




vw-kombi
Members
-
Joined
-
Last visited
Everything posted by vw-kombi
-
Seems a load of tidying up on the old unused docker xml files (assisted by AI) was needed for this. Todays upgrade went in fine. AI commands to check all the cfg files and made some edits and deleted some.
-
Nope - I don't have any like that. I had on that pointed to a wg2 interface that no longer existed, bit that is cleaned up with all the other work I did above.
-
I asked AI about all this and he said there were some issues with the xml's in my config. These has some old config it said (eth0 etc), so I deleted them all. The log suggested (it said) an issue with the Firefox container, so that was deleted, plus its cfg/bak files too. I have a large cleanup of all the very old xml files and only ones that match a running container are there now. While on that topic, I also got it to verify the Mac addresses with this command - for file in /boot/config/plugins/dockerMan/templates-user/*.xml; do \ if grep -qE "<Network>br0(\.[0-9]+)?</Network>" "$file"; then \ name=$(grep -Po '(?<=<Name>)[^<]+' "$file"); \ mac=$(grep -Po '(?<=--mac-address=)[^ <"]+' "$file" || echo "⚠️ MISSING MAC ADDRESS"); \ echo -e "Container: $name\n -> MAC: $mac\n"; \ fi; \ It also suggested I should stop docker, delete the docker file, then re-create it and then re-create all my containers, as a final check - but that seems like a way overkill and you would frighten people off if that was a 'normal' instruction.
-
It seemed to be stuck in some sort of docker start loop. Looked like they are starting, as in they were all seen, and some say starting, then it all seems to crash, It says Docker Services could not be started, then it repeats all that. Everything else seems to be ok. Drives were good, both my bfs drives (cache and cache-nvme) looked right. I through I did everything beforehand to remove and risks - 1 - Waiting a reasonable time. 2 - Checked the reports from others 3 - I am macvlan, with hardcoded IP addresses in my br0 network, so added the mac's to each of these in the extra parameters 4 - flas backup 5 - updated all dockers and plugins also my other backup unraid system went to this with no issues. Luckily, the rollback from the gui works (have to re-save a few containers to get them to start however). so the flash backup was not needed. Diags attached if anyone can help, and what can I do ahead for a successful re attempt. tower-diagnostics-20260619-1403.zip
-
There seems to by a need for this in Unraid, so why can't it get added to the OS natively ? I have it based on space invader recommendations a long while back when I implanted the bfs conversion and the sand bfs auto backups from his YouTube. Maybe @SpaceInvaderOne could do a you tube on the command line things needed to get the same functionality, then we can drop an unsupported plugin ?
-
I have this for a while - something 'hidden' had got into these values - needed to remove then and re-save.

-
I went back and did an AI search on the issue, and it seems the issue for me was that i had to just put some dummy data into the exclude folders setting. Even though there was nothing in there. It’s seems to be all back now.
-
I am in the latest non beta. I have a blank screen. Previously turning off lazy load and auto refresh brought it back, but I have not seen anything on there for a while now. Both my cache nvms’s and ssd’s are zfs. Daily I have zfs replication backups working of appdata. I can still use command line to restore one. Instructions for that setup from @SpaceInvaderOne . Just been a while since the zfs master has showed anything.
-
I thought this plugin was dead? Nothing shows on my screen for it since a few updates back. Versions 7 up I thought. Should I follow this up here as an issue I have? Is it supposed to work ?
-
as per OP - solved in
-
Just wanted to post that I got it back. Now sure which - or both, of these changed it - I turned OFF the auto refresh and turned off the lazy load :

-
I just came here to post the same. Just a blank page. I cant say I use it often, but I have never seen a blank page before. On the latest unraid version.
-
AI (specifically copilot but I guess they all know) - knew about this issue. It said there is no tailscale router back. It said to add this after I gave it all my ip and naming info - ip route add 100.64.0.0/10 dev tailscale1 And it worked - so I have added that to my startup. Hope this helps someone else! Transcript - Why LAN → container works, but Tailscale → container fails ✅ LAN traffic LAN devices send packets to 192.168.1.x → Unraid → wg1 container The container replies back to 192.168.1.x via Unraid → LAN Everything works. ❌ Tailscale traffic Your iPhone sends packets from 100.x.x.x → Tailscale → Unraid → wg1 container The container replies… but: • It has no route back to the 100.x.x.x subnet • So it sends the reply out the WireGuard VPN tunnel, not back to Unraid • Your iPhone never sees the reply This is why it looks like the container is unreachable, even though Unraid and LAN can reach it fine. The fix: Add a return route on Unraid for the Tailscale subnet You want Unraid to tell the container: “If you ever need to reply to a 100.x.x.x address, send it back through the Tailscale interface.” Your Tailscale subnet is always inside: 100.64.0.0/10 Your Tailscale interface is: tailscale1 ✅ Run this on Unraid: ip route add 100.64.0.0/10 dev tailscale1 This immediately fixes the return‑path problem.
-
Anyone with any ideas ? I feel it is a routing issue back from the containers configured to use the vpn tunnel. But I dont have the skills to know for sure. It is a pity - as @SpaceInvaderOne showed exactly this config in his latest video, and id like to use it for sonarr/radarr - but I need remote access to those. I can live without the nzbget/qbittorrent remote access - as they are the most in need of this vpn tunnel anyway.
-
I thought this may be related to another issue introduced by 7.2 with access to dockers not being allowed from a vlan. After more testing however, this is not the case. I can access another container that is NOT configured to route via wireguard from a VLAN. So where I am at now - remote iphone running tailscale can access 192.168.1.7 (unraid IP host) and get GUI, but cant access 192,168.1.7:6789 (nzbget docker routing via wg0). remote iphone running a wireguard client connecting to my router can access 192.168.1.7 (unraid IP host) and get GUI, but cant access 192,168.1.7:6789 (nzbget docker routing via wg0). I am just concentrating on one container now - as if I fix one, then the same fix will work on each. I came across this below case - and thought that may be it - adding the LAN subnet to the LAN_NETWORK key of the container, and my router wireguard network is 192.168.200.0 so I made this change - 192.168.1.0/24,192.168.200.0/24 but is still did not work. I am not sure what I should be put in in there for a tailscale test. Not sure is @SpaceInvaderOne reads these posts, but I imagine he needs /wants to acces these containers remotely, and I wonder how he does that ?
-
And here is an example of a container updated like this. Do I have to enable an advertised route to the docker network for this to work or something ?
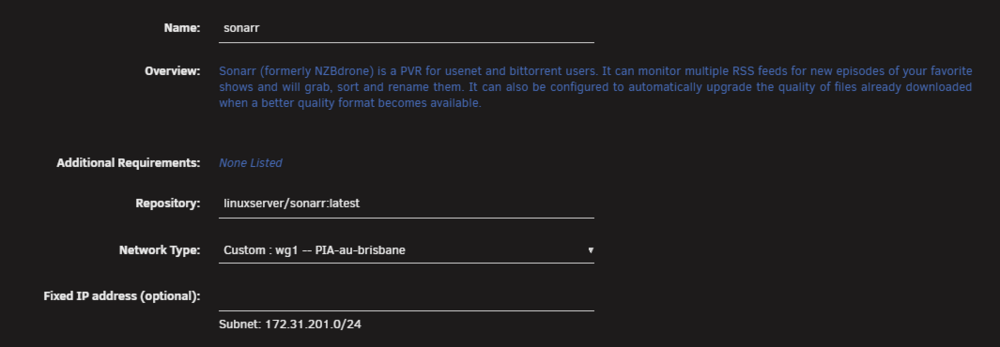
-
Some networking info for reference. Note, I created two wg tunnels out to two destinations (wg0 and wg1).
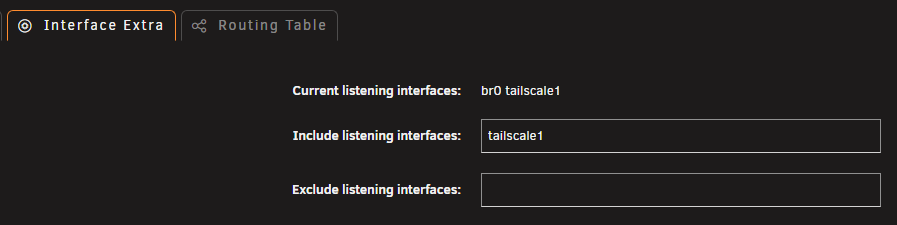
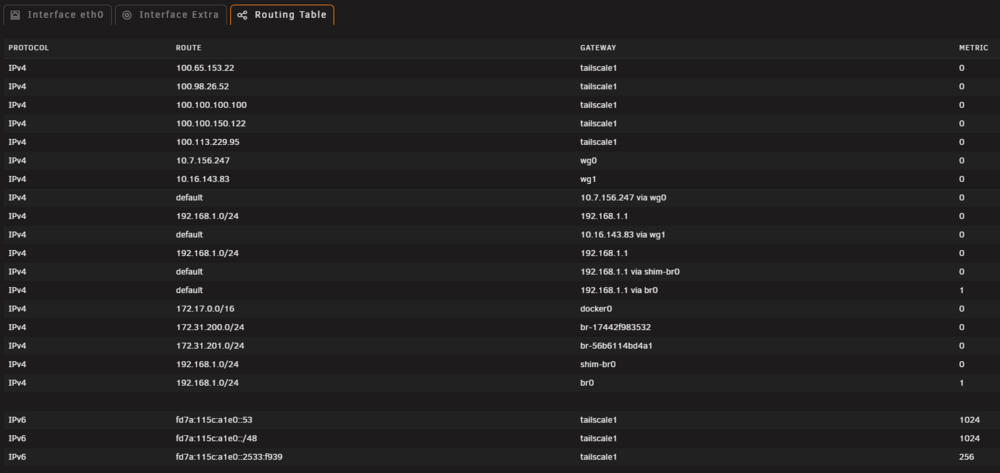
-
For background, I have configured almost all docker containers with a custom br0 network sing the same subnet of my unraid server (192.168.1.x) and each have own hardcoded IP addresses in this subnet, as I use unifi equipment and macvlan so I can get stats, allocate access from vlans etc etc. I just saw space invader one's youtube on connecting individual containers to a VPN - and thought that is a good way to go. So I configured all that, and changed the containers to use wg0, and wiped out the IP address - all working fine. I repeated for my other required containers - all also working fine. Then I went out, and had to access one remotely for some 'admin' so I did my usual thing - fired up tailscale on my iphone, went to the unraid logon, logged in, went to dockers, then clicked on the conianer, and clicked webui - and nothing. I tried a few direct links also - they dont work either. Then I tried the tailscale-IP-address/port - same issue. Seems I am missing something here when mixing wireguard and tailscale. For reference, unraid is latest release. using the built in tailscale. also - the tailscale IP address cant do it either - so there is some sort of routing issue inbound from tailscale and into the docker network when using the wireguard connection to the VPM. Any ideas ?
-
Success........ I did an ifconfig -a and there is an interface called shim-br0. For fun and giggles, I added this interface to the containers. And there you go - they all come up. also netAlertX works too.....
-
Further to this, netalertX container has the same issue - no containers can be found but all else is. Basically, a container setup with host networking CANNOT see other containers on br0.
-
You misunderstood - It IS reading all the VLANs on BR10,20,30,40 etc. And all devices on br0 It just cant read any other containers. The arp strings for the vlans are : arp-scan -gNx 10.10.10.0/24 -Q 10 -I br0.10 arp-scan -gNx 10.10.20.0/24 -Q 20 -I br0.20 arp-scan -gNx 10.10.30.0/24 -Q 30 -I br0.30 arp-scan -gNx 10.10.40.0/24 -Q 40 -I br0.40 And the interfaces it is setup to look for are br0. It finds everything except the other containers. I can pass in extra arguments for arp-scan, but I dont know what exactly may help there. By default, it does this - arp-scan -glNx -I br0 and if I run that in the container console, it indeed only finds the other stuff - just not containers.
-
To clarify. The docker container is called WatchYourLan. My unraid server is configured with vlans - and this container can see all the vlans and the devices (br0.10, br0.20, br0.30 etc). This container can also see all other devices on br0 (unraid server, and the devices on 192.168.1.10/24) But - This container cannot see the other docker containers that are using br0 and have IP addresses set in the 192.168.1.0/24 range. The container config states it must be run as Host networking. If I set it to Bridge or br0-LAN (with an IP), then it does not start. I also have host access to container allowed.To clarify.
-
Throw back - I have had to turn on bridging in the network settings for a different issue with my VM's, as I had to edit one to add insert an OS DVD ISO, and after saving and restarting, then IP address was in the 192.168.1.122 range. Some googling said I have to change the interface to br0 for the VM's, so I activated bridging again in the network settings. Now I have lost viability to the vhost0 interface where all the docker containers were showing in watchyourlan. Still not managed to find them. I am monitoring br0 but they dont show there.
-
Never mind, through trial and error using my backup unraid server I got this working. In case it helps anyone else : 1 - No need to enable bridging 2 - turned on vlans in network settings, and added 4 (vlan10, 10, vlan20, 20, vlan30, 30, vlan40, 40, all these I left NONE for the IP4 address assignment (as I did not want the vlans to talk back to unraid host). 3 - enabled the vlans on the port used by the unraid server (in unify terms, changed to allow all instead of block all). 4 - in netstat -i, this shows then as etho0.10, eth0.20, eth0.30 and eth0.40. 5 - I added these interfaces to the watchyourlan container and this can now see the vlans.
-
If I cant get an answer to this query, maybe cant I ask - Is bridging now fully supported for the macvlan option ? I need macvlan as I use unifi networking stuff.





