

chiefo
-
Posts
30 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by chiefo
-
-
+Also ran into upgrade issues with the update to v4. Per the v4 sonarr release notes I was able to uncorrupt database and it is now working fine.
"
Issues when upgrading
If you had a lot of preferred words in Sonarr v3 then you will see many migrated custom formats in v4. These will need to be edited or deleted and readded. The {Preferred Words} naming token is also replaced with the {Custom Formats} token. Check your naming strings.
Due to multiple database migrations we’ve seen that some corrupt databases that were doing OK in v3 have broken in v4. You can try to follow our corrupt database repair guide Useful Tools | Servarr Wiki 102 or reach out to one of our Support channels."6
-
Per the Github for this docker, this is a Ubuntu Jammy docker. We need docker 20.10.10 or higher to resolve. Unraid 6.10 RC-6 was released today that includes 20.10.14. After upgrading to rc-6, i was able to swap to latest ombi docker correctly.
-
4 hours ago, tmoran000 said:
How do you roll back in unraid?
Change the repository in the docker from :latest to the version you want, ie: linuxserver/ombi:v4.16.12-ls119
-
 1
1
-
-
Updated my docker today and now I'm seeing Failed to create CoreCLR, HRESULT: 0x80070008 spammed in the log. Web gui isn't working any more either. Anyone seeing this?
Rolled back to v4.16.12-ls119 to resolve
-
Glad you were able to find a fix! I already had an email out to support who replaced my key.
-
1
-
-
After two moves, I was finally able to boot my server again. Turns out my flash drive died/corrupted. Was able to successfully pull my flash backup down from the tool and get the server booted up (all though all my plugins were in an error state, manually reinstalled community apps from the file on the err folder then pulled the latest myservers plugin). Once I had the plugin I tried to replace my key, it initially errored out due to multiple keys on my flash drive, which I would have expected. I then removed the extra keys and attempted to replace my Plus License key as it no longer matched. After hitting replace key, the myservers popup briefly flashed the logon window as if I wasn't logged in, then returned to purchase/replace key. Tried in both chrome and edge. Unraid 6.9.0 and myserver 2021.10.12.1921. I moved my key from /config so I now had no valid key on the server. Now hitting replace key takes me to an actual log on attempt, which then took me to a page that says key couldn't be replaced and to contact support. I've sent an email to support to get a replacement, but it seems like the logic for replacing a key with an invalid key is causing some sort of loop. I would have expected to get the same sort of error/contact support message when replacing a mismatched key instead of the window looping repeatedly on purchase/replace key.
Has anyone seen this or is it just a bug? Does the plugin have any logs I can provide to help see why it was looping?
-
Just today noticed that a recent update seems to have broken my ability to approve requests. I've been on V4 for some time now. Basically the screen dithers and it looks like its popping up my approval button too far below the screen as I can barely see the box. Is anyone else running into this? I tried from my desktop and mobile. Also tried switching from the dev docker repo back to the stable as well to no avail.
Edit: Appears to be a known issue: https://github.com/Ombi-app/Ombi/issues/4208
-
16 hours ago, Energen said:
So despite the lack of ability to actually configure any encoder settings / resolutions / etc I've been running this between my Unraid docker and Windows with Docker Desktop (does not work 100% accurately, but it works well enough to make use of it) and feeding it a ton of media files that I wanted to see the results on. I'm fairly impressed with the results. I've converted around 300GB+ of media files to a fraction of that and the quality appears to be very good.
I have not figured out a way to force a conversion of media files that Unmanic thinks is already in the correct format. Just because it might be in the same format does not mean that I don't want to try to convert it for space saving reasons.
@Josh.5 option to force possible?
Maybe I'm wrong but this isn't trying to change the video quality, just converting from x to y codec and possible file format. Meaning even if you ran through something that's already in the right file format and codec, it wouldn't change size.
-
1 hour ago, tasmith88 said:
How do we blow it away?
*Not sure if this can cause any issues, although I personally haven't seen any problems, perform at own risk*
Stop the docker and then delete the following file from your appdata: appdata\unmanic\.unmanic\config\unmanic.db. Then restart the docker
-
1 minute ago, dertbv said:
If you blow away the entire database won't it go through every file that you have ever done?
It does, but it makes the gui respond faster. It also confirms its already hevc and skips the file so its not rencoding
-
1 hour ago, dertbv said:
When opening the webpage it is taking a while to populate the see all records. then it takes more time to actually view details on a completed item. Chosing failures and massive wait time..
I've seen something similar. Mine has gotten to the point twice where the page will never load when i try to view all records. I've had to blow away the database to restore functionality to that page. I can almost never get it to open an individual record even after starting with a fresh database. The entire tab locks up
-
14 hours ago, pyrater said:
anyway to make it do multiple libraries? Movies and TV

-
2 hours ago, cjjermont said:
Is it normal to have this many failures?

Sent from my iPhone using Tapatalk If its image based subs instead of text based it will fail. Mine also retry the same failures when it reopens.
If its image based subs instead of text based it will fail. Mine also retry the same failures when it reopens.
-
1
-
-
14 hours ago, RichRMG said:

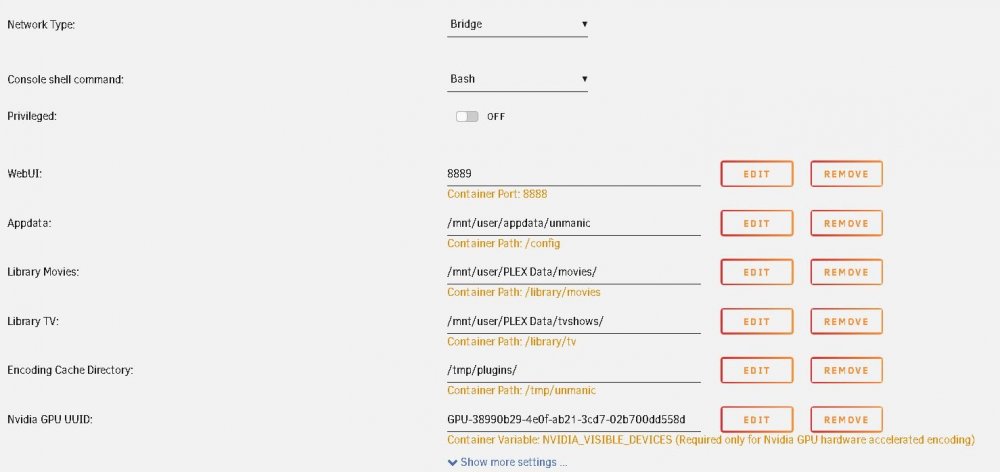
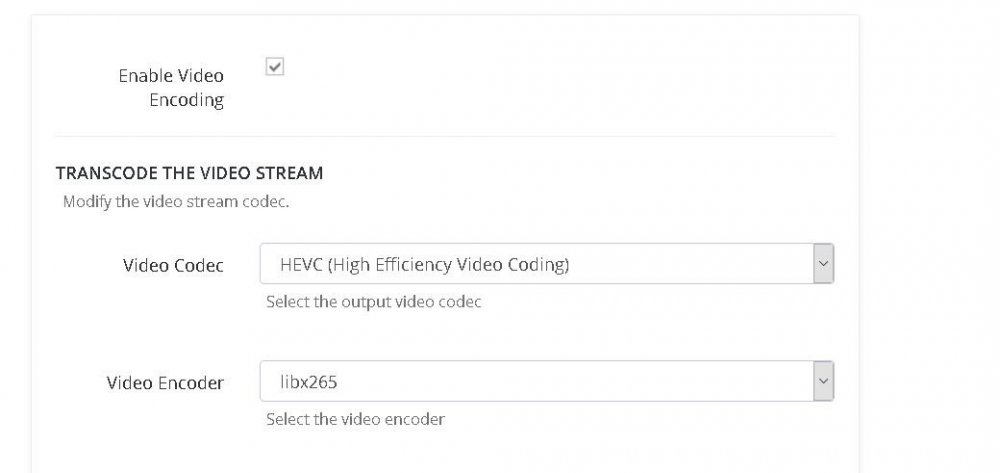
Yeah, Libx265 is the Cpu encoder. Change that to one of the two nvidia ones. I use nvenc_hevc
-
12 hours ago, RichRMG said:
yes,, gpu transcoding works fine in plex
running the nvidia version of 6.8.3.
Did you change the encoder under settings, Video encoding to use one of the two nvenv options?
-
Just now, binhex said:
i see its been re-flagged again, it will be built when its available 🙂
Many thanks!
-
1 hour ago, binhex said:
1.16 has now been updated on AUR and the image is now built, please pull down.
Looks like 1.16.1 is now the latest. Any chance we can get it updated to that?
-
5 hours ago, klipp01 said:
Yeah this has happened to me a few times. Just restart container and it goes back to normal.
Sent from my Pixel 2 XL using Tapatalk
Thanks for confirming I'm not crazy. It happened once more after I posted. I also noticed that I could no longer access the completed tasks or the browser tab would lock up. I landed up stopping the docker and deleting the database file. Haven't seen the issue since and my history is now working better. Everything is super snappy again.
-
Any one notice an issue where unmanic isn't transferring completed files to the drives? I notice sometimes while the worker is constantly updating the completed task lists isn't. Not showing successes or failures. Woke up this morning to my cache drive filling up and saw unmanic had over 135gb on the cache. Restarted the docker and it cleared it all out. I'm guessing its not moving it so its not getting marked as completed or failed. This doesn't happen often, but seems to have happened twice now.
-
4 hours ago, DaClownie said:
Are you encoding multiple files at once? Lowering mine to a single worker dropped my CPU usage significantly. Also, I found there was absolutely no speed boost in encoding speed. 3 workers took 3x as long, so same exact speed in the end. Just higher wattage from the wall according to my UPS.
Stupid question but did you test it with only 2? Dont the commerical cards have a 2 stream limit unless you use a workaround? Wonder if going over the limit would slow down the entire process on the 2 left on the gpu
-
5 minutes ago, saarg said:
You can check which module is loaded for the 1660 with lspci -k.
There have been others with a 1660 that have had issues getting the card recognised. Might be a driver version issue.
I'll check that out in a minute. Ran lspci -v and saw it was still being stubbed. Turns out while most of the components ended in 10d<letter> there was another one still stubbed that I thought was from the wireless card I had stubbed. Servers rebooting now.
*EDIT* Yeah jumped the gun. Its showing up now that i removed the 4th stub item that was hanging behind
-
Hi All, Just recently installed this (the 6.8.3 nvidia build) for the first time and I'm getting the "NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. " error. I have two cards, the first is a GT 240 for console access and wouldn't expect to show up, but the second card is a 1660 GTX. I previously used the card for gpu passthrough but its used far and few so I'd rather repurpose it. I removed the stub on the card and have disabled the VM manager. After rebooting I'm still not seeing the card show up in the Nvida Build settings. Is there anything else I need to disable besides the stub and the vm manager? I believe its still in the XML for the VM however I would assume with the VM manager disabled it shouldn't be holding on to the card still no?
Any help is appreciated!
Thanks,
~chiefo
-
I love how easy it is to find and add new apps and dockers. I'd like to see multiple user support in the web gui in 2020.
-
Looking for some advice. Been using telegraf and influxdb to keep stats on my unraid server for around 10 months now. I've noticed that the CPU and Ram usage of have climbed quite a bit.

Is this kind of growth typical for just using telegraf on one server? Is there any kind of trimming or optimizing that should be done to keep the usage down? The entire db is only ~3gb.


 If its image based subs instead of text based it will fail. Mine also retry the same failures when it reopens.
If its image based subs instead of text based it will fail. Mine also retry the same failures when it reopens.




[Support] Linuxserver.io - Plex Media Server
in Docker Containers
Posted
Just got the same issue in 6.12.8. Even though the transcode mount is optional, it seems with the latest version of docker included with the new unraid tries to put a : in for a blank variable in the template. If you delete the optional variables like /transcode in the template, it will start correctly.