

dnLL
-
Posts
218 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by dnLL
-
-
Old thread but also an issue for me right now. `/etc/nginx/conf.d/servers.conf` and `/etc/nginx/conf.d/locations.conf` are dynamically rewritten each time nginx is loaded (as programmed in `/etc/rc.d/rc.nginx`). Other files in `conf.d` are ignored. Editing `nginx.conf` directly on every boot could create problems later on with future updates.
Not sure what's the best approach to this. Also curious why the nginx_status was disabled, as there are traces here in the forums and elsewhere in Unraid that this might have been enabled in the past. Performance issue?
-
I did some digging thanks to the File Activity plugin combined with iostat.
root@server01:~# iostat -mxd nvme0n1 -d nvme1n1 Linux 6.1.74-Unraid (server01) 03/17/2024 _x86_64_ (16 CPU) Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util nvme0n1 1.30 0.10 0.00 0.00 0.64 76.38 94.35 2.97 0.00 0.00 0.72 32.26 25.29 2.76 0.00 0.00 2.61 111.85 4.48 2.10 0.14 8.74 nvme1n1 1.32 0.10 0.00 0.00 0.63 76.47 98.80 2.97 0.00 0.00 0.51 30.81 25.29 2.76 0.00 0.00 2.44 111.85 4.48 2.09 0.12 8.56
So, writing around 3 MB/s consistently while looking with iostat. With the File Activity plugin, I noticed the following:
** /mnt/user/domains ** Mar 17 22:49:25 MODIFY => /mnt/cache/domains/vm-linux/vdisk1.img Mar 17 22:49:26 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:49:26 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 Mar 17 22:49:27 MODIFY => /mnt/cache/domains/vm-windows/vdisk1.img ... Mar 17 22:49:27 MODIFY => /mnt/cache/domains/vm-windows/vdisk1.img Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-dev/vdisk1.img ... Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-dev/vdisk1.img ** Cache and Pools ** Mar 17 22:44:13 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:44:29 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2
For instance, lots of writes coming from my Home Assistant VM running HAOS. That would be because the data from HA is hosted locally on the VM rather than on a NFS share. That also explains while I'm getting a lot of writes without necessary reading it. I might want to work on that and on similar issues with my other VMs.
Thought I would post my findings just to help others with similar issues using the right tools to potentially find the problem. Obviously with the File Activity plugin, I don't get the actual quantity of data that is being written but it gives me a good idea.
-
I have a RAID1 of cache NVME SSD drives. I originally set it up in BTRFS but recently changed for ZFS.
I'm trying to understand why is my writes usage so much higher than reads. Currently both SSDs are sitting down at around 250 TiB write and 8 TiB read per the smart report with 395 days of uptime.
On my cache are the VMs, the dockers and temporary cache storage for other shares. When I first installed my SSDs, I was plagued by an issue with dockers where I would get super high write usage (multiple TiB per day). This was eventually resolved. Now, it's more or less following the same curve with about 20 TiB of writes per month. That's about the size of my whole array (24 TB), which is obviously ridiculous.
My questions are the following.
1- When the mover is invoked, should there be a 1:1 ratio between the previous writes and the files being moved turning into reads?
2- When loading VM disk files from the cache, I assume it reads the whole file? Does every read/write within the VM get transferred to the VM disk file (in this case my cache)?
3- Anything particular pertaining to dockers that I should be aware of concerning high writes usage? I'm using the folder option for docker storage.
Sent from my Pixel 7 Pro using Tapatalk
-
Thanks for pointing this out. Obviously when grepping the entire config, I'm not saying "delete every mention of X" but more "hey this might send you in the right direction". Might not necessarily be the dockers, could be a forgotten user script or whatever plugin, hence the wider grep.You can have .cfg files in config/shares folder which contain the settings for shares that no longer exist. These will not create any shares, they just have settings that would be applied if the corresponding share actually did exist. And deleting these won't have any effect on containers that specify paths which would create a share. They would still get created with default settings.
If you did want to automate the search in some way (instead of manually inspecting the paths specified in each of your containers on the Dockers page), you would need to search the contents of each of your docker templates in config/plugins/dockerMan/templates-user.
Sent from my Pixel 7 Pro using Tapatalk
-
 1
1
-
-
This happened to me as well but only when the network gets disconnected after boot. Reconnecting the network doesn't fix the issue, however rebooting with the network correctly plugged in will prevent the errors from showing in the logs.
I've been having issues recently on 6.12.7 and 6.12.8 with Unraid crashing when the network gets disconnected (ie. router rebooting), so I was doing some tests (but wasn't able to reproduce sadly). Not sure any of these kernel errors are related to the crash issues but that's my only lead for now.
It's probably important to note that I'm using IEEE 802.3ad dynamic link bonding over 2 interfaces (LACP) and it only happens when connection to both interfaces is lost simultaneously.
-
On 10/1/2017 at 5:04 PM, wgstarks said:
This is just a shot in the dark, but I recently had a similar issue because I had a deleted share that still had a path mapped in a docker. The docker kept recreating the folder/share.
Thank you!! I'm aware this is a 7-year-old thread but, I just wanted to report that this was my exact issue, I had an unused path in a docker trying to access my deleted share and it would just `mkdir` it when not existing, bringing back a share every damn reboot.
To help find the issue (replace `share` by your share name):
root@Tower:~# grep -R "/share" /boot/config
You might have to exclude some results by adding an additional `| grep -v something` at the end, for example if you use the dynamix file integrity plugin you might get some false positives here.
-
On 10/2/2023 at 5:38 PM, Erich said:
I know I will probably get a lot of flack/hate mail for this, but...
How about a completely redesigned UI that is a lot easier to use! I am thinking something similar to Synology's DSM, or QNAP, QUTS Hero.
Ok, throw your daggers!")
As someone who has never used the alternatives you mention, what it is about the Unraid UI that you don't like?
Personally, I think the settings/tools pages could be improved, some stuff I never remember whether it's a tool or a setting (it's not always obvious) and the categories within both pages are not really helping The docker and VM pages are pretty good IMO. The dashboard is a lot better now as well.
I guess the overall theme could be changed completely to a more traditional and modern vertical menu with a separate mobile UI (or dedicated official app) but that doesn't bother me too much.
-
So how does this work exactly? When I reset my BMC it doesn't update the fans anymore. Nothing in the logs, am I supposed to see something every 30s?
-
Great, very happy to read this. I checked with lsof and interestingly enough nothing is returned for /mnt/cache since every docker is stopped. I should have checked with lsof on /dev/loop2, thought about it too late. Anyways.
Yeah, there are special instructions in the 6.12.3 announce post to help folks get past that:
https://forums.unraid.net/topic/142116-unraid-os-version-6123-available/
Glad you figured it out on your own, kind of impressed really : )
Sent from my Pixel 7 Pro using Tapatalk
-
1
-
-
Yup, same issue on Unraid 6.12.2 (while trying to reboot to install 6.12.3). I always manually stop my dockers/VMs before the array and rebooting, sadly the array wouldn't stop.
Jul 14 23:16:52 server emhttpd: Unmounting disks... Jul 14 23:16:52 server emhttpd: shcmd (38816): umount /mnt/cache Jul 14 23:16:52 server root: umount: /mnt/cache: target is busy. Jul 14 23:16:52 server emhttpd: shcmd (38816): exit status: 32 Jul 14 23:16:52 server emhttpd: Retry unmounting disk share(s)... Jul 14 23:16:57 server emhttpd: Unmounting disks... Jul 14 23:16:57 server emhttpd: shcmd (38817): umount /mnt/cache Jul 14 23:16:57 server root: umount: /mnt/cache: target is busy. Jul 14 23:16:57 server emhttpd: shcmd (38817): exit status: 32 Jul 14 23:16:57 server emhttpd: Retry unmounting disk share(s)... Jul 14 23:17:02 server emhttpd: Unmounting disks... Jul 14 23:17:02 server emhttpd: shcmd (38818): umount /mnt/cache Jul 14 23:17:02 server root: umount: /mnt/cache: target is busy. Jul 14 23:17:02 server emhttpd: shcmd (38818): exit status: 32 Jul 14 23:17:02 server emhttpd: Retry unmounting disk share(s)...
Umounting /dev/loop2 immediately fixes it.
-
This is lovely. Can work as a user script as well. Be sure to read the parameters carefully on the docker hub webpage if you want to be able to stress test with or without saturating your CPU/memory completely.
-
I would really love to hear more opinions on this, just watched @SpaceInvaderOne's video on how to easily reformat the cache pool. Been using BTRFS for a while.
-
I'm surprised this hasn't been answered as it comes pretty high on search engines. Anyways.
The important thing is to understand what we are dealing with here. For instance, here is what my /var/log looks like currently:
root@server:~# df -h /var/log Filesystem Size Used Avail Use% Mounted on tmpfs 128M 105M 24M 83% /var/log root@server:~# du -ahx /var/log | sort -hr | head 105M /var/log 50M /var/log/syslog.2 38M /var/log/nginx/error.log.1 38M /var/log/nginx 8.3M /var/log/samba 7.3M /var/log/syslog 5.6M /var/log/samba/log.rpcd_lsad 2.7M /var/log/samba/log.samba-dcerpcd 1.4M /var/log/syslog.1 704K /var/log/pkgtools
So, what is going on here? Long uptime, mover logging enabled, and... a bunch of nginx errors. Unsure why but nginx crashed (the webUI became weirdly unresponsive), it took me a while to notice as I wasn't specifically monitoring the content of that log file and didn't visit the webUI in a while as well. Anyways, of course here cleaning things up would be good enough, at the same time 128M is a very small amount of space. You don't want your /var/log to fill up your memory, but you don't want to lose your syslog in the event of an issue similar to the nginx issue I had. Basically, as long as you have plenty of memory available, it's safe to expand it to say 512M or even 1G, by 2023's standards keeping 1G of logs isn't that bad. Using a proper syslog server would definitely offer better solutions in terms of long-time logging and archiving.
-
On 9/21/2018 at 7:56 AM, spatial_awareness said:
This is a known issue with Docker on BTRFS, which is a supported filesystem.
I hit this after adding and deleting a couple dozen containers. I can confirm it takes about 10 minutes to resolve by disabling docker, deleting the docker.img file, re-enabling Docker, and having the apps reinstall.
It's not unique to unRAID, it's because this command fails:
Technically, this isn't a docker problem, BTRFS should do its job and delete the subvolumes, but BTRFS is a cutting edge filesystem, something Docker requires.
Anyway, on another OS, you'd have to follow a bunch of steps (see above for examples) but here in the world of unRAID with container and install orchestration it's a few clicks. Hopefully BTRFS fixes this.
Still a problem 5 years later. Moved back to a XFS docker image because of this, subvolumes never get deleted, if you stop docker the subvolumes are just unmounted, best way is to delete them from your directory and restart from scratch... which sucks.
-
On 2/28/2023 at 10:09 AM, flyize said:
This saved me. Wow, nice find.
Future people, if this works for you, please reply so that this stays on top of Google.
Same issue, same fix. Lost 2 hours restoring backups trying to figure out why moving the vdisk was problematic. Unraid should really add a "type" field for people using the UI rather than the XML, it would make it so obvious. Unsure why they wouldn't support the creation of other types (such as qcow2) of vDisks anyways.
-
1 hour ago, Frank1940 said:
Yes, I believe it is. Have a look at Settings >>> Scheduler and you should find the setup parameters.
Didn't think about that, thank you.
-
Is the SSD trim plugin dead for 6.11.x? Don't see it available at all. Is Unraid handling this by itself now?
-
Thanks for this!
Only plugin I used before that isn't there:
xinetd-2.3.15-x86_64-3.txz
-
Every torrent has been stuck to downloading metadata since a few days on my side with the PIA vpn. Nothing in the log, the UI works well, I get an IP from PIA without any issue. I tried changing the network card used by qbittorrent in the UI options between tun0 and eth0 without any luck. Seems to be related specifically with PIA?
Edit: I fixed it by forcing an update of the docker even though there was no update. Very weird problem. I see other people commenting on issues with PIA and qBittorrent online (not specifically to Unraid), I'm positive there is an issue somewhere but anyways.
-
On 9/30/2022 at 1:45 PM, thecode said:
While my answer is not going to get likes, I don't think it is LT responsibility to add this to the release notes.
Note that Community App is not an official part of Unraid (although a very important one), in addition, users can install any plugin the want not only via the Community App.
You don't expect LT to test every release against all available plugins in the Community App and against every plugin you can find.
While I agree with this, the plugin was specifically marked as deprecrated on Community App (if I understand correctly). Maybe Community App could handle this better and warn the user about plugins that have not been updated since the last major version?
This is one more reason to add an option to run Unraid as a VM within Unraid. This is something I've been doing for a while, I paid an extra licence for it to run correctly and have 2 flash drives instead of 1, but it's been a life saver for me. While Unraid isn't exactly your typical "production-ready" operating system, many of us homelabers start with the smallest of project only to eventually host projects that people do rely on. Having a test VM to see what changed and especially to test plugins against the new Unraid version saved me precious hours of uptime on my main system. Anyways.
Hopefully this can be handled better in the future.
-
Hello y'all,
My monitoring tools started showing my Unraid server was using a lot of shared memory. Here is the chart from the last 24 hours (with the server mostly idling):
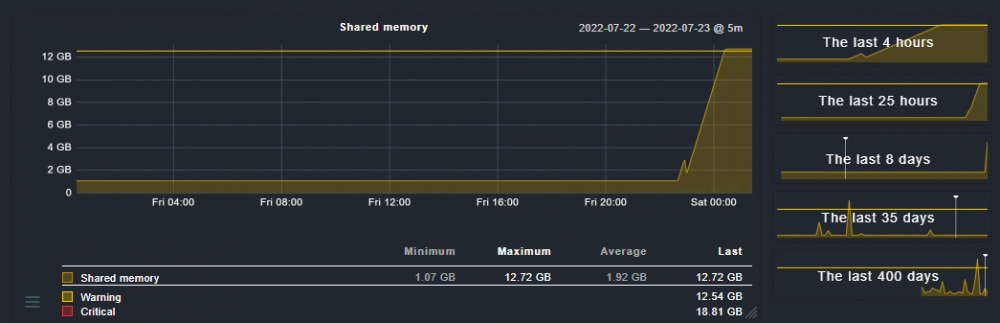
So, I did a little bit of search on the web and tried the following:
root@server:~# free -m total used free shared buff/cache available Mem: 64191 30582 18970 13022 14638 19920 Swap: 0 0 0 root@server:~# ipcs -m ------ Shared Memory Segments -------- key shmid owner perms bytes nattch statusNot much to see here, except I do see there are indeed 12+ GB worth of shared memory. I then stumbled upon the following post (https://stackoverflow.com/a/40712727/1689179) and script:
cd /proc for i in `ls -d * | grep -v self` do if [[ -f $i/statm ]];then echo -n "$i "; cat $i/statm | perl -lan -e 'print ($F[2] * 4096)'; fi done | sort -nr -k2 | headI got the following results:
root@server:~# sh test 1034 49528832 19397 30261248 2919 29437952 1445 26116096 1062 24440832 5986 23838720 5598 23777280 5807 23760896 6567 23732224 6266 23629824 root@server:~# ps -p 1034 -p 19397 -p 2919 -p 25669 -p 1062 -p 5986 -p 5598 -p 5807 -p 6567 -p 6266 PID TTY TIME CMD 1034 ? 03:52:53 dockerd 1062 ? 01:44:31 containerd 2919 ? 00:08:48 mono-sgen 5598 ? 04:03:06 qemu-system-x86 5807 ? 15:12:03 qemu-system-x86 5986 ? 15:52:44 qemu-system-x86 6266 ? 2-19:39:15 qemu-system-x86 6567 ? 04:24:21 qemu-system-x86 19397 ? 00:41:01 Plex Media Serv
So dockerd/containerd and qemu. I don't see anything relevant in the logs... what could have triggered the sudden raise of shared memory usage?
-
On 4/8/2022 at 12:47 AM, dnLL said:
I'm using the USB Manager plugin to run an Unraid VM within Unraid and since then, I'm getting this error every night:
fstrim: /mnt/disks/UNRAIDVM: the discard operation is not supported
I could uninstall the plugin and run the fstrim command only on my cache but a fix would be great. Not sure why it tries to trim my USB drive.
Has this been fixed?
-
I'm using the USB Manager plugin to run an Unraid VM within Unraid and since then, I'm getting this error every night:
fstrim: /mnt/disks/UNRAIDVM: the discard operation is not supported
I could uninstall the plugin and run the fstrim command only on my cache but a fix would be great. Not sure why it tries to trim my USB drive.
-
1
-
-
I want to monitor my Unraid licence status (trial expired or not, basic, standard or pro with X drives connected out of the Y limit). Is there a way directly on Unraid to do that from the command line interface? I started looking at /usr/local/emhttp/plugins/dynamix/Registration.page but I was wondering if there was a clever way to do that other than reverse engineer the PHP and try to run it from the CLI.


get nginx_status via stub_status
in User Customizations
Posted · Edited by dnLL
Got it working. Whether it's worth the hassle or not depends on what you are trying to do... monitoring the nginx status webpage from Unraid isn't particularly useful outside of academic purposes.
If you look at /etc/rc.d/rc.nginx, it overwrites /etc/nginx/conf.d/locations.conf and /etc/nginx/conf.d/servers.conf on every reload. locations.conf is where you want to add the status page, so you need to edit build_locations(). I suggest adding the entry after nchan_stub_status to make it look like that:
location /nchan_stub_status { nchan_stub_status; } location /nginx_status { stub_status; }Now, this might get overwritten after an update or a reboot (haven't really tested yet), so you might want to add a user script that runs on first start of your array to edit rc.nginx and reload it.