54 WARNING (MainThread) [homeassistant.components.sensor] Updating darksky sensor took longer than the scheduled update interval 0:00:30 2018-04-14 11:47:00 ERROR (SyncWorker_31) [homeassistant.components.climate.honeywell] SomeComfort update failed, Retrying - Error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)) 2018-04-14 11:51:35 WARNING (MainThread) [homeassistant.helpers.entity] Update of sensor.pws_precip_today_in is taking over 10 seconds 2018-04-14 11:51:35 ERROR (MainThread) [homeassistant.components.sensor.wunderground] Error fetching WUnderground data: TimeoutError() 2018-04-14 14:00:29 WARNING (MainThread) [homeassistant.helpers.entity] Update of sensor.pws_feelslike_f is taking over 10 seconds 2018-04-14 14:00:29 ERROR (MainThread) [homeassistant.components.sensor.wunderground] Error fetching WUnderground data: TimeoutError() 2018-04-14 14:36:34 WARNING (MainThread) [homeassistant.helpers.entity] Update of sensor.pws_temp_high_record_f is taking over 10 seconds 2018-04-14 14:36:34 ERROR (MainThread) [homeassistant.components.sensor.wunderground] Error fetching WUnderground data: TimeoutError() -
Are there supposed to be python packages with Home Assistant in Unraid. I looked at my deps/lib/python3.6 folder is something I added for my Sony TV. When I used home assistant prior to unraid there were a lot more folders in here. I copied my files over however did not copy the python folder over which was 3.5. I thought this would populate automatically however nothing is showing up. I am getting errors for my honeywell thermostat and myq garage door and a chromecast and I was wondering if it was related to not having these python files.
-
Not sure if this helps but I try to follow along with rsync and watch as it adds files. It seems that one file gets missed and then from then the rsync keeps working but never adds anything else and will eventually produce and error after some time saying that this file was an error.
-
Ok so I think i figured out getting rsync to work with a local source disk and a unassigned device for the destination. I am now trying to rsync a local source disk to a unassigned smb share but I am really struggling. It seems to be working sort of but i have some major concerns. I basically use the same code as above except modified it a little to sync to the share folder. So it looks like the following
#!/bin/bash Source2=/mnt/user/Media Destination2=/mnt/disks/FinalizerMediaBackup/Media ##################### ### Destination 2 ### ##################### ### Source 2 ### rm -rf "$Destination2"/Daily5 mv "$Destination2"/Daily4 "$Destination2"/Daily5 mv "$Destination2"/Daily3 "$Destination2"/Daily4 mv "$Destination2"/Daily2 "$Destination2"/Daily3 mv "$Destination2"/Daily1 "$Destination2"/Daily2 rsync -avh --delete --link-dest="$Destination2"/Daily1/ "$Source2"/ "$Destination2"/Daily0/ |& loggerWhen I run this the folders are populated on the share and it starts to run however a couple minutes in I get an error message that pops up and the process stops.
The message is
root: rsync error: error in file IO (code 11) at receiver.c(853) (receiver=3.1.3)I have ran it a couple of times and it seems to stop on the same file however I looked at the permissions of the original file and it seems to be the same as the others. If I try running the script again it acts like it is running but then weird things start happening and it will start removing some of the files and eventually alarm out on files that were originally there but has since removed. This doesn't really make sense to me yet.
The weird thing is I have copied the original source to a local unassigned device without any errors but when I try to do it over the network it errors out. My locations are correct because I see the files/folders start to populate. Is there something I am missing.
The destination is a Windows PC which is sharing the drive and the drive is a NTFS drive which is mounted in unraid using the unassigned devices SMB shares.
-
So i saw somewhere online that to help troubleshoot to run a test using AJA System Test. Not sure if it will help here or not but I will post my results just in case it does. It looks like I should be cable of getting better than the 80 MB/s that it keeps dropping to.
EDIT: So I have transferred a file back and forth a couple of times today just to see if anything has changed. It seems to be transferring at around 400 MB/s from Unraid to Windows PC and around 300 MB/s from PC to Unraid. Not sure why all of a sudden it is working now but it seems to be better for some reason. I will keep an eye on it but I have a feeling something is still not quite right but until then thanks for all the help.
-
11 minutes ago, 1812 said:
There may be an easier way than this, but:
on a fresh server reboot, open system stays and watch the ram/memory graph. If it maxes with “cached” then ram is full. For the ssd, you have to watch the capacity on the main tab.
Again, probably better ways to find out. But with that said, iirc, you have 32gb? or ram and at least a 256 gb 850 evo (don’t remember how much free space) but that should have high sustained write speeds well over the lower number you are getting.
Also note on in the main tab what disks are getting written to, if it’s in the array or on the cache disk. I skimmed the water parts of this , but you’ve verified the share you are using is set to cache=yes?
Yes that is right 32 gb or ram and the 850 evo is actually 500 gb. (About 400 free) Yes this share is using the cache disk. I verified that. When I go from Unraid to Windows this is what it looked like. The windows was not using the ram disk in this instance but it seems like I get the same thing either way. My Windows PC only has 16 GB or ram in it if that matters.
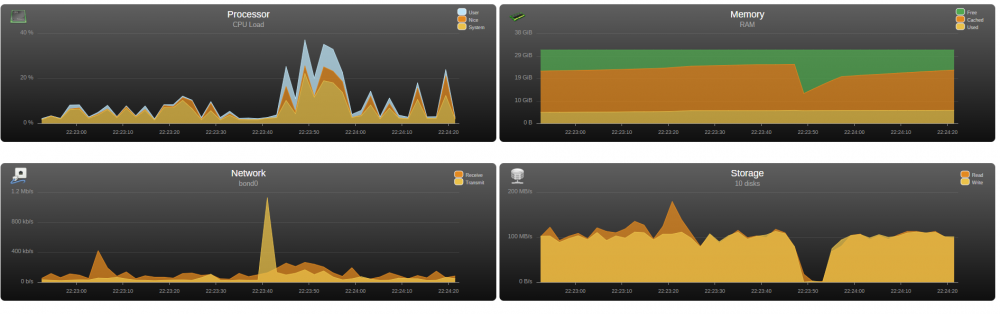
-
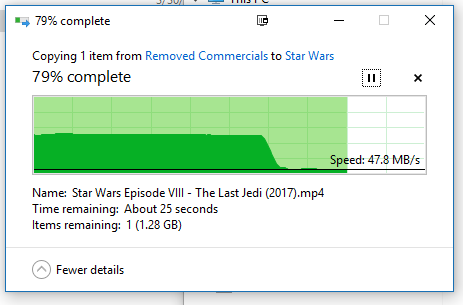
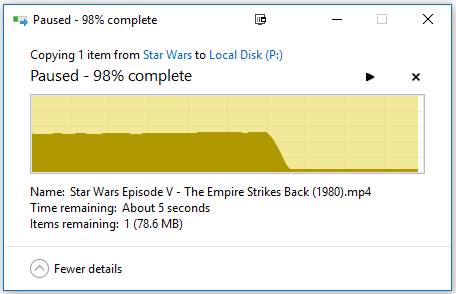
So I created a RAM disk using SoftPerfect. Here is what happens It transfers at about 1 GB/s for about half of the file then suddenly falls off to 80 MB/s. This was about a 5.75 GB file and I used a 6GB ram disk. So it seems to work half way through but then suddenly it reverts to Gigabit speeds.





[support] dlandon - Zoneminder 1.36
in Docker Containers
Posted
I have all 4 cameras running right now and as far as the tearing it seems a lot better but everything is a lot lower quality compared to where I was previously.
I have a couple other dockers running on my system but nothing that is really taking many resources up (Emby but nothing streaming at the time, no VM's)
My cameras are Reolink RLC-422 and Reolink RLC-410.
They are all wired.
I will attache my Unraid Diagnostics as well.
finalizer-diagnostics-20181019-1000.zip