

mbezzo
-
Posts
71 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by mbezzo
-
-
On 11/13/2019 at 8:21 AM, Warrentheo said:
Yah, I also have been looking into going this direction, was looking at a Crosshair VIII board, just need to know the IOMMU groups...
Hey, I've got that board (no wifi version) with a placeholder (3200G) CPU until I can track down a 3950x - only have Windows on it right now, but if you can tell me how to list the groups from Windows - happy to post em later!
-
yeah, I'm aware of the massive Nest changes - but none of them have hit yet. That's all happening later this year (and now they've sort of rescinded and are saying existing API use will not be disabled - you just can't make any new ones)
So... that doesn't quite explain it.
Curious if anyone else using this docker still has Nest working?
-
And while I'm at it, has anybody figured out how to configure the Homebridge docker to see the log from the Homebridge gui?
-
I've narrowed it down to the Nest plugin. No changes whatsoever related to my Nest config - anybody have any ideas? I've completely removed the docker/nuked its appdata folder and completely rebuilt. Same issue - if I remove nest it works great. WTF! lol
I've even issued a new api token!
Anybody hear of any issues with Nest? I can't seem to find much...
thanks all!
-
these are the 3 errors. the one from my OP just reads as text (not colored).
thanks!
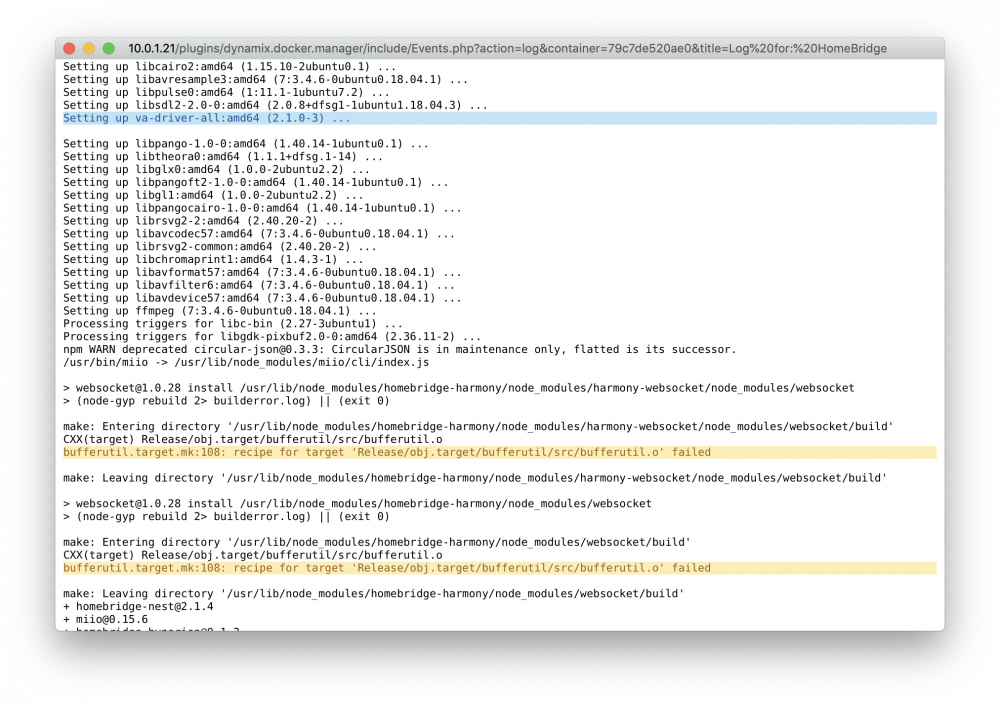
-
is this what you're looking for? the error would be the last line - takes awhile to show up so it's not in this one.
")
thanks!
-
I'm getting this after updating homebridge:
terminate called after throwing an instance of 'std::bad_alloc'
Any ideas?
Thanks!
-
and... it was a bad flash drive! Transferred the config folder and I'm all back up and running.
-
It's not coming back up after rebooting sadly. Not home at the moment, so can't see what's happening. Will update when I can see what's happening.
-
But now, I'm getting a bunch of errors and the array is offline. Just rebooted, but got some diags before I did. Anybody see anything interesting?
got a bunch of emails with this in it: /bin/sh: line 1: 25882 Bus error /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null
unraid-diagnostics-20190515-2106.zip
Thank you!
-
Thanks, @peteknot - shoulda looked there first!
Yup - just deleted/re-added (copied all my settings and re-entered them) and all is well.
Thanks again!
-
Hey all, just updated this evening to the latest release, and I'm getting this in my logs. Any ideas?
::: Starting docker specific setup for docker pihole/pihole WARNING Misconfigured DNS in /etc/resolv.conf: Two DNS servers are recommended, 127.0.0.1 and any backup server WARNING Misconfigured DNS in /etc/resolv.conf: Primary DNS should be 127.0.0.1 (found 127.0.0.11) nameserver 127.0.0.11It quickly just fails and stops after this error. Didn't have any issues with it prior to the update (and no config changes either).
-
 1
1
-
-
Well shoot... hahah. YUP! that did the trick.
Thank you!!!
Matt -
Hi All,
Just got a new 8TB drive, ran it through a preclear cycle without issue. Added it to array (Disk 9/sdj), and it shows up as needing to be formatted, check the box, hit format and after a few secs, it just pops back up as "Unmountable: Unsupported partition layout"
Any ideas? See attached logs.
Thank you!!
Matt
-
Hi All,
I've been trying to get the mastodon dockerhub docker running, but no luck. Anyone willing to unRAIDify this one?
https://hub.docker.com/r/tootsuite/mastodon/
https://github.com/tootsuite/documentation/blob/master/Running-Mastodon/Docker-Guide.md
Much appreciated!
Matt
-
 1
1
-
1
-
-
FWIW, I'd be interested in this too!
-
On 8/31/2018 at 5:38 PM, Tyler said:
I noticed something that could be the cause of your issue, in the Docker run command you posted in your GitHub issue that you've set the variable: 'INTERFACE'='br0'
I believe this variable needs to refer to the name of the container's internal interface which is 'eth0', rather than the name of UnRaid network interface the container is running on which in your case is 'br0'
@bonienl posted instructions a few pages back on how to re-configure this
If you haven't tried this already it might be worth giving this a shot
THANKS @Tyler! This did the trick for me. I can't quite remember if I changed that to br0 or not - seems like that was default... Appreciate the reply!
-
Thanks! And yes, the more the merrier to get this issue resolved
-
Submitted this if others with the issue want to add on/comment: https://github.com/pi-hole/docker-pi-hole/issues/321
-
Thanks, @spants - will do!
-
Glad to hear I'm not alone - I was really pulling my hair out on this one!
-
V4.0 works great for me for awhile, then it completely stops resolving DNS. I think it seems to be after the first reboot. Anybody else figure out how to fix this? If I nuke it all and reinstall - samething. Works great for awhile, then no DNS resolution...
-
3 minutes ago, John_M said:
There is a subtle difference between /mnt/user/appdata and /mnt/cache/appdata even when the share is set to cache only. The former is handled by shfs while the latter isn't. Hence Squid's suggestion to bypass shfs. I thought this issue had been fixed in the meantime, though.
Thanks, John - that's exactly the info I was looking for. The issue definitely seems to be much better in my case, but I've seen it several times over the past 1.5 months. It always recovers and usually never last for more than 10 mins. I'm going to try moving things to /mnt/cache and see how it goes.
Thanks again!
-
ah, okay that might make more sense then.
I was thinking that since I do have a cache drive, and appdata is set to cache only, that even though my paths are /mnt/user/appdata - it still is on the cache drive. aWhich is exactly why I didn't understand Squids suggestion. Hopefully that makes sense!
That being said, since mine are already on the cache drive - changing to /mnt/cache won't do much or me, will it?
Thanks!




Ryzen 9 3900X Question
in Motherboards and CPUs
Posted
Anybody have any fun updates to share on this? My CPU arrives today - will be dropping it in an ASUS ROG Crosshair VIII Hero. Would love to hear from anybody with this setup!
thanks!
Matt