

glennv
-
Posts
299 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by glennv
-
-
Great stuff !!!
-
so minimum 2 weeks then ✌️😜
-
Dear and wonderfull devs. When can we expect the RC3 ?
As since i moved to RC2 from 6.8 , none of my (SATA) drives (via LSI cards) are going into standby anymore whatever i do. Aparently a known bug so i was waiting patiently. But i am building a bigger and bigger power bill as we speak since a while now. Cant move back as this release is the very first in the history of the galaxy that finaly properly fixed my AMD reset bug. So am eagerly awaiting the standby fix in RC3.
-
Yeah i installed RC2 2 days ago and since then zero spindowns ( i am monitoring it with splunk so was an easy spot). All SATA btw.
Apparently fixed in RC3 so we wil wait.
-
No worries. Got it
")
-
Sorry but could not resist laughing a bit about the NFS outdated comment.
I beg to differ. Millions of servers in datacenters around the world rely totaly on it.
Including the multi billion dollar company's i am working with running insane fast NFS attached storage clusters to run their entire enterprise systems on.
Old yes, ideal surely not, outdated , absolutely not and there to stay for a while. It does require skill to tune for specific workloads and get it all right for sure.
-
@Tucubanito07 Nope , you can like i have use a large SSD based cache and set your share(s) to cache=yes/only.
Then after the initial memory cache the writes go to the fast ssd's (or nvme's Like Johnnie has) .
You can then at a convenient time uffload to spindels (mover) or keep in in the cache, whatever suits your workflow
-
I am not sure why we are even discussion yuor code when you clearly state that the same dir list calls are much slower on the new release then on the old. If its a slow call due to large directory , fine, so be it, but then it should be just as slow in the new release.
I see similar issue on my OsX cllients and on top of that read performace has dropped about 200+MB/s over my 10G with the only difference beeing an upgrade or downgrade so also moved back. There is definately something there that affects some but clearly not all people.
When you do the exact same thing and the only difference is the release we should focus on what has changed that can cause the changed behavior and not questioning the code other then in its great capability to identify a weakspot that was not there before.
-
@johnnie.black I hear you. But for me its not and its consistent and repeatable. I upgrade i drop big performance , i downgrade, all back to speed.
Just looking for the factor at play.
edit : just did the test copy to ramdisk and same results as capped at around 500MB/s, so its capped at the source for me not the target.
Same test on 6.7.2 full speed (850+ MB/s over the 10Gb connection)
edit 2 : i am osx only systems so maybe it only affects osx. Or just my system. But as i also see a speeddrop doing a test purely on the server itself , i doubt its a windows/mac thing.
edit 3: what i also noticed and at first thought is was just cooincidence (untill i read another user with something similar and rechecked) but browsing directories on the smb was much snappier on previuos release.
Just moved back again and feels like a breeze. Staying there . Getting tired of moving back and forwards with every time the same results whatever test i do. So i will sit it out a few releases and hope things improve. Am happy at current release and not missing any features on this already amazing unraid setup.
-
ouch.... Not much fun.
p.s. Only if you test via /mnt/user/XX you will test the fuse filesystem overhead. All other incl unassigned devices will bypass and do direct i/o. I have all my appdata/vm's etc on unassigned devices (on zfs) and these do not experience any speed issue as not connected to the array and fuse filesystem driver. The cache is part of the array and if accessed via /mnt/user (with share set to cache=yes or like in my case to only ) it uses the fuse filesystem driver . A virtual userspace filesystem. If you access it via /mnt/cache or directly via drive id etc , you bypass it hence the faster speeds.
-
So upgraded again to do the tests again (at 128k) and effect not as extreme as the 8k tests but still a considerable difference also showing up in the real world BM speedtest.
6.7.2
Local :
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd if=/dev/zero of=testfile.tmp bs=128k count=125000
16384000000 bytes (16 GB, 15 GiB) copied, 33.1774 s, 494 MB/s
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd of=/dev/zero if=testfile.tmp bs=128k count=125000
16384000000 bytes (16 GB, 15 GiB) copied, 9.76896 s, 1.7 GB/s
Over 10G from client more real world test
6.8rc9
Local
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd if=/dev/zero of=testfile.tmp bs=128k count=125000
16384000000 bytes (16 GB, 15 GiB) copied, 36.897 s, 444 MB/s
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd of=/dev/zero if=testfile.tmp bs=128k count=125000
16384000000 bytes (16 GB, 15 GiB) copied, 11.6999 s, 1.4 GB/s
Over 10G from client more real world test
in case it helps the diags (made on rc9):
tach-unraid-diagnostics-20191207-2258.zip
My educated guess that this is the change that is involved here. But could be soething completely different of course as lots of stuff has changed. But as the kernel is the same , we have to look at these things
-----
User Share File System (shfs) changes:
Integrated FUSE-3 - This should increase performance of User Share File System.
------
-
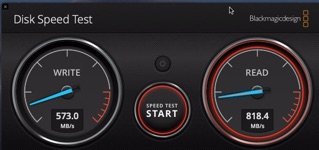
True and you are totaly right there. 128k gives write speeds more in line with the Blackmagic test (which is the one i look at mostly, as focused and my type of workload) of ~500MB/s writes and also less peaky / bumpy. So write is not a big issue and similar between releases. (although still about 100MB/s less in real world filecopies/writes)
I just did the dd test to see if anything stuck why my 10G network read speed was capped at around 500MB/s read when comparing between releases and what stuck out in the dd. Which coming entirely from cache in memory was a good indicator for if there was another bottleneck limiting my 10GB network speed. And there it was. Read speed was capped artificialy at 500MB/s while on 6.7.2 it hits 1.6GB/s hence also over the network the uncapped close to linespeed results.
So i am ignoring the dd tests for its absolute numbers, more as a bottleneck finder.
And if they agree with other more realistic tests, like BM test and normal file copies etc , its something to look at.
Completely repeatable , 6.8rc9 gives me 200 to 300 MB/s less read speed (800MB/s vs 500MB/s) over the net (SMB3) or even 1GB/s less local in the same exact test between releases (when cached in mem 1.6GB/s vs 500MB/s) and about 100MB/s less write spead, local and over ether.
edit: upgrading again to do the same comparison at 128k . Just in case.
-
Interesting. After rolling back as expected smb3 read speed back to 800+ MB/s.
Interestinglyu enough the artificial dd tests like i did on 6.8rc9 show the same slow write speed and crazy write curve stop start behavior (maybe its my btrfs samsung misalignement thing) but as i only need fast read speed (editing/color grading straight from cache ) i did not even notice. BUT more importantly for th erelease comparison, the read speed is not capped anymore to 500MB/s as you see in the 6.8rc9 test before but 1.6GB/s (as from memory so as it should be)
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd if=/dev/zero of=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 50.8538 s, 201 MB/s
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd of=/dev/zero if=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 6.24655 s, 1.6 GB/s <<<<<<<<<<<<<<<Back to business at least
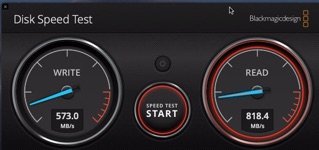
And in case you wondering , real world tests are in line with the artifical tests.
Copy a file from the unraid servers cache to local storage does the same. So capped and slow on rc9 and full speed 600-800MB/s file copies on 6.7.2.
6.8 i not for me....
-
Hmm, looks indeed like the fuse driver. Even a synthetic test goes insane on /mnt/user/SHARE vs /mnt/cache/SHARE. Reading from memory cache (as zero drive read activity and 128G mem) capped at 500MB/s which matches the speed i saw over the network. Write behavior is crazy with stops/spikes compared to a straght burst when writing to /mnt/cache. See attched image. Thinking about rolling back and forgeting about 6.8.
root@TACH-UNRAID:/mnt/user/SAN-FCP# cd /mnt/cache/SAN-FCP/
root@TACH-UNRAID:/mnt/cache/SAN-FCP# time dd if=/dev/zero of=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 9.74445 s, 1.1 GB/s
root@TACH-UNRAID:/mnt/cache/SAN-FCP# time dd of=/dev/zero if=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 2.88004 s, 3.6 GB/s
root@TACH-UNRAID:/mnt/cache/SAN-FCP# cd /mnt/user/SAN-FCP
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd if=/dev/zero of=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 77.2359 s, 133 MB/s
root@TACH-UNRAID:/mnt/user/SAN-FCP# time dd of=/dev/zero if=testfile.tmp bs=8k count=1250000
10240000000 bytes (10 GB, 9.5 GiB) copied, 19.1843 s, 534 MB/s <<<<<<<<<<<< ?????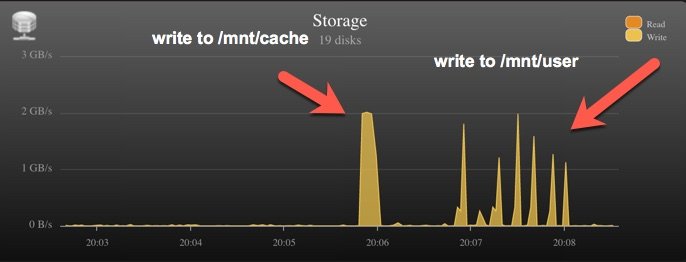
edit: rolling back now. Too much crazyness and i have no time for that. Too bad. Will try at some other point.
-
The new kernel was a problem as according to the release notes the ixgbe driver did not compile. Last i tried was rc3 and it was a mess for the 10g card. Super unstable speeds and 400MB/s less then normal.
The reason i tried again now is that its the older kernel and out of tree driver. Seems stable and all good only slower read speeds as before the upgrade.
So can live with it for a while but still wierd. But as other things have also changed that could affect this , like filesystem driver, maybe tunables , i am just wondering if there is something alse that could explain it.
Its the read part so straight from memory cache so should be super fast and close to linespeed as before the upgrade.
So it either the newer network driver for the card or some funky tunable that now comes into effect in this new release but just guessing.
Edit ; more convinced its not the network card driver as with iperf3 i can get 10G linespeed. So more looking at the changes related to the filesystem drivers , smb3 changes maybe or other stuff that has changed by the upgrade.
-
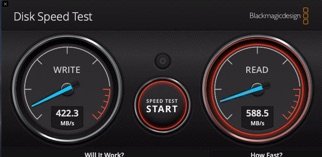
Hmmm. Interesting. Just upgraded and still intel 10g X540-AT2 read speed over smb(3) from raid10 3 drive ssd btrfs unraid cache from client 10g (same card) system dropped from :
6.7.2 : write ~500-600MB/s , read ~815MB/s
to
6.8rc9 : write ~417MB/s, read ~570MB/s
Nothing changed, just upgraded. Downgrade to 6.7.2 and speed restored.
Any ideas what could have caused that behavior ?
p.s. Measure with Blackmagic disk speed test.
-
What are the chances you think/see for the proper intel 10gbe drivers (ixgbe) to make it to the stable ?
The diff with the intree in performance is too big for me to move on unfortunately and would love to move to the new 6.8
edit : Sorry , ignore my question. Missed the whole story with rc8 and going back to old kernel. Saw in the rc8 annuoncement that ixgbe is back to out of tree drive. Jippieeee. Going to start testing again today as have been ignoring the rc's since my intells lost 300Mb/s on my last test in rc3.
Tnx guys ✌️
-
2 minutes ago, limetech said:
What do you mean here by "AMD reset bug"?
I thought that was clear by now . (or maybe i should have put "the effects of the bug" )
The bug whereby a passed thru AMD card causes a VM (at least in my case my OSX VM with Vega 56) only to be able to be started once. Will run fine indefinate, everything works, but then when you restart the VM , it hangs as "apparently" the AMD card does not get properly reset.
That was all before 6.8 rcx for me the case.
In 6.8 rc a patch was introduced to tackle this bug according to the change logs. For me it had the side affect of not just hanging the VM but paniking and hanging the complete Unraid server (see logs /screenshots etc). Consistently and repeatable.
Reverting back to 6.7.2 return it to normal buggy behavior of forementione AMD reset bug.
-
Are there any changes made that require a retest (as i see you changed the status) as i am now running 6.7.2 but willing to retest if something changed in the code ? Did not see anything related in the rc4 change log
-
Just saying. "Majorly interesting thread" and never thought about it. Have a dual socket xeon motherboards and interesting to see where this leads and how i can optimise vm memory useage this way myself.
Tnx for that
-
just fyi
For anyone with intel 10Gbe cards, the effect of the in-tree ixgbe driver in this rc build on network performance for me at least is .
Network works and is useable
- instable speeds (iperf is floating all over the place, while in 6.7.2 its locked tight to 10GB/s)
- average speedtest read speed using blackmagic speedtest from smb shared ssd raid10 cache drops from 850MB/s to around 500-550MB/s when moving from 6.7.2 to 6.8 rc3. Move back and speed is restored.
So i will wait it out (for more reasons but this is one of them)
-
16 hours ago, glennv said:
running an extensive mem test now anyway to prevent the inevitable questions if i ran a test and if i tried unplugging and replugging the server 😝
Wont hurt anyway.
about 16 hours later hammering 24cores (of 48) at memory sticks with latest downloaded memtest as totaly expected zero issues (other then large enegry bill).
-
ps fyi also took out all the other pcie devices (usb and 10g) from the xml to make sure and confirmed it is gpu related and not coming from any of these devices.
-
running an extensive mem test now anyway to prevent the inevitable questions if i ran a test and if i tried unplugging and replugging the server 😝
Wont hurt anyway.




Unraid OS version 6.10.0-rc3 available
-
-
-
-
-
in Prereleases
Posted · Edited by glennv
After upgrade to 6.10.0.rc3 (from rc2) i get error message on my qemu arguments to set rotational rate to 1 on my virtual drives (make the mac osx think they are ssd's)
These 3 entries for my 3 devices in my vm templates now give errors. When removed vm boots as normal . Did the syntax change ??
<qemu:arg value='-set'/>
<qemu:arg value='device.sata0-0-3.rotation_rate=1'/>
<qemu:arg value='-set'/>
<qemu:arg value='device.sata0-0-4.rotation_rate=1'/>
<qemu:arg value='-set'/>
<qemu:arg value='device.sata0-0-5.rotation_rate=1'/>
edit : rolled back to rc2 and all good again. Mainly because i also had a huuuuuge system lockup just now for the first time in more then a year (and within not even 1 hour on rc3) when rebooting this mac osx vm with amd gpu (maybe the amd reset bug plugin changed behavior also with rc3 , but not risking it . Safely back at stable rc2") .
.