

vakilando
-
Posts
367 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by vakilando
-
-
I attached my diagnostics.
At the moment everything is fine, all shim networks exist (last reboot today wasmanually and wanted).
I'll post another diagnostics after a crash.
I could also provoke a power outage if it can be helpfull....
-
6 hours ago, arturovf said:
Happens with static ip as well
this is true
-
When I reboot my Unraid server the the shim networks are created and everything is fine.
But it does not create the shim networks after an automatic reboot after a crash or power outage.
I don't know what should be the difference between a wanted manually reboot and an automatic reboot after crash or power outage??
-
Ok, it seems to be fixed for me.
I rebooted several times, updated unriad to 6.10.1 ans everything (shim network) works as expected.
Note:
I realized that unraid does not create the shim network after recovering (rebooting) from an unraid crash.
I still don't know exactly why it crashes...but my raspi (with pivccu homematic CCU3) crashes at the same time. I have the presumption, that it's my raspi crashing first and unraid crashes because of the raspi. They are on the same socket strip... Investigating.........
So this bug report can be closed again!
-
hmm, my Unraid Server has static IPs, all also of my dockers and vms
Oh wow, I didn't now that unRAID 6.10 was released!! Fantastic!
I just upgraded (flawlessly).
Booted two times since then without any problems. I will test again later and report here.
-
Have you tried a newer RC. Does this solve this annoying issue?
(I have the same issue in 6.9.2....and just reopend a bug report)
-
Changed Status to Open
-
Ok, I have better informations now. I know what happens but still don't know the cause...
I am on 6.9.2 and also randomly encounter the problem to loose connection from host to some docker containers mostly after an reboot of unraid.
Sometimes this issue aslo comes out of the blue.
I don't know exactly when it appears on my running Unraid Server (out of the blue) because I may realise this some days after it appeared... But I can imagine that it may somtimes happen after a automatic backup of appdate with the plugin "CA appdata backup/restore V2" because this plugin stops and resatrs the running docker container.Last time it happend: Yesterday.
Probably at 1:00 AM. My server just rebooted out of the blue because of another problem (I'm investigating...)
After this: no shim networks. Resolved today at ~08 AM
(see attached log)My relevant configuration:
I have
- Network: two NICs and four VLANs.
- Docker: "Allow access to host networks" checked/active.
- Dockers and VMs in those VLANs (br.01, br0.5, br0.6, br1.5, br1.16)
- A Home Assistant Docker (host network) that looses connection to some other docker containers on different vlans (e.g. ispyagentdvr on custom br0.6 network, motioneye on custom br0.5 network, frigate on custom br1.15 network).
This raises this issue:
- Reboot of unraid: sometimes
- Running unraid: sometimes (because of plugin "CA appdata backup/restore V2"??)
This workaround solves this issue temporary:
- Always: Stopp docker service, de-/reactivate "Allow access to host networks", restart docker service
- Sometimes: Reboot of unraid
I didn't try manually readding the shim networks but in this post "shim-br0-networs-in-unraid" it seems to be a possible workaround:
So the problem are the shim networks!?
- They sometimes aren't set at boot. (Why?)
- They sometimes get lost. (Why?)
What are shim networks?:
shim networks should be created when the Docker setting "Host access to custom networks" is enabled.
This allows Unraid to talk directly with docker containers, which are using macvlan (custom) networks.
But those shim networks are not allway created after reboot!So it's still a NOT solved bug:
What worries me, is that this is a bug that seems to persist in Unraid 6.10-rc3:
Perhaps a user-script could detect missing shim networks and readding them? Any ideas or hints??
Please see the pictures and the log I attached.
Before stopping docker service.
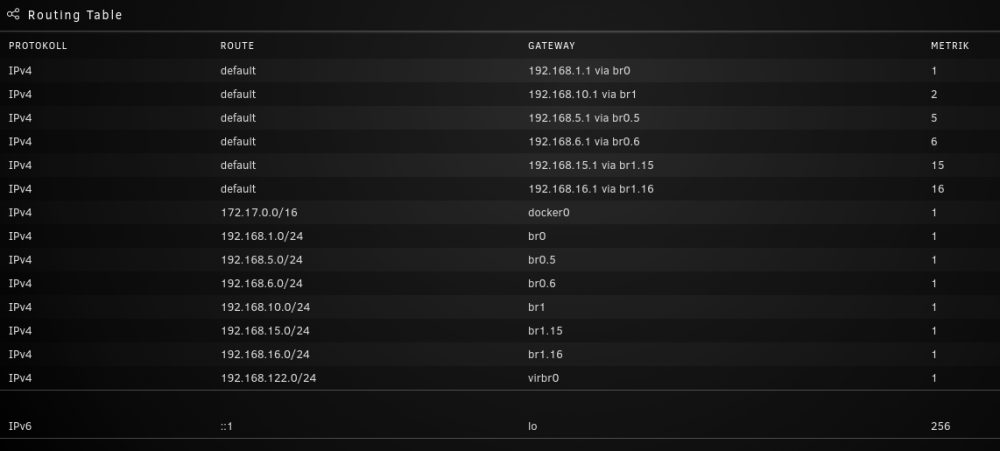
After de-/reactivating "Allow access to host networks" followed by restarting docker service
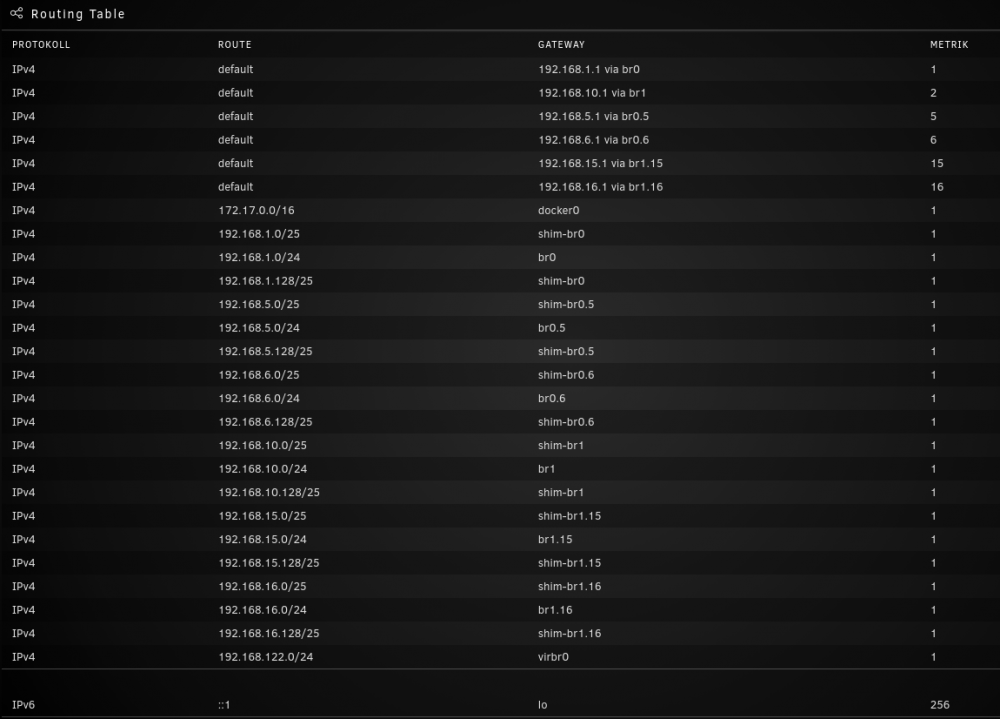
See the (commented) log file:
syslog_2022-05-18_crash-at-01-AM-no-shim-networks-after-reboot_fix-at-08-AM.log
-
I'm also still randomly encountering this problem. This issue doesn't seem to be finally solved...
I have "Allow access to host networks" checked/active.
My Home Assistant Docker (host network) sometimes looses connection to some other docker containers on different vlans (e.g. ispyagentdvr on custom br0.6 network, motioneye on custom br0.5 network, frigate on custom br1.15 network).
Stopping and starting the docker service always solves this issue. A reboot of unraid sometimes solves this issue, sometimes it's raising this issue. I have two NICs and four VLANs.
-
Thank you! I'll try this out.
I disabled healthcheck on almost all containers and have no problems or even noticed any changes.
-
On 6/24/2021 at 3:06 PM, TexasUnraid said:
Looks like I have disabled most of the docker logs at this point
How did you disable the logs exactly?
7 hours ago, TexasUnraid said:worst offenders
and which dockers were the worst offenders?
-
On 8/11/2020 at 9:57 PM, testdasi said:
Yep, 6.9.0 should bring improvement to your situation. But as I said, you need to wipe the drive in 6.9.0 to reformat it back to 1MiB alignment and needless to say it would make the drive incompatible with Unraid before 6.9.0.
Essentially back up, stop array, unassign, blkdiscard, assign back, start and format, restore backup. Beside backing up and restoring from backup, the middle process took 5 minutes.
I expect LT to provide more detailed guidance regarding this perhaps when 6.9.0 enters RC or at least when 6.9.0 becomes stable.
Not that 6.9.0-beta isn't stable. I did see some bugs report but I personally have only seen the virtio / virtio-net thingie which was fixed by using Q35-5.0 machine type (instead of 4.2). No need to use virtio-net which negatively affects network performance.
PS: been running iotop for 3 hours and still average about 345MB / hr. We'll see if my daily house-keeping affects it tonight.
Thanks!
The procedure "back up, stop array, unassign, blkdiscard, assign back, start and format, restore backup" is no problem and not new for me (except of blkdiscard) as I had to do it as my cache disks died because of those ugly unnecessary writes on btrfs-cache-pool...As said before, I tend changing my cache to xfs with a singel disk an wait for the stable release 6.9.x
Meanwhile I'll think about a new concept managing my disks.
This is my configuration at the moment:
- Array of two disks with one parity (4+4+4TB WD red)
- 1 btrfs cache pool (raid1) for cache, docker appdata, docker and folder redirection for my VMs (2 MX500 1 TB)
- 1 UD for my VMs (1 SanDisk plus 480 GB)
- 1 UD for Backup data (6 TB WD red)
- 1 UD for nvr/cams (old 2 TB WD green)
I still have two 1TB and one 480 GB SSDs lying around here..... I have to think about how I could use them with the new disk pools in 6.9
-
9 hours ago, testdasi said:
(...) Are you using 6.9.0? Did you also align the parition to 1MiB? That requires wiping the pool so I would assume quite few people would do it.
No, I'm on 6.8.3 and I did not align the parition to 1MiB (its MBR: 4K-aligned).
What is the benefit of aligning it to 1MiB? I mus have missed this "tuning" advice...
-
ok, after I've executed the recommended command:
mount -o remount -o space_cache=v2 /mnt/cachethis ist the result after 7 hours of
iotop -aoThe running dockers were the same as my "Test 2" (all my dockers including mariadb and pydio)
See the picture:
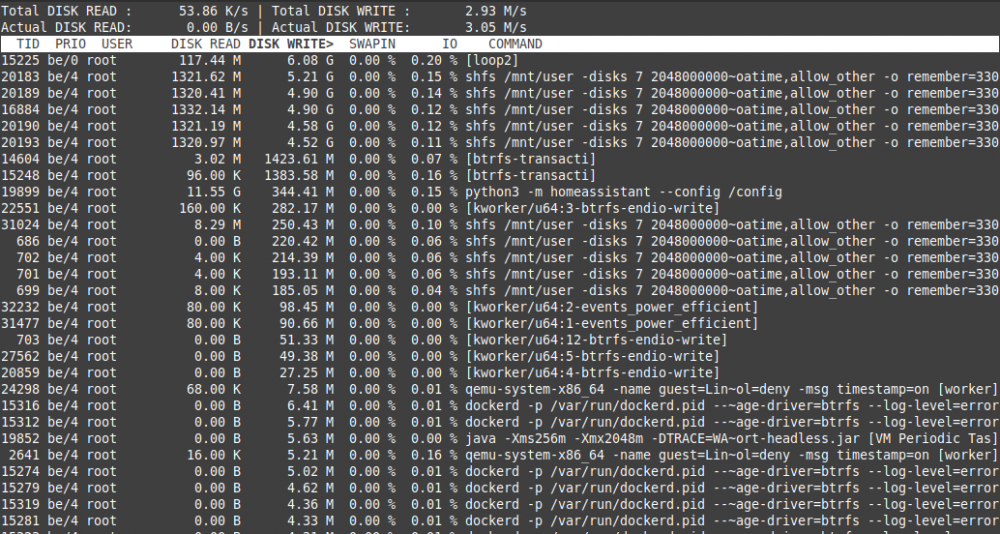
It's better than before (less writes for loop2 and shfs) but it should be even less or what do you think?
-
oh....sorry... I did not read the whole thread...
Now I did!
I'll try the fix now an do this:
mount -o remount -o space_cache=v2 /mnt/cache -
perhaps I should mention, that I had my VMs on the cache pool before, but the performance was terrible.
Since moving them to an unassigned disk their performance is really fine!
Perhaps the poor performance was due to the massive writes on the cache pool....?
-
Damn! My Server seems also to be affected...
I had an unencrypted BTRFS RAID 1 with two SanDisk Plus 480 GB.
Both died in quick succession (mor or less 2 weeks) after 2 year of use!So I bought two 1 TB Crucial MX500.
As I didn't know about the problem I again made a unencrypted BTRFS RAID 1 (01 July 2020).
As I found it strange that they died in quick succession I did some researches and found all those threads about massive writes on BTRFS cache disks.
I made some tetst and here are the results.### Test 1:
running "iotop -ao" for 60 min: 2,54 GB [loop2] (see pic1)
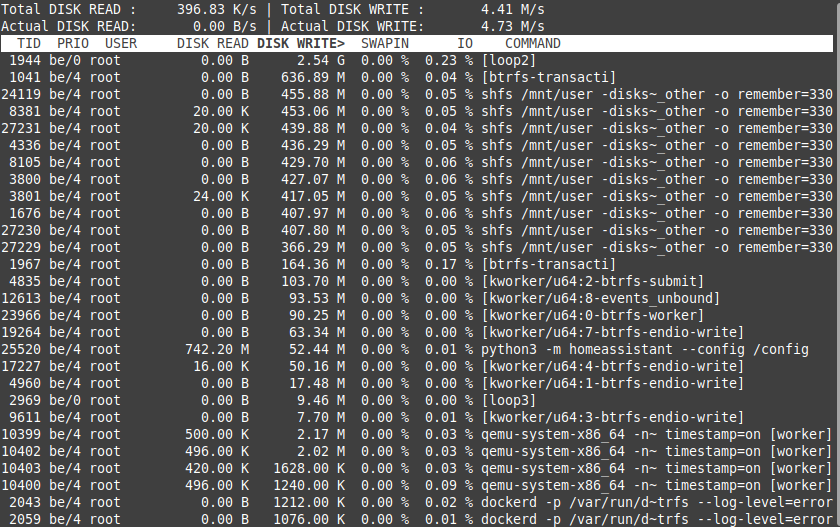
Docker Container running:
The docker containers running during this test are the most important for me.
I stopped Pydio and mariadb though its also important for me - see other tests for the reason...- ts-dnsserver
- letsencrypt
- BitwardenRS
- Deconz
- MQTT
- MotionEye
- Homeassistant
- Duplicacyshfs writes:
- Look pic1, are the shfs writes ok? I don't know...
VMs running (all on Unassigned disk):
- Linux Mint (my primary Client)
- Win10
- Debian with SOGo Mail Server/usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 10.9
/usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 10.9
### Test 2:
running "iotop -ao" for 60 min: 3,29 GB [loop2] (see pic2)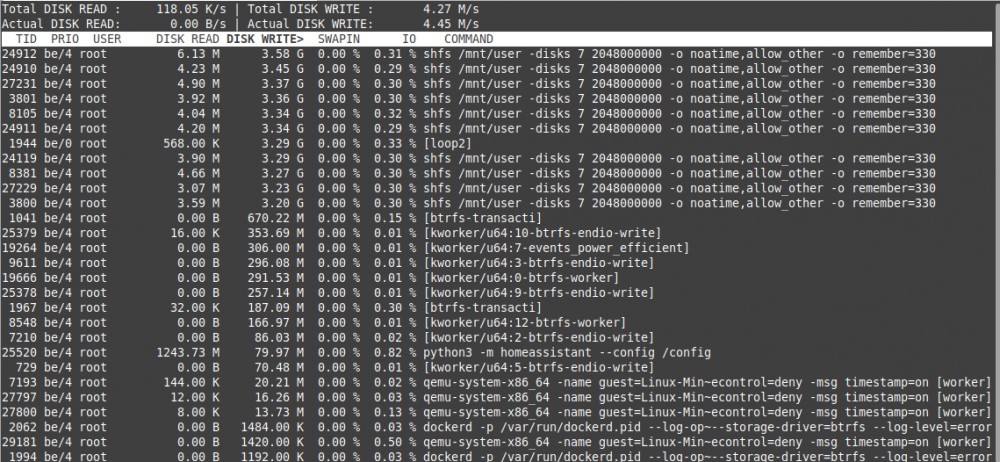
Docker Container running (almost all of my dockers):
- ts-dnsserver
- letsencrypt
- BitwardenRS
- Deconz
- MQTT
- MotionEye
- Homeassistant
- Duplicacy
----------------
- mariadb
- Appdeamon
- Xeoma
- NodeRed-OfficialDocker
- hacc
- binhex-emby
- embystat
- pydio
- picapport
- portainershfs writes:
- Look pic2, there are massive shfs writes too!
VMs running (all on Unassigned disk)
- Linux Mint (my primary Client)
- Win10
- Debian with SOGo Mail Server/usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11
/usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11### Test 3:
running "iotop -ao" for 60 min: 3,04 GB [loop2] (see pic3)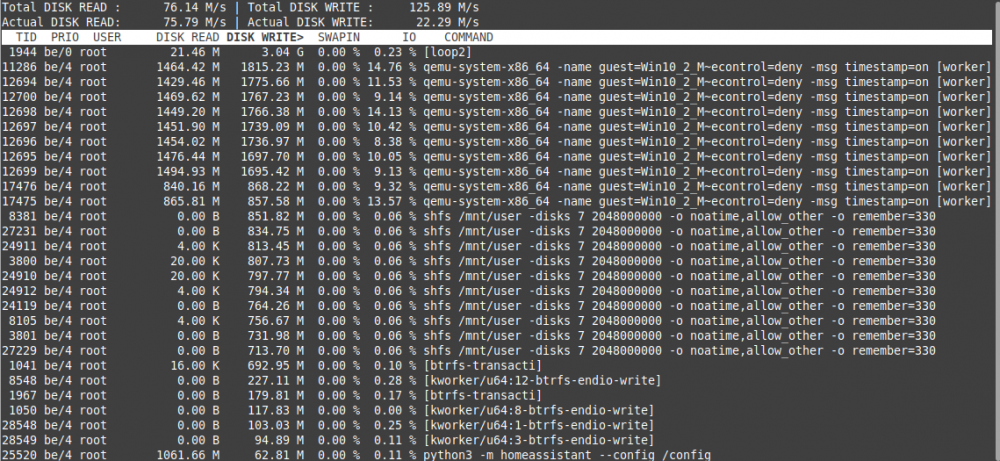
Docker Container running (almost all my dockers except mariadb/pydio!):
- ts-dnsserver
- letsencrypt
- BitwardenRS
- Deconz
- MQTT
- MotionEye
- Homeassistant
- Duplicacy
----------------
- Appdeamon
- Xeoma
- NodeRed-OfficialDocker
- hacc
- binhex-emby
- embystat
- picapport
- portainershfs writes:
- Look at pic3, the shfs writes are clearly less without mariadb!
(I also stopped pydio as it needs mariadb...)VMs running (all on Unassigned disk)
- Linux Mint (my primary Client)
- Win10
- Debian with SOGo Mail Server/usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11
/usr/sbin/smartctl -A /dev/sdh | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 * 512 / 1024^4 }' => TBW 11
### Test 4:
running "iotop -ao" for 60 min: 6,23 M [loop2] (see pic4)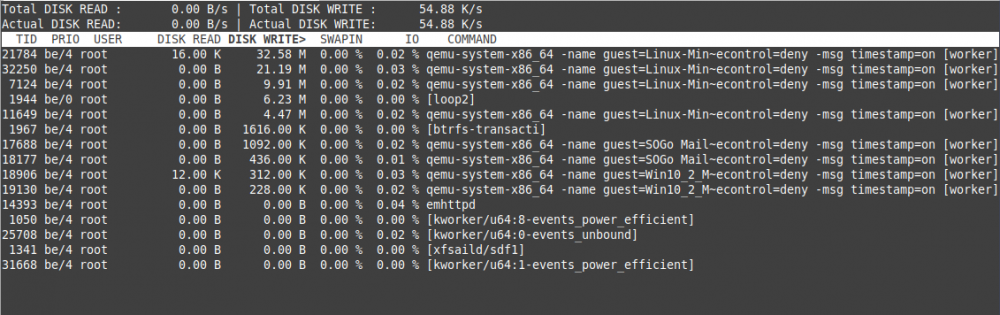
Docker Container running:
- none, but docker service is started
shfs writes:
- none
VMs running (all on Unassigned disk)
- Linux Mint (my primary Client)
- Win10
- Debian with SOGo Mail Server/usr/sbin/smartctl -A /dev/sdg | awk '$0~/LBAs/{ printf "TBW %.1f\n", $10 *
PLEASE resolve this problem in next stable release!!!!!!!Next weenkend I will remove the BTRFS RAID 1 Cache and go with one single XFS cache disk.
If I ca do more analysis and research, please let me know. I'll do my best!
-
I can and confirm that setting
"Settings => Global Share Settings => Tunable (support Hard Links)" to NO
resolves the problem.
Strange thing is that I never had a problem with nfs shares before.
The problems started after I upgraded my Unraid Server (mobo, cpu, ...) and installed a Linux Mint VM as my primary Client.
I "migrated" the nfs settings (fstab) from my old Kubuntu Client (real hardware, no VM) to the new Linux Mint VM and the problems started. The old Kubuntu Client does not seem to have those problems...Perhaps also a client problem? kubuntu vs mint, nemo vs dolphin?
I do not agree that NFS is an outdated archaic protocol, it works far better than SMB if you have Linux Clients!
-
 2
2
-








Lost Access to Host from Docker on Custom br0 after reboot
in Stable Releases
Posted
just wanted to say that the issue came back last week (unraid 6.11.1) - out of the blue...
No crash, no reboot, no configuration change.....
Stopped and started Docker and everything is fine again.
at a loss....