




EArroyo
Members
-
Joined
-
Last visited
-
EDIT: Shares dissapeared. So if I need to rebuild again I want to know if I can stop, remove the drive being rebuilt then add it back and start rebuild? Also makes me wonder if the drive I replaced was ok and didn't need replacement if something else is failing, like PSU, or even my UPS? I had 7 CRC errors on the drive I replaced. Errors are on disk 1 and on 2nd drive but both seem to have no SMART errors except 1 CRC on disk 2... mmpc2-diagnostics-20260510-1913.zip
-
Correct. I get these a lot and I can’t clear them because they constantly show up not allowing me to click on acknowledge
-
I lost NerdPack and no longer have p7zip. Any way I can get it installed where it gets updated automatically?
-
I've waited a long time to see if this gets addressed, but apparently it is being overseen? A picture is worth 1000 words...
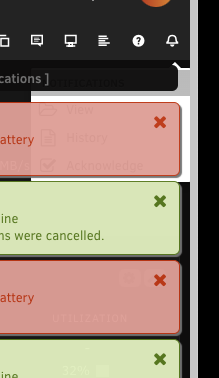
-
I managed to install the latest libssl1.1 and I am able to connect both TLS/SSL and unsecured from a client. I am still trying to figure out how to link 2 servers. Anybody been able to accomplish this? I have swag and managed to create paths accessible from InspIRCd and can successfully connect to 6667 and 6697 from The Lounge web IRC client running on the same unRAID server. All I'm missing are valid <link> and <uplink> which I haven't been able to figure out.... Any help/advise would be great. Running version 4.7.0 All good and working now. I was using xml format but slash was erroring.
-
Any alternative? It's missing libssl1.1
-
Getting an error trying to run InspIRCd: ---Ensuring UID: 99 matches user--- usermod: no changes ---Ensuring GID: 100 matches user--- usermod: no changes ---Setting umask to 000--- ---Checking for optional scripts--- ---No optional script found, continuing--- ---Taking ownership of data...--- ---Starting...--- ---Version Check--- ---InspIRCd v4.7.0 up-to-date--- ---Prepare Server--- ---Checking if TLS Certificate is in place...--- ---TLS Certificate found, continuing!--- ---Checking if Diffie–Hellman parameters file is in place...--- ---Diffie–Hellman parameters file found, continuing!--- ---Server ready--- ---Starting InspIRCd--- InspIRCd - Internet Relay Chat Daemon See /INFO for contributors & authors ERROR: Cannot open config file: /inspircd/conf/inspircd.conf Exiting.. EDIT: I created my own. New problem is that I can't link 2 of these InspIRCd servers. I have added the correct <bind> <link> and <uplink> but no luck... Any examples available for me to try?
-
Need a bit off help with adminer Went to Github and tried to do the sqlite password less but no-go I even tried copying the login-password-less.php on plugins folder to plugins-enabled folder and restarting, still no-go Any help will be appreciated. Thanks!
-
Sorry to revive an old thread, but I just had to do this and since my docker isn't auto-start, I needed to check if it was running first before restarting it.... Here is the script I used: #!/bin/bash if [ "$(docker inspect -f '{{.State.Running}}' container_name 2>/dev/null)" = "true" ]; then docker restart container_name; fi Replace container_name with the docker name, in this case deluge...
-
Got a question, not sure where to ask, but since it pertains to Zoneminder I'll ask here... I have the Appdata Backup Plugin installed, and the plugin turns off the docker, backs it up, then turns it back on. Is the Zoneminder shutdown script/process safe even while it's recording an alarm? I have a lot of issues and db corruption at random points, and I have had to dump, drop, recreate and restore the zm database quite a few times, not sure what the cause is, but it started when I upgraded from 6.9.2 to 6.12.6... I know this got really bad when I left the NO_START_ZM set to 1 and since I have figured out it doesn't do a normal startup or shutdown, I have set it to 0 and this has "stopped for now" but want to make sure it is safe, otherwise I would skip it on the backup and manually back it up myself. Thanks in advance.
-
EDIT: Fixed the problem. Noticed a 99:user on some of the folders..... On console I did: chwon -R www-data:www-data *
-
Upgraded unRAID from 6.9.2 to 6.12.6 and now my NextCloud is giving me an error: Internal Server Error The server encountered an internal error and was unable to complete your request. Please contact the server administrator if this error reappears multiple times, please include the technical details below in your report. More details can be found in the server log.
-
Long story short, I waited to upgrade because I didn't want to reinstall OS, and got my Server 2019 VM (using VNC) working, but my Windows 11 with AMD RX460 GPU passthrough is not working. Can someone shed some light? Let me know what you need (logs, etc etc...) Thanks!
-
Any *EASY* fix for this??? (Besides reinstalling Windows?) Plugins are starting to require 6.11* or 6.12*, what a PITA!
-
Same here, running 6.9.2. Refuse to upgrade, I have 2 VMs (Windows 11 and Server 2019) licensed and don't want to spend again on these licenses or go through the hassle of contacting Microsoft and/or getting video passthru working. EDIT: Found this workaround...

