
Xaero
-
Posts
413 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Xaero
-
[DEPRECATED] Linuxserver.io - Rutorrent
Xaero replied to linuxserver.io's topic in Docker Containers
I've been looking into this a bit. First; to the author of this docker: Are you aware that rtorrent is overwriting the log each startup? If it crashes and is respawned, the log file from the previous run is lost. I've tried using an exec near the beginning of the config file to move the log: execute = {sh,-c,mv /config/log/rtorrent/rtorrent.log /config/log/rtorrent/rtorrent.log.`ls /config/log/rtorrent/rtorrent.log* | wc -l`} This does successfully move the "old" log file prior to starting rtorrent. I'm finding that if I restart the container, rtorrent becomes deadlocked at 99.99% IOWAIT and is almost completely unresponsive (the UI does load and does update when I resize the window, so it's running still) If I then leave it idle it restarts 3 times, and then works more or less "fine" for several hours, before becoming stuck in IOWAIT again and then never respawning. The log files are very clean though: 1545632842 W Ignoring rtorrent.rc. 1545632842 N rtorrent main: Starting thread. 1545632842 N rtorrent scgi: Starting thread. So that tells us basically nothing. From there, I dug into what handles rtorrent has open. We know it's not waiting for disk resources since the disks are all responsive and the array is able to saturate gigabit readily. The queue depth also indicates that the disk itself isn't unresponsive or being thrashed. Here's where it gets interesting: https://paste.ubuntu.com/p/hKC4p4rCnN/ As you can see, it's opening an impressive number of sockets. I'm not sure if them being TCPv6 vs TCP is of any consequence, but most of my functional services are using IPv4 TCP connections. You can also see that none of the open sockets have functional endpoints, or size descriptors. I've tried with a fresh config, as well with the same behavior. Monitoring "lsof -a -p `pidof rtorrent` | wc -l" shows anywhere from ~1200 to more than 4000(!) open handles. This is clearly the problem, but I don't understand why this behavior is occurring. I don't think this docker is inherently at fault, though. EDIT: The fix was to enable ipv6 Prefix Delegation on my router. Most consumer routers should have this enabled by default. After enabling prefix delegation the issue has been resolved and the handles open correctly with actual endpoints. Good to know. -
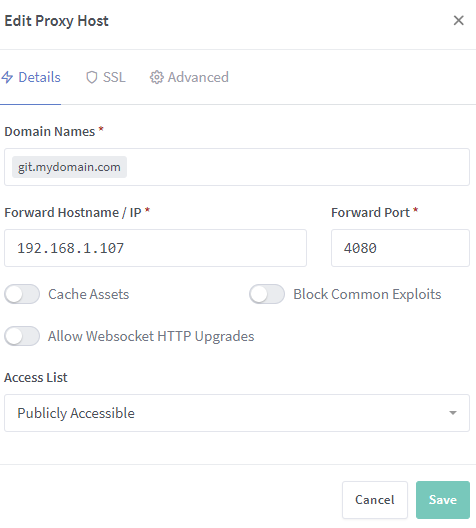
Trying to get this to work with gitlab-ce. Having basically zero luck. I'm super new to nginx and proxying different services to the web using it, was hoping a GUI would ease the learning curve. So, for configuration in Nginx-Proxy-Manager I have this: And I have it set to generate a new SSL certificate using LE, and force SSL. From there, I've set gitlab-ce docker with the following extra options: external_url 'https://git.mydomain.com/'; gitlab_rails['gitlab_ssh_host']='git.mydomain.com'; nginx['hsts_max_age'] = 0; nginx['listen_port'] = 4080; nginx['listen_https'] = false; (I've taken the liberty of placing these on newlines for readability) First I receive the same error as the above user - but refreshing the page shows that the entry was created, and the SSL certificate is shown on the certs tab. But when I attempt to reach gitlab via git.mydomain.com I get nothing. I can see that gitlab is running by checking the docker log. I've got other services forwarded fine - but gitlab seems to be a PITA. EDIT: Figured it out. Other services weren't using a subdomain. First, make sure you have your ports forwarded to this docker (or getting the certificates *will* fail) Second, if you wish to use subdomains and are using a REAL domain name (not a dyndns style one) make sure you set up a catch-all entry for subdomains (CNAME * yourdomain.com) Finally, create the entry using the GUI. Scratch that - it doesn't seem to persist reboots very well, neither of my two SSL certificates continue to work following a reboot, and I'm getting this spammed in the log: [nginx] starting... nginx: [emerg] BIO_new_file("/etc/letsencrypt/live/npm-9/fullchain.pem") failed (SSL: error:02FFF002:system library:func(4095):No such file or directory:fopen('/etc/letsencrypt/live/npm-9/fullchain.pem', 'r') error:20FFF080:BIO routines:CRYPTO_internal:no such file) Edit: Deleted the appdata folder, recreated entries and all is working again.
-
[DEPRECATED] Linuxserver.io - Rutorrent
Xaero replied to linuxserver.io's topic in Docker Containers
Since the latest update I'm back to square one on the abysmal performance front. Everything was fine. 90+mb/s download speeds on healthy torrents, sustainable throughput all the time. Now I'm back to waiting for getplugins.php for timeouts, and generally unresponsive webui. The rtorrent client itself is also somewhat unresponsive, and the actual throughput is abysmal: As you can see there's basically no read or write operations occuring (rtorrent is the ONLY process on the ENTIRE BOX trying to read/write data) and it's sitting at 90+% IOWAIT with 0% SWAPIN. I don't even know how to approach this anymore. I've tried tweaking rtorrents settings, php's settings, but to no avail. I should also mention none of my other applications or dockers are suffering performance impact of any kind. (I have MineOS running a modded minecraft server, Plex, and gitlab - none of which are seeing any performance problems.) For hardware I have: 24x8TB WD Red 2x256gb Samsung 850 pro sata III ssd (cache) 64gb DDR4-2133 ECC Fully Buffered 2xIntel Xeon E5-2658v3 Dual gigabit lan in Balance-RR, with a compatible switch configured correctly. The drives are connected to a HP 487738-001 24-bay expander card with dual backhaul to an LSI SAS9220-8i. Copying to the share shows full gigabit saturation nice and stable:
-
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
Tried to update today, hung stopping the container before I went to work, came home with it still hung, loading unraid in another tab shows the container is gone. I'm gonna backup the appdata and reinstall it and hopefully be good. -
Since you've had stable performance over a year I usually set up a cron job to purge old log files. I'll gzip the logs once a week to the array, and purge any gzips older than a month or two. I haven't done this with Unraid yet, but had done it with my previous server running Arch.
-
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
Yeah I figured out why that was as well. The DLNA tells media player what to try to do. So since my setup is Stereo on this PC and the audio from the file is usually 5.1 or higher - I just get garbled mess. It doesn't do any transcoding or anything. So I'll just go back to how I was watching stuff locally - browsing through the share and opening it in MPV. -
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
Interesting, I put the IP=*,DirectPlay=true,DirectStream=true and stopped/started. It kind of showed up, then disappeared. I removed that line, and restarted DLNA again; this time it shows up under "This PC" on my Windows 10 client, and I can open files with Media Player - but the audio is a garbled mess. Not sure what to do about that lol. -
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
I'm having trouble getting DLNA to work. The network is set to HOST (as it is by default) I've enabled DLNA in the plex settings. I've enabled both of the advanced network options for unauthorized access and lan for 192.168.1.0/24 (my subnet/mask for the local network) I don't see the plex media server listed in Windows 10 Explorer, Windows Media player or any other DLNA enabled stuff. Any suggestions? -
[DEPRECATED] Linuxserver.io - Rutorrent
Xaero replied to linuxserver.io's topic in Docker Containers
Here's how much I'm waiting on getplugins.php: Edit: Today's update seems to have resolved the issue Still the slowest part of the page, but several orders of magnitude faster.

-
That's the VM CPU pinning. And per the title I am running 6.6.5. The graphical issue is for docker container CPU pinning.
-
[DEPRECATED] Linuxserver.io - Rutorrent
Xaero replied to linuxserver.io's topic in Docker Containers
Is it possible to reduce the number of plugins? I think I've figured out what's causing my issue - the webui hangs for me for quite some time most days, and eventually does start after several refresh attempts. But when it does time out the error is Bad response from server: (504 [error, getplugins]) Loading /php/getplugins.php manually takes several seconds, sometimes more than a minute, and the resulting document is over 10,000 lines. In attempts to fix this I have: Fixed docker permissions using the tool Deleted the Appdata folder for rutorrent and reinstalled the docker. My server is quite beefy and shouldn't be struggling with this: 2x Intel Xeon 2658v3 64gb ddr4-2133 Downloads folder set to /mnt/user. Docker log including a restart: [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. - [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. [s6-finish] sending all processes the TERM signal. [s6-finish] sending all processes the KILL signal and exiting. [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 10-adduser: executing... usermod: no changes ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. - Any other ideas? Edit: I had a crushed patch cable. I've replaced it and things seem to be better. Odd that balance-rr didn't failover for this condition. Will keep you posted if the performance goes back down again. It did resolve after reboots for a while but would eventually get worse. EDIT2: even with the replaced patch cable and a good cable test on both cables to the switch, and from the switch to the router, I'm still experiencing this specific timeout: [28.11.2018 22:38:16] Bad response from server: (504 [error,getplugins]) Gateway Time-out -
Just a minor cosmetic bug when having loads of CPU cores: As you can see, anything past 18c/36t is a bit loopy.
-
Samba configuration is notoriously counterintuitive. You need to ensure that the share is both NOT public and also has valid users listed. [Dropbox] path = /mnt/disks/dropbox comment = browseable = yes public = no valid users = user1 writeable = yes vfs objects = Should have the intended behavior. Note that by having browseable set to yes you will SEE the share with all user accounts, but only be able to explore it when authenticated as user1. Other users, including anonymous (and the smbtree, by proxy) will be able to see the share itself, but not it's contents.
-
I'm scratching my head here. I've got an ArchLinux guest OS and have everything setup. I'm trying to setup VNC on the ArchLinux guest OS as the Qemu VNC is still pretty archaic and doesn't support dynamic resolution changes or scaling very well. I've got the following set in my VM's settings: and this is what my routes look like on the network page: If I use the built-in VNC viewer I can see the VM and it connects; but to the QEMU hosted VNC (obviously) However I cannot ping the VM itself, or try to connect to the VM's VNC server. What am I missing? EDIT: if I use ip addr I can retrieve the ip address of the VM and connect successfully to the VNC using the IP. So it's not my network configuration within unraid, I think.,


-
Had to quit using Flood entirely. Doesn't seem to work at all anymore. Not sure why. I did like flood. Also, as a request - I'd like to see the rpc socket also forwarded so that applications like Electorrent can use the docker. EDIT: Nevermind, ruTorrent isn't working now either. Whelp. And that's after rolling back a version. Gonna try one of the other base rtorrent dockers and a separate flood/rutorrent docker from dockerhub. Not sure what's happening or why at this point.
-
This is one memory hungry boi. 32gb of ram and Gitlab wants 27% of it with zero repos. Wow.
-
I've actually switched to using an SCGI file and still have the same problem. It's driving me up a wall. I need to poke around logs and see if I can figure out what's happening.
-
I just updated MineOS-Node and have lost basically all functionality. I made a backup of my server files of course, but when it starts the container and I login to the WebUI neither of my servers show up. If I try creating a server it isn't added to the list either. Nothing meaningful in the logs: USER_NAME not provided; defaulting to "mc" Created user: mc (uid: 1000) Generating Self-Signed SSL... 2018-11-05 23:19:20,989 CRIT Supervisor running as root (no user in config file) 2018-11-05 23:19:20,989 INFO Included extra file "/etc/supervisor/conf.d/mineos.conf" during parsing 2018-11-05 23:19:21,001 INFO RPC interface 'supervisor' initialized 2018-11-05 23:19:21,001 CRIT Server 'unix_http_server' running without any HTTP authentication checking 2018-11-05 23:19:21,002 INFO supervisord started with pid 1 2018-11-05 23:19:22,004 INFO spawned: 'mineos' with pid 32 2018-11-05 23:19:23,560 INFO success: mineos entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2018-11-05 23:29:17,515 WARN received SIGTERM indicating exit request 2018-11-05 23:29:17,516 INFO waiting for mineos to die 2018-11-05 23:29:17,529 INFO stopped: mineos (terminated by SIGTERM) USER_NAME not provided; defaulting to "mc" mc already exists. 2018-11-05 23:29:23,087 CRIT Supervisor running as root (no user in config file) 2018-11-05 23:29:23,087 INFO Included extra file "/etc/supervisor/conf.d/mineos.conf" during parsing 2018-11-05 23:29:23,098 INFO RPC interface 'supervisor' initialized 2018-11-05 23:29:23,098 CRIT Server 'unix_http_server' running without any HTTP authentication checking 2018-11-05 23:29:23,098 INFO supervisord started with pid 1 2018-11-05 23:29:24,101 INFO spawned: 'mineos' with pid 11 2018-11-05 23:29:25,494 INFO success: mineos entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) Note that I initiated a restart of the docker in this log. EDIT: Deleting the server profiles from the servers folder, restarting the docker and then creating instances named for each server followed by copying the files back over and restarting the docker again has resolved this. Pretty ugly upgrade process but at least it works.
-
I meant in the docker settings And yes, it's perfectly acceptable to just ignore the WebUI reporting 100% CPU usage as long as the Unraid WebUI is not ALSO reporting 100% cpu usage. I'm nitpicky though so I like everything to look perfect lol.
-
How much RAM do you have installed in your unRAID server?
Xaero replied to harmser's topic in Unraid Polls
Currently rocking this: The extra NIC is for planned expansion, but may end up scraping and going with a single 10gbe and shifting the network to 10gbe instead. The two CPUs detect that way because they are engineering samples; 12 core, 24 thread Xeon E5-2658v3 CPUs.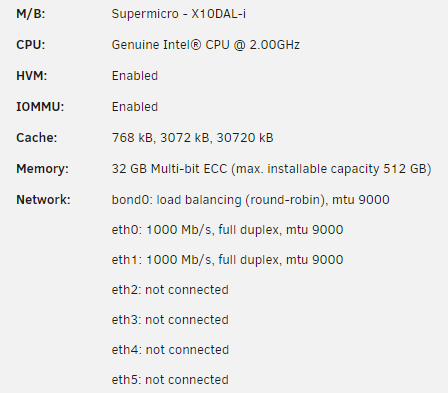
-
Try setting "-t" as an extra parameter in the advanced tab and seeing if you still see the abnormal CPU usage reporting.
-
Any way you could set tty: true to address the CPU usage bug in rtorrent with curl? The fix was applied in another rtorrent docker and seems to have fixed the 100% core usage from rtorrent. Edit: Switching to the advanced tab, and adding "-t" to the extra parameters addresses this issue as well. No longer is one core stuck at 100% usage. Edit2: I realize you are using TMUX to work around that issue; so the -t or tty: true quirk is unapplicable since tmux *should* appear as a TTY to rtorrent. May I also suggest switching to a socket file instead of the ports based system? It seems more stable to me for Flood at least. I've edited the /home/nobody/rtorrent.sh and /home/nobody/flood.sh to wait for the creation of the rpc.socket file like so: until [ -e /tmp/rpc.socket ]; do sleep 0.1 done And updated the config files as appropriate to use the rpc.socket instead of the network settings.
-
Should have probably mentioned; I was experiencing the same problem on Stable as well, and decided to update to see if it would fix it. Edit: Updated my post with a workaround for this chipset. Seems like a problem with the way lm_sensors uses chip names for filtering. "chip coretemp-isa-0000" works fine but "chip nct7904-i2c-0-2e" does not. This should probably be filed upstream with lm_sensors devs. For now commenting out the chip filters seems to work okay.
-
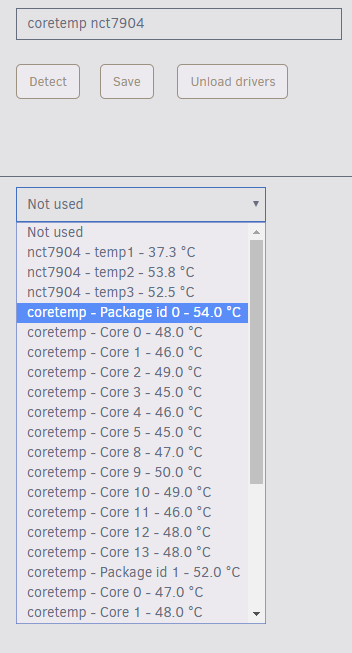
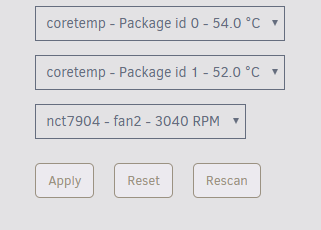
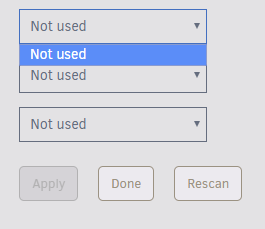
So I have a new build running the latest Unraid 6.6.0 rc-4; and I'm having issues with the temperature plugin. The sensors correctly read inside the plugin like so: However after selecting desired sensors like this: And then hitting "Apply" The sensors all disappear like so: Hitting "Rescan" and done have no effect, and all of the sensors on the dashboard also disappear (fan speeds) Running "sensors" in the terminal gives this output: The content of that file looks like this after hitting Apply: If I delete the file, and then run sensors this is the output I get: If I comment out the lines in the config file "chip nct7904-i2c-0-2e" then it works. Not sure if this is a proper fix but its working for now. Hopefully the developer of this plugin can adopt a solution:
-
That was the point of my post: To show the quoted user where the setting is on the interface. It's easier to show with a screengrab than it is to say "yeah at the bottom of the page on the left side of the footer look for the theme dropdown and click it, you can pick a light theme there."










