

tucansam
-
Posts
1107 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by tucansam
-
Running extended diags on 19 now. Disk 16 says "no device." If I select the disk that was (formerly?) it, will it try to reconstruct it if I start the array? I don't know why that disk dropped off. Its still good, as is the data on it.
-
Its also listed all three disks as "to be encrypted." ffs2-diagnostics-20220930-0409.zip
-
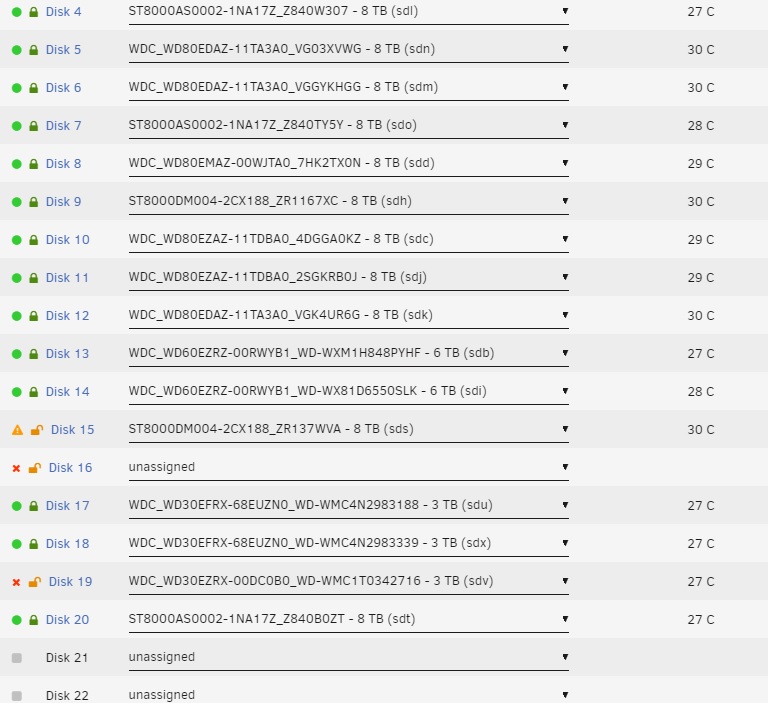
Here is current state of things. Disk 15 is the new disk, formerly "unmountable," which got 30-60 seconds through a format before I aborted and shut down the array. I have the original Disk 15, the one with SMART errors. Disk 16 is physically present, but not showing as assigned. Disk 19 is also red x'd. I have two new-in-box 8TB disks waiting, arrived a few hours ago. I have absolutely no idea how to proceed at this point (two parity disks if it matters). At the very least I'd like to get 16 and 19 back in the game, and worry about 15 later. Unless there is a better order to this.....
-
Yes, I still have the original Disk 15. I am more concerned about the other two disks that are now showing up as Red X's, although I don't believe them to be truly problematic, as I looked at all SMART data for them. My old procedure for disk replacement was to pre-clear the disk on a separate unraid server (this was years ago). Then, at some point, the new unraid version started either doing it automatically (I think I remember that being a thing) or I just stopped doing it. I would pop in a new disk, start the array, unraid would rebuild it, and its off to the races. The last three times I've replaced a disk, this has happened. The array starts, the disk shows up as "unmountable" and is offline, yet a parity sync starts. I end up confused and format the disk. In fact, the very last time this happened, I lost data as well, but I thought it was me mis-remembering something along the way and screwing it up. Right now I have the server powered down with two red X disks and one that needs to be rebuilt. Plus the old drive that I'm replacing.
-
Disk 15 showed tons of unrecoverable errors, so I replaced it. It came up as "unmountable" so I checked the box to format it, and clicked format. Disk 16 immediately went into an error state (red x). I have two parity disks, so I began reconstruction of Disk 15, and just bought an overnight replacement for Disk 16 (I keep one spare on hand and used it to replace Disk 15). During the rebuilt, Disk 19 has now thrown red X! I now have one freshly formatted disk that was 0.000001% done being reconstructed, and two disks that have just thrown red x's. My only priority at this point is data preservation, all other considerations are secondary. This array has given me absolutely no end of trouble since Day 1, with months or even years of trouble free running, followed by weeks of multiple cascading disk failures, errors, etc. They all come in spurts. I've swapped cables, power supplies, etc over the years. And years. And years. I'm do have 20+ disks, which is far too many, and I'm trying to talk myself into dropping $$$$$$ on a brand new sever with the same capacity but a third the number of disks. Too many variables with this many drives, cables, controllers, etc. In the mean time.... The disks that are all failing right now are on an HBA and a SAS expander in a separate chassis. Not sure if that's a coincidence or not but I doubt it. The red X's have started right after I pulled the tower to swap disk 15 -- while I was in there I reseated all of the cable and data connectors on the disks in that chassis (6 disks total, three have now apparently died). The original Disk 15 was definitely dead as per SMART. These other two disks are probably fine (99.9% of my red x's over the decade+ that I've used unraid have been false alarms). Once again.... many disks down.... data preservation key. How do I proceed? Thank you.
-
197 Current pending sector 0x0012100100000 Old age Always Never 16 198 Offline uncorrectable 0x0010100100000 Old age Offline Never 16 Do these two errors, and their count of 16, mean the disk is done? I'm getting yellow notification popups, although the disk is still online.
-
No.
-
My present unraid server has been running for over a decade, maybe longer. I did do a MB/CPU swap very early on, maybe with a half dozen disks or less attached. Over the years it has grown into quite a monster, and there are enormous amounts of data spanning 20+ disks. I want to minimize the risk involved with upgrading MB/CPU again. I will also be converting some isolated mechanical disks to SSDs. I am open to suggestions, however, my plan is currently: - Back up flash drive - Back up docker.img - Screen shot disk assignments - Screen shot docker images config pages At that point I will shutdown the server, take it apart while giving it a really deep clean, swap in the new MB and then fire it up for testing. What best practices am I missing? Thanks.
-
Will I be able to get past the encryption?
-
Had a disk fail. Replaced it, and in the process, the replacement disk was formatted after data was rebuilt back onto it (long story). I have the failed disk (bad sectors, data should still be mostly in tact). The array is comprised of disks formatted xfs, encrypted. Can I plug this bad drive into another system, or my current unraid server, mount it, and get data off it?
-
I'm about to scrap this entire server and start over. Just finished a parity check after rebuilding that damn drive and my error count is 1285349.
-
Both were new. Disk16 was installed parity rebuilt and never showed as needing formatted... Then it unmounted during a parity check and remained that way. I formatted it and I'm sure I lost some data..... The next disk added showed unformatted from the get-go and thus was formatted and then parity rebuilt.
-
ffs2-diagnostics-20220718-1919.zip
-
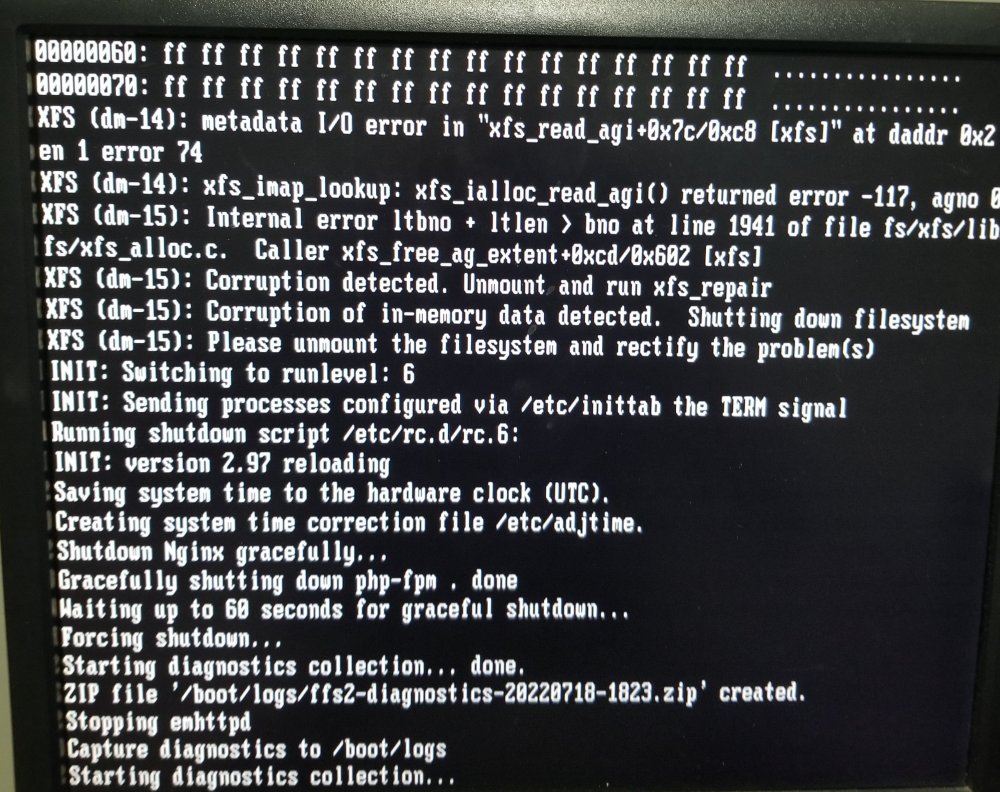
Saw this on the console as I was taking the server down for a reboot. What does this mean?
-
ERROR 3 hours ago Error while adding Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD.nzb, removing Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/nzbparser.py", line 319, in process_single_nzb nzo = nzbstuff.NzbObject( File "/usr/lib/sabnzbd/sabnzbd/nzbstuff.py", line 778, in __init__ admin_dir = os.path.join(self.download_path, JOB_ADMIN) File "/usr/lib/python3.10/posixpath.py", line 76, in join a = os.fspath(a) TypeError: expected str, bytes or os.PathLike object, not bool ERROR 3 hours ago Failed making (/downloads/incomplete/Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD) Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/filesystem.py", line 719, in create_all_dirs os.mkdir(path_part_combined) OSError: [Errno 5] Input/output error: '/downloads/incomplete/Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD' ERROR 9 hours ago Error while adding Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD.nzb, removing Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/nzbparser.py", line 319, in process_single_nzb nzo = nzbstuff.NzbObject( File "/usr/lib/sabnzbd/sabnzbd/nzbstuff.py", line 778, in __init__ admin_dir = os.path.join(self.download_path, JOB_ADMIN) File "/usr/lib/python3.10/posixpath.py", line 76, in join a = os.fspath(a) TypeError: expected str, bytes or os.PathLike object, not bool ERROR 9 hours ago Failed making (/downloads/incomplete/Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD) Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/filesystem.py", line 719, in create_all_dirs os.mkdir(path_part_combined) OSError: [Errno 5] Input/output error: '/downloads/incomplete/Sc*-In The Kin*REMASTERED-CD-FLAC-2012-YARD' Just saw this in sab. First time this has ever happened. I can ssh in and access the download folder just fine.
-
I've never rebuilt two disks at the same time. Not sure how to go about it.
-
I mean read errors that show up in the "errors" column on the main page. I'm just about to 20% complete on the rebuild, so I may just let it ride and do an extended test when its done.
-
Post for diags. ffs2-diagnostics-20220717-1229.zip
-
I have two parity disks if it matters. Week ago I had a drive throwing a ton of unrecoverable errors, write errors, was disabled. It was old, no biggie. Replaced it with a brand new disk, rebuilt the array. Today I lost a second drive. Massive unrecoverable errors. Replaced it with w brand new disk, began the array rebuild. Now, during the middle of the rebuild, the disk I replaced last week (with a brand new replacement) is up to 9008 unrecoverable errors. Although its not disabled (yet?) so they appear to be read errors. Question: how do I handle a disk that is throwing errors in the middle of a parity rebuild? As an aside, all of the disks that have thrown errors in the last week are on an external SAS controller. As a second aside, literally *every* time I've ever moved a disk, added a disk, swapped a disk, or looked at a SATA connector for more than ten seconds, over the entire time I have been using unraid (decade or more), CRC errors pop up. After a simple reboot they all disappear.
-
[Support] Linuxserver.io - Plex Media Server
tucansam replied to linuxserver.io's topic in Docker Containers
The last few posts in this thread really make me weary of upgrading and trying a modern processor or video card with Plex. -
Maybe I have to turn on advanced options or something? I see neither in sonarr or radarr, and I believe I am up to date on versions.
-
Neither sonarr or radarr have that screen you screenshot for permissions.
-
arrs? I also have tons of music, tv shows, and movies in the sab download folder that need to be moved by hand. Many move automatically, but once a month I check and there are usually dozens that did not move, did not get renamed, etc. I have always chalked it up to permissions, and have never been able to pin it down.
-
A very common theme that has plagued my install for going on a decade, particularly when I started using dockers, is permissions issues. For example, just a few moments ago, I went into Sonarr, added a TV show, and it created the directory for the show automatically. I tried to copy a file to that directory from a Windows PC, and got a permissions problem. chmod +w or 777 etc etc etc on the directory from the shell of course fixes it. This has occurred with Sonarr, Radarr, SAB (moving files after download), Headphones.... Even simply creating a directory on an unraid share, from Windows, sometimes leaves it either unable to be written to, or when I try to delete a file within said directory, permissions problem. I often run "docker safe new permissions" and of course this fixes the issue, but my array is sitting at 132TB right now and it takes FOREVER. Often times using the shell to fix permissions by hand is where I end up. This issue does not happen all the time. My question it, why does this happen, and why is it intermittent?
-
I removed and re-installed Uninstalled Devices and everything is back to normal. Thank you for the help.

