

-
Posts
25 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by cmon_google_wtf
-
 Sorry for the x-posting everywhere, I'm tired and a little excited I got it working. The capability added with the 6.10 packages update allows for the successful execution of the discussion around virtiofs from the following two links. There is still manually adding the script file discussed, and a manual editing of the xml needed, but, as it is verified working (only be me, lite verification) I wanted to bring it to the devs' attention. The post in question: https://forums.unraid.net/bug-reports/prereleases/690-beta35-virtio-fs-fails-to-start-r1148 And the discord link: https://discord.com/channels/216281096667529216/786598848951746600/962875421404311572
Sorry for the x-posting everywhere, I'm tired and a little excited I got it working. The capability added with the 6.10 packages update allows for the successful execution of the discussion around virtiofs from the following two links. There is still manually adding the script file discussed, and a manual editing of the xml needed, but, as it is verified working (only be me, lite verification) I wanted to bring it to the devs' attention. The post in question: https://forums.unraid.net/bug-reports/prereleases/690-beta35-virtio-fs-fails-to-start-r1148 And the discord link: https://discord.com/channels/216281096667529216/786598848951746600/962875421404311572 -
EDIT: Holy stinky dog-poo! Okay kids, this all works using *exactly* the below xml (w/e/f your naming convention), just make sure when you create the *script, that you specify it with the shebang... Script: #!/bin/sh exec /usr/libexec/virtiofsd -o sandbox=chroot "$@" XML: <memoryBacking> <source type='memfd'/> <access mode='shared'/> </memoryBacking> ---- <filesystem type='mount' accessmode='passthrough'> <driver type='virtiofs'/> <binary path='/usr/libexec/virtiofsd-script'/> <source dir='/mnt/user/domains'/> <target dir='unraidshare'/> </filesystem> After you get it running, mount with the usual mount commands, in my case: sudo mount -t virtiofs unraidshare /mnt/unraiddata/ ---------See above!!! These are for notes of my progress...--------
-
Understood, and a mis-communication on where I am. The only time I have had UD mount it, was in the initial setup of the disk, when I set the `by-label` and mounted it in the VM using that path. After the OS install completed and I rebooted the VM, UD is no longer mounting it (passthrough option checked), the and the `by-label` for that disk is gone from `/dev/disks/by-label`, but unless I mount (in the VM options) either the first partition or the /dev/sdX option, I cannot get past the bootloader. This prompted the question as to if I was missing where I could passthrough and/or mount the /devX.
-
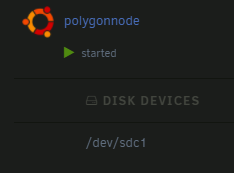
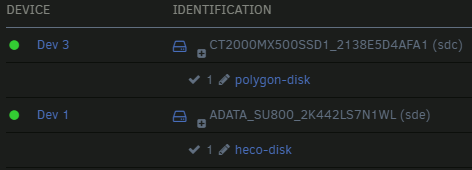
Forgive me, I tried search but came up not quite understanding. Use case: Simple, full disk pass-through to an Ubuntu VM. Performance is critical, so if there's a better option than UD, I'm all ears. I originally installed the OS using /dev/disk/by-label, with UD marking the device as passed through. After a reboot of the VM, by-label/X was gone, so I remounted in the VM as by-id, passing the first partition (/dev/sdX1) instead. From searching the thread, I found that this (sdX) might not be the best solution, and to use a devX mount instead, but I cannot for the life of me figure out how to both find and pass that devX drive. (dev 1, 2, etc I can see in the UI - how do I "mount" and pass that to the VM?) Thoughts?
-
Necro-ing the thread, but, this was the closest I could find for my issue as well. Did your change within the parens persist through a reboot/re-share/re-export of the shares?
-
I would love to see a Binance Smart Chain (BSC) Node Docker container re: https://github.com/vlddm/binance-smart-chain-node, https://github.com/binance-chain/bsc, https://docs.binance.org/smart-chain/developer/fullnode.html I have been struggling to get it to run through a VM with any sort of good performance, and am lazy, frankly. If someone were to port and do some type of auto-update for the base image, that would be awesome! Insta-install!
-
Good evening, @binhex. Starting on or about October the 10th, I am seeing that all of my *arr dockers and hydra are now ceasing to be able to use this docker for content searches, verified by removing the proxy settings to this docker. Is this related to the port forwarding issue and is it something that will work again in the future? -omni edit: I should include that I did update to the "next-gen" PIA settings with the following .ovpn config. remote ca-toronto.privacy.network 1198 remote ca-montreal.privacy.network 1198 remote ca-vancouver.privacy.network 1198 remote de-berlin.privacy.network 1198 remote de-frankfurt.privacy.network 1198 remote france.privacy.network 1198 remote czech.privacy.network 1198 remote spain.privacy.network 1198 remote ro.privacy.network 1198 client dev tun proto udp resolv-retry infinite nobind persist-key # -----faster GCM----- cipher aes-128-gcm auth sha256 ncp-disable # -----faster GCM----- tls-client remote-cert-tls server auth-user-pass credentials.conf comp-lzo verb 1 crl-verify crl.rsa.2048.pem ca ca.rsa.2048.crt disable-occ
-
@binhex Would it be possible to have the script run through a list of .ovpn files after failing to port forward with one? Use case would be, CA-Montreal is having port-forward API issues right now, and as it is the first in the list alphabetically (I assume), the script only chooses it to retry with. Could it instead take a list of all .ovpn files in the config/openvpn directory and try them each in succession until a successful API call is made? As always, thanks for your work!
-
[Support] ich777 - Gameserver Dockers
cmon_google_wtf replied to ich777's topic in Docker Containers
Sir, You are absolutely correct. I was under the impression that the GAME_PARAMS were what the EXTRA_JVM_PARAMS actually are as that was the only field I saw during the initial setup. After I had dug in I found both variables, reset the docker to stock, added the jvm variable, added my params, and everything was joy. Running paper and a couple mods with no issues! Thanks for the reply, and thanks again for the image; running great! -
[Support] ich777 - Gameserver Dockers
cmon_google_wtf replied to ich777's topic in Docker Containers
Good morning! I installed the Minecraft Basic server for the first time today, and was getting presented with errors to the effect of Failed to start the minecraft server joptsimple.UnrecognizedOptionException: X is not a recognized option at joptsimple.OptionException.unrecognizedOption(OptionException.java:108) ~[server.jar:?] at joptsimple.OptionParser.validateOptionCharacters(OptionParser.java:633) ~[server.jar:?] at joptsimple.OptionParser.handleShortOptionCluster(OptionParser.java:528) ~[server.jar:?] at joptsimple.OptionParser.handleShortOptionToken(OptionParser.java:523) ~[server.jar:?] at joptsimple.OptionParserState$2.handleArgument(OptionParserState.java:59) ~[server.jar:?] at joptsimple.OptionParser.parse(OptionParser.java:396) ~[server.jar:?] at net.minecraft.server.MinecraftServer.main(SourceFile:879) [server.jar:?] I did a little research and digging in the start-server script and found that the ${GAME_PARAMS} were being called after -jar. I corrected this call in the file and everything started great after that! Part of my digging found: https://bugs.mojang.com/browse/MC-148234?attachmentViewMode=list which lead to the answer! Thanks for the image! (Side note: it is only downloading 1.15.1 currently. 1.15.2 is the latest!) Edit: I see looking further that you have options for EXTRA_JVM_PARAMS, but nowhere in the default container pull does it have an input field. I would wager that adding one would allow one to retain the GAME_PARAMS at the end, and use the EXTRA_JVM_PARAMS in the place where I have them now though. Just a heads up. -
I apologize @binhex for the direct message, as I did not see this thread... I am also wanting to get a status update/request in for a Firefox/Chrome docker with possible Privoxy support (though that could just be pointed through the browser to your other privoxy solution as well). Sorry again and thank you for all you do!
-
I saw a couple of you fancy people asking about a reverse proxy setup (for the searchers: nginx, LetsEncrypt, Organizr, 404, page not found), and only saw one config posted earlier that someone got to work (it didn't for me), so I wanted to throw my $.02 in. This config works for me under a standard Organizr/LetsEncrypt combo setup: in default.conf: location /rutorrent { auth_request /auth-1; include /config/nginx/proxy-confs/rutorrent.conf; } in rutorrent.conf: # RUTORRENT reverse proxy location /rutorrent/ { proxy_pass http://192.168.XXX.XXX:9080; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection keep-alive; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } Please note, the closing '/' in the above config file. Without that closing '/' it will not route through properly, even if it prompts for credentials and they are entered correctly, it will nginx 404 error. Anywho, hope it helps somebody!
-
I appreciate you letting me know, and I had tried a bunch of different setups in my attempts to get it routed through, the closest I got was in my setup up above, posted again here for posterity: In my default config: location /rider { auth_request /auth-1; include /config/nginx/proxy-confs/rider.conf; } and in the rider.conf: # RIDER reverse proxy location /rider { proxy_pass http://192.168.86.63:6080/vnc.html?resize=remote&host=192.168.86.63&port=6080&autoconnect=1; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; index vnc.html; alias /path/to/noVNC/; try_files $uri $uri/ /vnc.html; } with the result being that noVNC error page. It's definitely connecting to the docker image, just not connecting all the way through the noVNC portion, some nginx pass-through setting somethingorother I assume but don't pretend to understand, ha!
-
[Support] Linuxserver.io - Bazarr
cmon_google_wtf replied to linuxserver.io's topic in Docker Containers
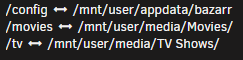
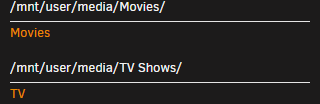
Hopefully this won't confuse somebody more, but, I asked about the setup on the Bazarr Discord and got some info from @morpheus65535 on how to get things mapped/pathed correctly. In the initial setup of the Bazarr container, you chose the path for where Radarr/Sonarr are currently mapped to, in my case: This will set the internal mapping of the subtitle paths to /movies and /tv (NOTE THE cAsE. IT IS DIFFERENT THAN THE DOCKER TEMPLATE MAKES IT APPEAR TO BE DURING INITIAL SETUP.) Actually maps like this. (Check the configuration page for those Host Paths) That's fair enough, just a mapping description discrepancy, but here is where the confusion is going to lie for most of us, when you integrate Radarr/Sonarr during the first run of Bazarr, it's going to "import" the mapping of your Radarr/Sonarr containers, in my case, to '/media'. THIS is the mapping you want to change in the Bazarr setup. Point your '/media' to '/tv' and '/movies' (see below) and again, and MIND THE CASES.

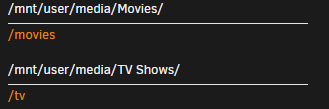
-
It's all good man, like I said, the docker itself is running perfectly and I have no issues at all, just looking to expand functionality a bit through that remote access. Thanks for another great product!
-
Hey @binhex, As usual for your containers, it all seems to be working swimmingly! I did want to ask though, if you had dabbled at all in adding the container to nginx and/or through organizr. I seem to be able to get to a noVNC error page once I get it added to the config files, but can't get it to the interface itself. This is obviously stretching to the point of possible irrelevancy for this thread, but, wanted to ask, just in case! Thanks! # RIDER reverse proxy location /rider { proxy_pass http://192.168.86.63:6080/vnc.html?resize=remote&host=192.168.86.63&port=6080&autoconnect=1; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; index vnc.html; alias /path/to/noVNC/; try_files $uri $uri/ /vnc.html; }
-
I think this is more likely than an actual bug. I've never managed to find one that I could reproduce. Ever. Unless it was in my own code... I've outlined the steps I took above as to what I did, but as far as an actual issue I don't believe there really is one. I fully think that I was in the wrong in some way or another, and was saved by the fact that there are systems in place to correct stupid like that.
-
Oh, something definitely went wrong, and I have no idea where it did. I did not need to go in to build a new config (through the button) or anything other than the steps I listed up above. The solution seems again seems to be to NOT use a smaller drive (which I never will again) and to make sure that the rebuild parity is checked. As for the cause? Unknown. I did not keep any sort of documentation on the procedure other than just memory, but if I need to do any further replacements in the future, I will take greater care in what I am doing.
-
Interesting... So even though I dropped the old drive off the config and added the new one with the regular drive replacement procedure, because the old drive wasn't zero'd out, it left a bad parity state? I followed the procedure listed here: https://lime-technology.com/wiki/Replacing_a_Data_Drive and it all seemed to work out as planned, despite it stating that the replacement drive could not be smaller. An interesting issue, but one I am glad to be finished with. Thank you all for your help, I certainly appreciate it! For any future drive replacements I will be sure to use a same size or larger disk, and triple-check that the rebuild parity is checked.
-
Negative, in the 4TB > 3TB instance I moved all the files off the emulated disk. Stopped the array, removed the old disk, started, stopped, popped the new drive into its spot and started again. It did a proper parity check following the preclear and formatting and continued on its merry way. For the 8TB however, I did check the parity is valid box once it finished its preclear and formatting routine. Maybe that's the one it came from? Odd that it would only have been bad for 2TB worth of it though.
-
I did add an 8TB drive last week, and just prior to that replaced a 4TB drive with a fresh 3TB (after moving the files via unBALANCE to the other drives off the emulated one).
-
So a little over 2TB worth of data that wasn't on the parity drive overall after it was all finished. That's no fun... I did as you suggested and played some media of off each drive but one (that is empty) and everything appears to be in order. I assume that another full parity check after I get the UPS in would be a good idea then? Just to make sure that Parity is actually up to date and contains proper data? Thanks for the reply @pwm.
-
Thank you for the reply. It's sitting at just under 500,000,000 now at 40% complete... Craziness. It was most definitely writing data to the array, but I have no idea how this many errors were generated. I certainly feel the absolute need for the a UPS at this point however. In that vein, what is the metric its actually measuring/correcting, bits? Bytes? You mentioned my "only option now", what would have been the options before, and what is before for that matter? Edit: The first round of an error check is now complete. Result: Last check completed on Wed 06 Jun 2018 06:34:20 PM MDT (today), finding 533551368 errors. Should I go ahead and call this a day, or submit another diagnostics archive and continue with another step? The UPS is on its way scheduled for next week before delivery, btw.
-
First things first, I acknowledge that I am dumb and needed a UPS. It is now on the way. My subdivision had a power outage today, courtesy of a... particularly bad driver meeting a power line and/or transformer box, and as a result wreaked havoc on my unRAID system. Immediately upon power restoration I begin a Parity Check, writing corrections to Parity, and am now 4 hours in. As is expected I have more than a day to go as I have an 8TB drive for parity. What is not expected, however, is the fact that I am currently sitting at 80334694 Sync Errors Corrected. Observations: Everything appears to be running normally. All drives, parity, array, cache, and boot appear to be functioning normally. Additionally, dockers appear to be fine as well. There are no errors being reported in the smart reports nor Main GUI page for any of the drives. FS is xfs across the board, with the exception being Parity, and cache (which is btrfs for the latter). From what I can tell, all files directly accessed through SAMBA appear to be working as expected as well. Last Parity Operation was done last week with the installation of a new 8TB data drive to the array and there were no issues reported. Questions: How screwed am I? Do I allow it to continue, or stop it for further troubleshooting? Why didn't I buy a UPS sooner? What is the next step in the process to recovery, should there be an error found? What should I be looking for in an error, or in the logs. (I want to learn to be less ignorant, not necessarily just be told to forget) Attached is the Diagnostics archive. I appreciate any and all replies and thank you for your time. ~Omni tower-diagnostics-20180605-2132.zip
-
Hey @binhex, First off, amazing work on all of these containers. I've only just gotten started with unRaid, and am very pleased with the level of work that has been put into making everything all work together without much hassle whatsoever. That said, I am currently using your binhex-sabnzbdvpn container, but wanted to try nzbget as an alternative to compare interface and saturation rates. Is there any possibility in the future of offering a binhex-nzbgetvpn option? I see that @jshridha has a fork (docker-nzbgetvpn) but, I'm attempting to keep everything I can in (bin)house as possible for the moment while getting the server set up. Thanks again for the containers, and for your reply! ~Omni











