

Kaizac
-
Posts
470 -
Joined
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Kaizac
-
-
3 minutes ago, adgilcan said:
My PlexMediaServer seems to have developed a fault.
I haven't used it for about 5 months and I am getting the attached message whenever I try to open my media on it. I am running v6.9.2 of UnRaid. Any ideas?
Thanks
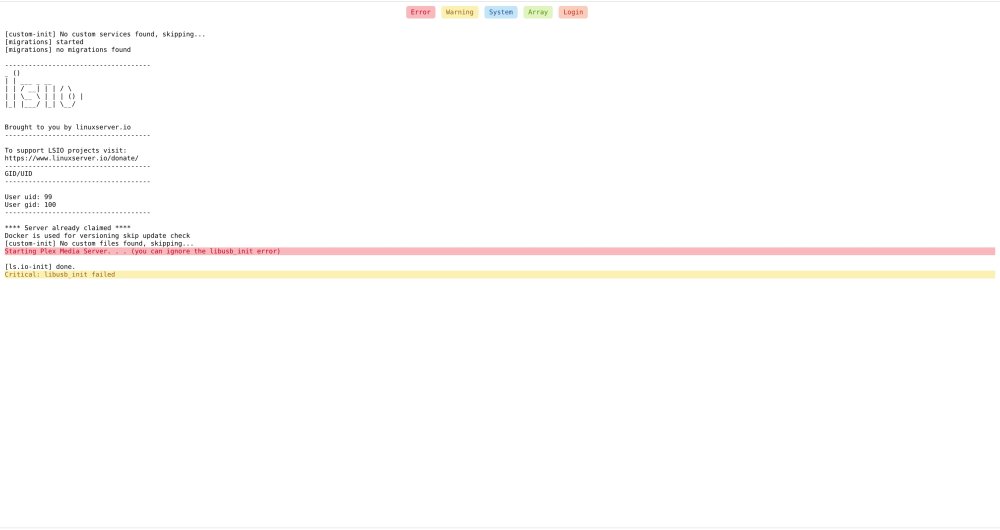
It literally says in the log just below it that you don't have to worry about the error given. 🤣
-
38 minutes ago, martikainen said:
I've been trying to find an answer to this but the unraid forum search engine isn't treating me well

What folder should i point my downloads to in deluge if i want to upload it to gdrive and continue syncing there? Or is that not an option?
mnt/user/local gets uploaded to the cloud.
mnt/user/mount_rclone is the cloudfiles mounted locally.
mnt/user/mount_mergergfs is a merge of both, mapped in plex/sonarr/etc.
But I cant download to mount_mergerfs right? Then the files wont be uploaded? or?
The only folder you need to work with is mount_mergerfs for all your mappings. So you download to mount_mergerfs and then at first it will be placed on your local folder. From there the upload script will move them to the cloud folder. So it basically migrates from user/local to user/mount_rclone, but while using rclone to prevent file corruption and such. The folder mount_mergerfs won't see a difference, it will just show the files but not care about its location.
With Deluge and Torrents generally this setup is a bit more tricky. Seeding from Google Drive is pretty much impossible, you will get API banned quickly and then your mount work until the reset (often midnight or 24h). So you'll have to seed from your local drive, which means you need to prevent these files from being uploaded. You can do that based on age of the files, or you can use a separate folder for your seed files and add that folder into your mount_mergerfs folder. Then after you have seeded them enough you can put them in your local folder to be uploaded.
I don't have much experience with Torrents, DZMM had a setup with it though. Maybe he knows some tricks, but the most important thing to realise is that seeding from your Google Drive will not work.
-
1 hour ago, francrouge said:
Hi
Just to let you know that i tried what you told me on my main and backup server and it seem to be working permission owner where changed to nobody:users
thx alot
That's good news! Hope it will stay working trouble free for you ;).
-
 1
1
-
-
2 minutes ago, francrouge said:
cool thx i will try thx a lot
Should it be faster just to delete mount folder directly with no script load up and let the script create it again 🤔
Ah, I forgot, also the mount_mergerfs or mount_unionfs folder should be fixed with permissions.
I don't know whether the problem lies with the script of DZMM. I think the script creates the union/merger folders as root, which causes the problem. So I just kept my union/merger folders and also fixed those permissions. But maybe letting the script recreate them will fix it. You can test it with a simple mount script to see the difference, of course.
It's sometimes difficult to advise for me, because I'm not using the mount script from DZMM but my own one, so it's easier to for me to troubleshoot my own system.
-
1
-
-
12 minutes ago, francrouge said:
Here is my folder
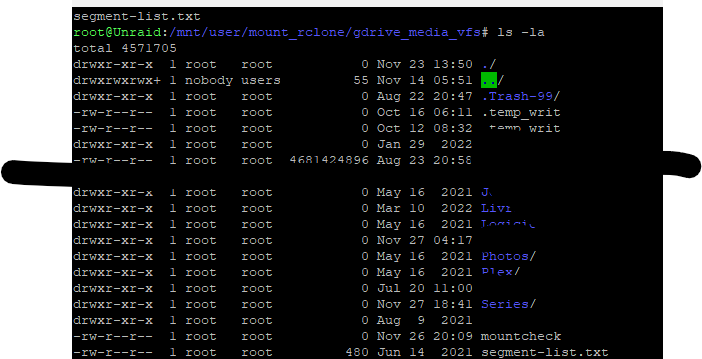
What should i do ?
thx
Well, we've discussed this a couple of times already in this topic, and it seems there is not one fix for everyone.
What I've done is added to my mount script:
--uid 99
--gid 100
For --umask I use 002 (I think DZMM uses 000 which is allowing read and write to everyone and which I find too insecure. But that's your own decision.
I've rebooted my server without the mount script active, so just a plain boot without mounting. Then I ran the fix permissions on both my mount_rclone and local folders. Then you can check again whether the permissions of these folders are properly set. If that is the case, you can run the mount script. And then check again.
After I did this once, I never had the issue again.
-
1
-
 1
1
-
-
On 11/27/2022 at 11:00 PM, crankyCowboy said:
Oh sorry, I should have been more clear. My database is corrupt and going that route doesn't work. I was just going to let Plex rebuild by database and re-add my libraries. All my metadata will still be there so it shouldn't take long. I was just trying to extract the watch history from the database using this article: https://support.plex.tv/articles/201154527-move-viewstate-ratings-from-one-install-to-another/
but as I said, the command above is giving me an error stating that sqlite isn't available.
Did you get further with this? Sqlite should be in the docker, but you can't just use the Plex commands, you'll have to convert them to suit Linux/Linuxserver docker. That's why I gave you the references to how they translate from the Plex wiki to the actual functioning commands.
Otherwise, maybe someone on reddit will be able to "translate" them for you. But why don't you just restore a backup? I did all this script shit before and nothing worked. Then just plunked back a backup and ran the update of libraries, and it was good again. You'll miss a bit of your watched data depending on how recent your backup is, but there is no guarantee you will be able to extract non-corrupted metadata either.
-
8 hours ago, francrouge said:
@DZMMHi
Can you tell me in you're script what user should the script put folders
like root or nobody
My folder got root permission and it seem to glitch a lot with the script normal ?
thx
Shouldn't be root, this caused problems. It should be:
user: nobody
group: users
Often this is 99/100.
-
1 hour ago, ingeborgdot said:
I tried using my custom network, but I get a message on my new tab that says about:blank#blocked. When I change network type to host, it seems to work. I don't know if bridge is an option??? I'm kind of lost here. I have not found anything that helps me with the initial set up of the linuxserver. I'm sure there is something someplace, I just haven't found it yet.
I don't know how you set up your Unraid box, and whether you put in the custom network (VLAN) properly. Bridge is always an option, as long as the ports used a free on your Unraid box. I'm not a fan of using bridge, but it should at least work when using free ports.
You can also use custom:br0 so it will get an IP of your LAN.
2 hours ago, crankyCowboy said:@Kaizac Thanks! That worked, but now I have a separate problem. I guess sqlite isn't in my db directory. I'm trying to run this command:
echo ".dump metadata_item_settings" | sqlite3 com.plexapp.plugins.library.db | grep -v TABLE | grep -v INDEX > settings.sqlbut I'm getting this error:
bash: sqlite3: command not foundDo I need to go to the location of where sqlite3 is? If so, any idea where that is within the plex folders?
I'm not familiar with the command you are using. Maybe this can be some reference for you?
Plex has the following article:
https://support.plex.tv/articles/repair-a-corrupted-database/
Commands there transfer to this for the linuxserver docker:
First cd to:
cd "/config/Library/Application Support/Plex Media Server/Plug-in Support/Databases/" "/usr/lib/plexmediaserver/Plex Media Server" --sqlite com.plexapp.plugins.library.db "PRAGMA integrity_check" "/usr/lib/plexmediaserver/Plex Media Server" --sqlite com.plexapp.plugins.library.db "VACUUM" "/usr/lib/plexmediaserver/Plex Media Server" --sqlite com.plexapp.plugins.library.db "REINDEX" "/usr/lib/plexmediaserver/Plex Media Server" --sqlite com.plexapp.plugins.library.db ".output db-recover.sqlite" ".recover" "/usr/lib/plexmediaserver/Plex Media Server" --sqlite com.plexapp.plugins.library.db ".read db-recover.sqlite" chown abc:users com.plexapp.plugins.library.db -
3 minutes ago, ingeborgdot said:
And the linuxserver is the one I'm choosing.
Since I'm running my sonarr and radarr on a custom network, do I need to run Plex on the same custom network? I haven't seen anything on this yet. It may be out there, but I haven't found it. Thanks.
No you don't, just make sure your firewall is set up to allow communication if needed (for example, to ping Plex from Sonarr/Radarr when you have new grabs).
-
50 minutes ago, crankyCowboy said:
whew, that actually makes me feel better. i had used that method a couple months ago and didn't get that error, so i was pretty sure I wasn't doing something wrong. thank you!
Ok this was a learning curve for me, but I think I found it (for me it worked to down the plex service and up it again).
cd /var/run/s6-rc/servicedirs/s6-svc -d svc-plexHope it helps.
25 minutes ago, ingeborgdot said:So, support here is better than at the Plex forum?? Does the linuxserver work as well with plexpass? Sorry for the questions, I'm just a week into unRAID, and want to make sure I do it all right. It's no fun having to start over. Best to do it right the first time.
Thanks.
Everything is better than the support at the Plex forums to be honest... Almost everyone on Unraid is using the linuxservers dockers, so you have more people with similar setups and possible issues. And the linuxserver team is always on top of things, which makes it easier to differentiate between docker issues and Plex issues.
Linuxserver also works with the Plexpass. Just have to use the right variables when settings up the docker. Read the linuxserver instruction for Plex before installing, and you should be good.
-
14 minutes ago, crankyCowboy said:
Yes, that's correct. I'm on the latest version of the Linux Plex server docker. I'm guessing by your response, that you are perplexed as to why I'm getting that error as well? I tried restarting the container and trying again and I'm getting the same error. Any other suggestions? Thanks for the help, by the way.
I just checked and I get the same error. Seems like they moved the location within the docker. I will see if I can find the new location.
-
16 minutes ago, crankyCowboy said:
Sorry @Kaizac, I should have clarified that. Yes, I did.
And you're using the Linux server docker and not another one?
-
12 minutes ago, crankyCowboy said:
I have a corrupt database and need to stop the service, but not the container. I was told that I could enter this:
cd /var/run/s6/servicesand then enter this:
s6-svc -d plexbut after that second command, I get this error:
My database is not repairable (but plex is still working fine). but nightly I get a "database is corrupt" error when a backup is created. I was going to extract my "watched" data etc and recreate the libraries and database etc. but can't stop the service to use sqlite. any help would be appreciated.
Did you run the commands from the Plex docker terminal?
-
23 minutes ago, robinh said:
The release on the github is from april indeed but the docker is pulling the master which is recently updated ( 4 days ago).
Just checked with a reboot and the script is currently pulling the 2.33.5. So right now no issues with using this script as far as I can tell. Thanks for the heads up, in case the bug prevails in the next release we know to switch back!
-
On 11/13/2022 at 4:16 PM, robinh said:
Be aware that there seems to be a bug in the latest version of mergerfs on the github page.
I've noticed it after I did reboot my unraid machine and afterwards the mergerfs was crashing everytime.The crashes did occur after write events.
In my dmesg logging:
[ 467.808897] mergerfs[7466]: segfault at 0 ip 0000000000000000 sp 0000147fb0e0e1a8 error 14
[ 467.808921] Code: Unable to access opcode bytes at RIP 0xffffffffffffffd6.The only way to get the mounts working again was using the unmount and mounting script, but as soon there was a write event the issue occured directly again (0 kb written files).
I've temporary solved it by edditing the mergerfs-static-build image so it wouldn't pull the latest version of mergerfs from github.
Instead I'm using now the 'd1762b2bac67fbd076d4cca0ffb2b81f91933f63' version from 7 aug.And that seems to be working again after copying the mergerfs to /bin 🙂
Not working mergerfs version is:
mergerfs version: 2.33.5-22-g629806e
Working version is:
mergerfs version: 2.33.5
Just checked the github and it still shows 2.33.5 from april in releases. So what is the august one you are referring to?
-
14 minutes ago, robinh said:
Are you sure the mount script is not using docker to build the mergerfs? and then place the compiled version to /bin on your host?
in the posted examples in this topic you see the following happening in the mount script.
Maybe you were not aware it was using docker to build the mergerfs file.# Build mergerfs binary echo "$(date "+%d.%m.%Y %T") INFO: Mergerfs not installed - installing now." mkdir -p /mnt/user/appdata/other/rclone/mergerfs docker run -v /mnt/user/appdata/other/rclone/mergerfs:/build --rm trapexit/mergerfs-static-build mv /mnt/user/appdata/other/rclone/mergerfs/mergerfs /binIt's being build as a docker yes. You can see the mergerfs docker often in your deleted dockers. Will have to find the correct syntax to get the working mergerfs if this issue persists.
-
5 hours ago, Bjur said:
Thanks for the info.
I'm running Unraid in a VMware host with i5-9600K 32 GB memory where 16 GB are allocated to Unraid.
How much should there be then?
Ps. I wasn't even uploading, just normal playback where it stopped when I skipped back.
I run 64GB ram and have 30% constantly used. Doesn't mean you also need that, but 16GB is not a lot. You have to remember that while doing playback all the chunks are stored in your RAM if you are not using VFS cache. And if you have Plex also transcoding in RAM it will also consume. So I would lower the chunk sizes in both upload as mount scripts.
1 hour ago, Paff said:Hi all, I would be interested to know how the rclone mount is updated. I have the problem that I always have to restart the server to see the current files. Since after files are uploaded, they are deleted locally and thus unavailable until I restart the server. Do you use a routine once a week? Which updates the RClone mount? Thanks in advance for your help.
BR Paff
This is an issue you should not have when you followed the instructions. You are missing files because you are not using mergerfs. For me files don't dissapear ever, because it doesn't matter if the files move from local to cloud.
-
10 hours ago, Bjur said:
In regards to why I'm loosing my share from time to time, I get this error:
Oct 31 22:39:45 Unraid kernel: [ 18010] 0 18010 16976 2511 110592 0 0 notify
Oct 31 22:39:45 Unraid kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=rcloneorig,pid=6284,uid=0
Oct 31 22:39:45 Unraid kernel: Out of memory: Killed process 6284 (rcloneorig) total-vm:13626112kB, anon-rss:12490308kB, file-rss:4kB, shmem-rss:35408kB, UID:0 pgtables:25380kB oom_score_adj:0
That's what I expected to be the cause, you don't have enough RAM in your server. If you start uploading it will consume a lot of RAM. So you could look at the upload script and check the seperate flags and reduce the ones that use your RAM. When I have my mounts running and uploads it will often take a lot of my quite beefy server.
-
25 minutes ago, DZMM said:
Until my recent issues with something in one of my 10 rclone mounts + mergerfs mount dropping, I wasn't tempted to move to Dropbox as my setup was fine. If union works, although the tdrives are there in the background, I'll have just one mount.
How would you move all your files to Dropbox if you did move - rclone server side transfer?Don't think server side copy works like that. It just works on the same remote and moving a file/folder within that 1 remote.
So it will probably just end up being a 24/7 sync job for a month. Or maybe get a 10GB VPS and run rclone from there for the one time sync/migration. Problem mostly is the 10TB (if they didn't lower it by now) download limit per day. I'm not sure about the move yet though. I also use the workspace for e-mail, my business and such, so it has it's uses. But them not being clear about the plans and what is and isn't allowed is just annoying and a liability on the long run.
18 minutes ago, DZMM said:Ok, ditching again - the performance is too slow. It's been running for an hour and it still won't play anything without buffering. Maybe union doesn't use VFS - dunno.
I might have to go with dropbox as my problem is definitely from the number of tdrives I have - 10 for my media, 3 for my backup files, and a couple of others. Unless I can find out if it's e.g. an unraid number of connections issue.Didn't we start with unionfs? And I think we only started to use VFS after we got mergerfs available. So that could be the explanation of your performance issue during your test.
I wonder if there are other ways to combine multiple team drives to make it look like 1 remote and thus hopefully increasing performance for you. I'll have to think about that.
EDIT: Is your RAM not filling up? Or CPU maybe? Does "top" in your unraid terminal show high usage by rclone?
-
1 minute ago, DZMM said:
Playback is a bit slower so far, but I'm doing a lot of scanning - Plex, sonarr, radarr etc to add back all my files. Will see what it's like when it's finished
Interesting. I have like 6 mounts right now, but I did notice that Rclone is eating a lot off resources indeed, especially with uploads going on as well. So I'm curious what your performance will be when you're finished. Are you still using the VFS cache on the union as well?
Another thing I'm thinking about is just going with the Dropbox alternative. It is a bit more expensive, but we don't have the bullshit limitations of 400k files/folders per Tdrive. No upload and download limits. And just 1 mount to connect everything to. It only had api hits per minute which we have to account for.
And I can't shake the feeling of Google sunsetting unlimited any time soon for existing users as well.
-
6 minutes ago, DZMM said:
Experiment over - it got really slow when lots of scans / file access was going on
Thanks for testing it already, didn't have time to do it sooner. Disappointing results, would have been nice when we can fully rely on rclone. I wonder why the implementation seems so bad?
-
3 minutes ago, workermaster said:
I just contacted support. They told me that I could add another account to double the storage, or contact sales to see what they can offer me. They did not have an answer for me as to why the enterprise account says unlimited storage, but is only 5TB.
I am now looking at dropbox. They are quite a bit more expensive, but taking power consumption, drive costs and capacity in mind, it might be worth it. I am going to be trying the trial of Dropbox to see if streaming works well.
Dropbox should work fine, others have switched over to that. Just be aware that the trial is only 5TB. And when you do decide to use their service you should press on getting a good amount of storage beforehand, otherwise you will keep having to ask for more as well while migrating.
-
2 minutes ago, workermaster said:
I have started uploading and because I have an enterprise standard, I assumed that I have unlimited storage.
Google drive shows that I have a maximum of 5TB and I just got a mail telling me that if I exceed it, the files will become read only. Looking at the ways to increase the size, I see that I have to contact support and request more storage.
Does anyone else have to do this? Or is the 5TB limit not enforced?
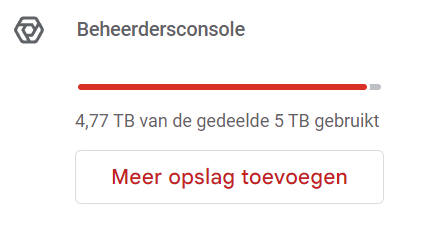

It's something Google recently started doing for new accounts. I've told you about this possibility earlier. You can ask for more but they will probably demand you buy 3 accounts first and then still have to explain and ask for more storage with increases of 5TB only.
Alternative is to use Dropbox unlimited which you need 3 accounts for as well but it's really unlimited with no daily upload limits. But it all depends on how much storage you need and your wallet.
-
38 minutes ago, workermaster said:
I cant figure out how to add them and what window you mean. I assume this window:
What I did (for testing) is instead of pointing the SA location in the previous post to the folder containing all 20 SA accounts, I now went a level deeper and gave it the path to the first SA account in that folder. It now points to:

Then created new upload and mount scripts, and now it has been uploading for half an hour at full speed. I hope this works and that it will change over to a new service account when it reaches the 750gb mark.
You're misunderstanding the way service accounts work. They function as regular accounts. So instead of using your mail account, you use a service account to create your mount. What I did is rename some of the service account files to the mount they represent. You can put them in a different folder. Like sa_gdrive_media.json for your media mount. So for this you will have to not put in the path to the folder with the service account, but to the exact folder. Which you did in your last post. By seperating this you will also not use these SA's for your upload script, seperating any potential API bans.
The upload script will pick the first of the service accounts. Then when it finishes because it hits the 750gb api limit it will stop. That's why you put it on a cron job so it will start again with service account 2 until that one hits the api limit. And so on.
Just so you understand, the script doesn't just keep running through all your service accounts. You will have to restart it through a cron job.
About moving your current folder to your teamdrive. It depends whether the files are encrypted the same as your new team drive mount. So with the same password and salt. If that is the case you can just drag the whole folder from your gdrive to your team drive from the Google Drive website. Saves a lot of time waiting for rclone transfers to finish. You can even do this to transfer to another account. The encryption has to be identical though.









[Support] Linuxserver.io - Plex Media Server
in Docker Containers
Posted
I responded earlier today to you, but somehow the forum didn't put it in the topic. It's probably because you haven't claimed your server yet. You can find more information about that in this topic and on the plex documentation.
If that doesn't solve it, let us know so we can troubleshoot.