

rragu
-
Posts
53 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by rragu
-
-
EDIT: SOLVED
Looks like my vBIOS was the issue! Despite following SpaceInvaderOne's video/script to dump the vBIOS from my card, that vBIOS doesn't appear to work. it was only after I used one of the compatible vBIOSes from TechPowerUp that I was able to see the following in the VM's Device Manager:
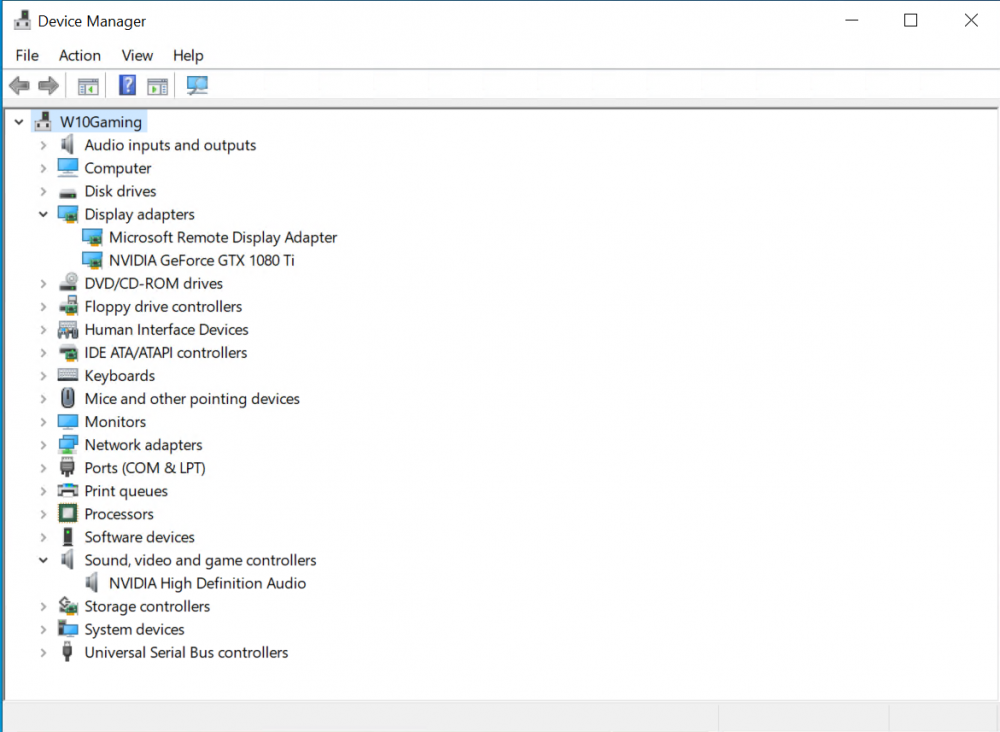
I also undid the ACS override and stuck with i440fx as Machine Type
-
As with DemoRic above, I get the following error: "Fatal error: Cannot redeclare _() (previously declared in /usr/local/emhttp/plugins/parity.check.tuning/Legacy.php:6) in /usr/local/emhttp/plugins/dynamix/include/Translations.php on line 19" although I get it once the Array is started and I'm logged into the dashboard (not only when the array is stopping). I don't think I got it before installing v2021.09.10.
-
I've been trying and failing to get my graphics card passed through to a Windows 10 VM for a few hours now no matter what I try. I'm going to need some help to go any further.
I've been largely following this guide on setting up remote gaming
Details/Settings:
GTX 1080 Ti is in the motherboard's top slot (so I guess that makes it the primary GPU?)
ACS override: set to Both
VFIO: Both graphics and sound devices stubbed via Tools>System Devices
Boot: Legacy boot
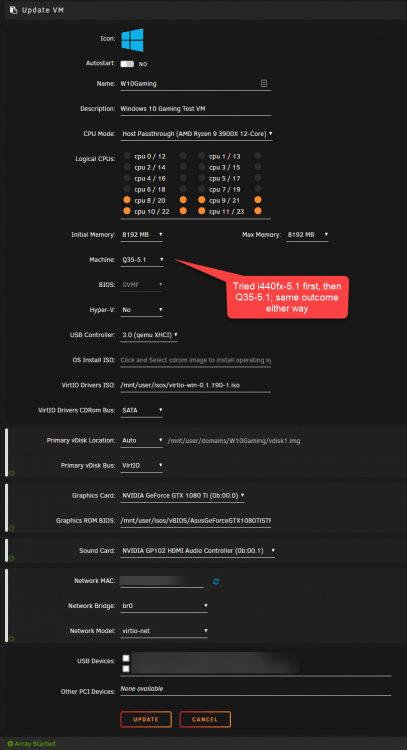

After adding the graphics card with settings as detailed above and booting the VM, Device Manager doesn't recognize any nVidia card as being installed. All I see under Display Driver in Device Manager is Microsoft Basic Display Adapter and Microsoft Remote Display Adapter.
If I go ahead install the nVidia drivers anyway, I then get Code 43 (which I suppose isn't surprising at all if Windows doesn't recognize the GPU in the first place).
Ideas on how to move forward from here would be very much appreciated. Thanks!
-
For anyone stumbling across this post having the same issue, this problem *appears* to have been solved by simply updating my BIOS.
From some cursory Googling, the problem appeared to be related to overclocking my memory (to be clear, I was only running it at the XMP-rated 3600MHz speed). I had already run a memTest on the memory sticks which brought up no errors.
So, I simply updated my BIOS to see if that would solve the problem. I haven't had any Machine Check Events warnings since.
-
 1
1
-
-
First off, thank you @Sycotix for your Authelia CA container as well as your video series on YouTube. Very helpful and detailed!
I've set up Authelia using a combination of your video and this blog post by Linuxserver. I mostly followed your video except for the end where I used SWAG instead of NPM.
I've tested Authelia by protecting two endpoints: Syncthing and Tautulli.
A few questions:
1) When I go to https://syncthing.mydomain.com, I get a distorted Authelia login page (please see attached images), whereas when I go to https://tautulli.mydomain.com, I get the usual Authelia login page. This is the case on desktop Firefox, Chrome, and Edge. I don't suppose you've seen this before? Any ideas as to why this might be? The distorted page is still functional (just not as pretty).
EDIT: tried on mobile Chrome (iOS) and mobile Safari. For both mobile browsers, both Syncthing and Tautulli give me the distorted Authelia page.
2) In any case, once I login, I get to another login prompt. Obviously this is from the authentication I enabled before Authelia was set up. So, now that Authelia is protecting these services, am I good to just disable the "internal" (for lack of a better word) authentication for these services?
2a) I disabled the basic GUI auth for Syncthing. And while Authelia of course still protects Syncthing, I do now get a bright red warning message from Syncthing that I need to set GUI authentication. Is there any way to make Syncthing aware of Authelia or link them in some way so that the warning message goes away?
3) For the majority of my reverse-proxied services, I will probably be the only one who needs to access them. But for certain services (e.g. Ombi) where I would have multiple users, how do I set it up such that userX and userY logging in via Authelia automatically signs in userX and userY, respectively, to the desired service?
Thanks for any and all help!

-
So, I'm in the process of setting up my unRAID server when I got a notification regarding Machine Check Events.
I've attached the diagnostics. The relevant part of the syslog appears to be:
QuoteJun 4 22:53:27 TheRamsServer kernel: mce: [Hardware Error]: Machine check events logged
Jun 4 22:53:27 TheRamsServer kernel: [Hardware Error]: Corrected error, no action required.
Jun 4 22:53:27 TheRamsServer kernel: [Hardware Error]: CPU:0 (17:71:0) MC27_STATUS[-|CE|MiscV|-|-|-|SyndV|-|-|-]: 0x982000000002080b
Jun 4 22:53:27 TheRamsServer kernel: [Hardware Error]: IPID: 0x0001002e00000500, Syndrome: 0x000000005a020005
Jun 4 22:53:27 TheRamsServer kernel: [Hardware Error]: Power, Interrupts, etc. Ext. Error Code: 2, Link Error.
Jun 4 22:53:27 TheRamsServer kernel: [Hardware Error]: cache level: L3/GEN, mem/io: IO, mem-tx: GEN, part-proc: SRC (no timeout)Can anyone please help me to understand this output? My server's component details are in my signature.
Thanks!
-
8 hours ago, ich777 said:
But keep in mind that you don't have to extract the BIOS from the card anymore.
")
Sorry, just to make sure I'm understanding you right:
I don't need to do anything to the 1080 Ti primary GPU other than bind it to VFIO via System Devices? I don't need to specify the vBIOS in the W10 VM's config/XML etc.?
-
5 minutes ago, ich777 said:
Go to Tools -> System Devices -> Click the checkboxes for the 1080Ti (Graphics and Audio) and click on Bind to VFIO on Boot, this should make the card invisible for Unraid and the plugin so that ot ia reserved for exclusive access in the VM.
Thanks!
Are there any possible issues that could occur as a result of stubbing the primary GPU (just wondering if there is something to look out for)?
-
Hi, not entirely sure if this is the right place to post this but here goes:
My setup:
- CPU: R9 3900X
- Motherboard: Asus Crosshair VIII Hero
- PCIe x16 Top Slot: GTX 1080 Ti
- PCIe x16 Second Slot: Quadro P2000
- PCIe x16 Third Slot: LSI 9207-8i
- Running unRAID 6.9.2What I want to accomplish:
- Pass through the primary GPU (1080Ti) for a W10 VM for gaming
- Use the secondary GPU (P2000) for Plex/Emby hardware transcodingFrom what I understand, I need to:
1) Dump the vBIOS (following SpaceInvaderOne's video) for the 1080Ti since it's an nVidia GPU in the primary slot
2) Install this nVidia plugin to use the P2000 for hardware transcoding in DockerMy question is:
Apart from 1 & 2 above, is there anything special I need to do to accomplish my goals (e.g. stubbing the primary GPU or something like that)?
N.B.: if switching the GPUs (i.e. put the P2000 in the primary slot) would somehow make things easier, unfortunately I can't. My 1080Ti is a 2.5 slot card and there isn't enough clearance between the second PCIe slot and the LSI HBA in the third PCIe slot.
-
On 8/29/2020 at 5:25 AM, mgutt said:
1.) Check the destination documentation of rclone. Every destination has its own special parameters and behaviour like Google Drive has its own, too:
2.) Do not copy/sync to the mount of the destination like /mnt/disks/gdrive. Use only the rclone alias like gdrive:subfolder. rclone does not work properly if the target is a local path. Example: If you use the mount path and your destination is a webdav server it does not presere the file modification time.
3.) If it does not preserve the file modifcation time it must use checksums to verify that the destination file is the same (or not) before being able to skip (or overwrite it). This means it downloads and calculates the checksums (high cpu usage) and uploads at the same time (rclone uses 8 parallel running --checkers for this).
4.) There are minor performance differences between sync and copy as they act a little bit different, but finally this should not influence the transfer speed of files:
sync = deletes already existing files from destination that are not present on source
copy = ignores existing files on destination
Conclusion:
Check if your transfer preserves the timestamps. If yes, then disable the checksum check through --ignore-checksum (if you are ok with that) and test different --checkers and --transfers (4 is the default) values until you reach the best performance. For example I use "--checkers 2 --transfers 1" for my Nextcloud destination as there was no benefit uploading multiple files and finally it does not raise the total transfer speed if I have two parallel uploads instead of one.
My command as an example:
rclone sync /mnt/user/Software owncube:software --create-empty-src-dirs --ignore-checksum --bwlimit 3M --checkers 2 --transfers 1 -vv --stats 10s
Thanks! I lowered the checkers to 2 and transfers to 1. Combined with a chunk-size of 256M, I get the same ~80MBps with half the CPU utilization as before, even without --ignore checksum
-
2 hours ago, Stupifier said:
The biggest issue with writing to the rclone mount is just flat out reliability. People pretty much ALWAYS complain about it. Either it gives errors, or its slow, or it doesn't copy everything you told it. Pretty much, it isn't something you'd wanna use/trust. I know its convenient......sorry.
It is such a well-known thing that there are a ton of very popular scripts around GitHub that basically monitor directories and perform regular rclone sync/copy jobs for you in the background on a regular schedule (like every 2 minutes or whatever you set). One such script is called "Cloudplow". Very well documented/mature. Easy to find on github.Now, rclone mount is absolutely remarkable as a read source. It is excellent for reading.
Just tried out "rclone copy"....the difference is night and day
Test files: 4 files (total of 12.3 GB; between 2.3-3.6GB each)
Average transfer speed using rclone mount: 19.4MB/s
Average transfer speed using "rclone copy": 60.9MB/s
Average transfer speed using "rclone copy" and chunk-size 256M: 78.1MB/s
The only drawback is heightened CPU/RAM usage but I'm sure I can manage that with a script like you mentioned.
Thanks very much for all your help!
-
10 minutes ago, Stupifier said:
https://rclone.org/commands/rclone_mount/
https://rclone.org/flags/
CTRL+F "chunk"
And FWIW, It is not the best idea to Write to an rclone Google Drive mount. Its just a widely known tip....those rclone mounts are more geared towards reads. The If you want to write something to a Google Drive remote, doing it manually using "rclone copy" command and the flags link I provided has a flag to designate chunk size.
Also, even though you have Gig FIOS connection.....you still may not saturate your connection using rclone/google. That might just be the speed you get with Google. It's different for everyone.Thanks! I'll look into the resources you posted.
As for not writing to the rclone Google Drive mount, (1) it's a slightly more widely known tip now 😅, (2) while I'll switch to using "rclone copy", is there any particular negative effect to transferring data to Google Drive in the way I've been doing (e.g. data loss/corruption) or is it just lower performance?
-
Hi, I recently set up rclone with Google Drive as a backup destination using SpaceInvaderOne's guide. While archiving some files, I noticed that my files were being uploaded at around 20MBps despite having a gigabit FiOS connection. Based on some Googling, I'm thinking increasing my chunk size might improve speeds.
But how do I go about increasing the chunk size? I've attached my rclone mount script if that's of any help.
Also, how does this affect the items I have already uploaded (if it affects them at all)?
-
3 hours ago, jonathanm said:
To expand on what @Energen said, unless you are trying to distribute the weight so that it's less concentrated in the case and instead making many lighter packages, then removing the hard drives SHOULD be unnecessary. That assumes they are mounted properly, obviously if they are only held in with one screw on a makeshift piece of scrap, then remove them. Bare hard drives are especially vulnerable to impact, the simple act of setting one bare drive on top of another can exceed the design specs for instantaneous G loading. If it made a clack noise, you probably went over the limit.
However... your heatsink should be either removed or secured. I've seen multiple instances where a heatsink came off the mounts and played pinball inside a tower. In one shipment from Alaska to the southern US, the end result was not pretty, I think the only thing salvageable was the DVD drive.
Well it'll be a seven hour drive. Personally, I'm willing to completely waste an hour of my time to gain that bit of peace of mind (even if it might be illusory 🤷♂️). Besides, what with quarantining, each hour of my time is suddenly much less valuable...
As for the heatsink, I use an AIO (probably also overkill for this use-case; but I had it left over from another build). I'm thinking that an AIO shouldn't need to be removed, as it's not a hunk of metal like a NH-D15 etc.?
-
I'm planning to move my server from my parents' house to mine.
So far I'm planning on:
- running a backup via Duplicacy and the Backup/Restore Appdata plugin (I already do this daily and weekly respectively)
- running a parity check before the move
- noting which HDD is connected to which SATA port
- removing the HDDs and expansion cards and packing them safely for the drive
- reinstalling the components post-move in the same manner they were pre-move
- running another parity check to ensure there was no damage to the HDDs as a result of the drive
A few questions:
1) Is there anything else I should be considering?
2) Currently, my server has a DHCP reservation of 192.168.x.y; the DHCP reservations at my house follow a slightly different scheme. Apart from simply creating a new reservation for the server on my router, is there anywhere within unRAID I need to manually update?
3) I run a number of reverse-proxied services on unRAID. Since I run cloudflare-ddns, I take it Cloudflare will automatically be updated with the new public IP (i.e. I don't need to do anything or reinstall LetsEncrypt etc.)?
Thanks for any help/advice!
-
19 hours ago, jonathanm said:
Depends. Well written apps will detect that a dependency isn't available and either retry or wait, then error out gracefully after a period of time. Poorly written apps may lose or corrupt data.
I've never had an issue with my specific set of containers, but ymmv.
When you say "well-written", do you mean on the part of the container creator or the underlying service? For example, I generally prefer to use the Linuxserver variant of a given container. Presumably, those would count as well-written?
Also, with regards to data loss, I imagine that depends on whether data is actively being written (e.g. my Nextcloud and Bookstack containers are usually NOT writing data whereas my telegraf container is constantly writing to InfluxDB)?
In any case, since I'm certainly not knowledgeable enough to know if an app is well written, I suppose I'll stick with my existing protocol of stopping all affected containers before updating. Small price to pay for peace of mind...
-
I have a few instances where Docker containers work in combination (e.g. Nextcloud and Bookstack each work with mariadb; Telegraf, InfluxDB and Grafana all work together etc).
When there is a update for one or more of these Docker containers, is there a recommended way to update (e.g. stop everything, update everything, then restart in a specific order)? Or can I just update any individual container as and when I please without stopping any other "upstream" or "downstream" containers?
-
On 4/15/2020 at 6:00 AM, bonienl said:
The way it is implemented in 6.8 and later, is that the passphrase is no longer stored in a file, but internally cached by the emhttpd process.
This makes the passphrase invisible/non-retrievable once entered at startup of the array.
When using a keyfile, this file is copied to /root prior to starting the array. The option exists to delete the file from /root after the array is started/
My standard disclaimer: I only know enough to break things that I don't know how to fix...
I've written my go file such that at boot, I get my array passphrase via AWS Secrets Manager and write it to /root/keyfile. unRAID then uses /root/keyfile to unlock/startup my array. I've been manually deleting my keyfile after startup.
The aws-cli command I use for the procedure above retrieves a string, not a file. So, is it possible to use the output of this command as the passphrase rather than writing it to a keyfile first?
Thanks!
-
Anyone have any ideas?
-
Wasn't really sure which sub-forum to post this in, but here goes:
I setup the trio of Telegraf+InfluxDB+Grafana recently and noticed the following curious behavior from my GPU:
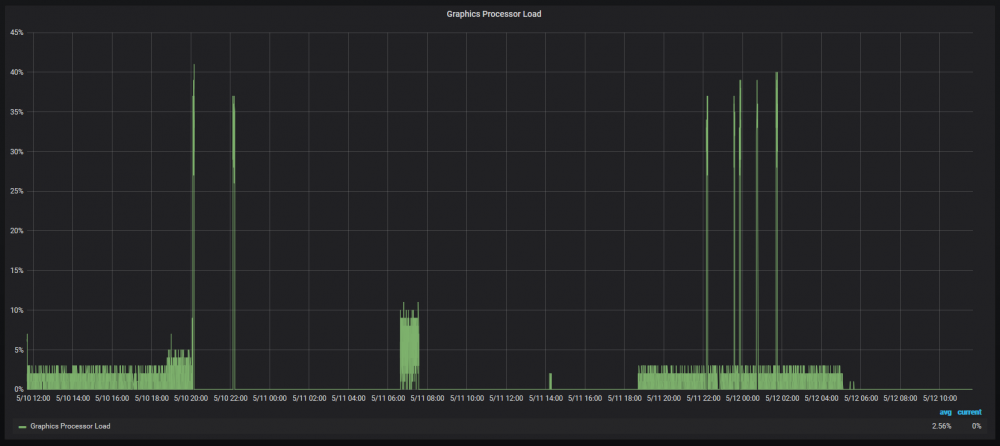
I installed my GPU almost a year ago. At idle, the GPU usage was obviously 0% with fan usage ~50%. The GPU statistics plugin confirmed as much.
However, since I set up Telegraf et al. a week or so ago, "idle" GPU usage hovers between 2-5% with fan usage at ~65% for extended periods. Upon checking nvidia-smi, it reports "no running processes". The issue also appears to go away on its own.
Any idea what could be causing this behavior? Admittedly, it doesn't seem to be affecting transcoding results in any way. But it's just weird that I'm seeing sustained, albeit low, GPU and fan utilization despite "no running processes".
I didn't notice this behavior before setting up Telegraf etc. (i.e. when I only had GPU statistics plugin installed). That said, I'm pretty sure that all Telegraf did was alert me to an existing issue.
-
My standard disclaimer: I only know enough to break things that I don't know how to fix...
Question 1:
I've written my go file such that at boot, I get my array passphrase via AWS Secrets Manager and write it to /root/keyfile. unRAID then uses /root/keyfile to unlock/startup my array. I've been manually deleting my keyfile after startup.
Can I just add the following to the go file to automatically delete the keyfile 5 minutes after startup:
sleep 300s shred /root/keyfileOr should I just write a user script with the above commands via the User Scripts plugin to be executed after Array start?
Question 2:
From what I've managed to glean from the forums, in unRAID 6.8+, passphrases seem to be more secure than keyfiles as passphrases are not written to a visible-to-user file (even ones that only exist in RAM). The aws-cli command I use for the procedure above retrieves a string, not a file. So, is it possible to use the output of this command as the passphrase rather than writing it to a file first?
Thanks!
-
38 minutes ago, atribe said:
Probably the cost of switching the repo. See the bottom left of you screenshot? Libray/telegraf. You customized it. You might be able to go into the file system where that template info is stored and put the icon there.
Thanks!
EDIT: Solved both issues as described in my post above.
-
14 hours ago, saarg said:
Blank page is usually an add-on blocking something.
@saarg Thanks! uBlock Origin was the culprit. Apparently, it's not a fan of duckdns.org?
I had planned to switch from duckdns to cloudflare-ddns anyway. After doing so, the site is working properly in Firefox with uBlock Origin still enabled.
-
I recently set up Telegraf+InfluxDB+Grafana (+HDDTemp).
In order to get Nvidia GPU stats, I changed my telegraf repository from alpine to latest. Life was good.
However, I've just noticed that, in the Docker tab of unRAID, the Telegraf icon is missing and the docker container name is no longer a link to edit the template. If I click the docker icon, I only have the options of Console, Start, Stop, Pause, Restart, and Remove.

My Grafana dashboard is still populating properly. So, Telegraf still appears to be doing its job.
That said, can anyone help me figure out what I broke? Or is this just the price of switching the repository (I would switch back to confirm this but as stated, I can't edit the template)?
EDIT: Found the problem...somehow the my-telegraf.xml file at /boot/config/plugins/dockerMan/templates-user was deleted. Not a clue how that happened as I don't make a point of rooting around in /boot unnecessarily. In any case, thanks to the CA Backup/Restore Appdata plugin, I copied the file back to /boot. A refresh of the Docker tab shows I'm back to normal (icon and all).








[Support] Tailscale Support Thread
in Docker Containers
Posted
I followed the IBRACORP guide to setting up Tailscale. I then tried accessing the unRAID web UI from my iPhone to test after turning off WiFi.
When on LTE and connected to Tailscale, I can successfully ping 100.x.y.z. When I try to navigate to 100.x.y.z in Safari, I get redirected to "xxxxx.unraid.net". But, the request times out before I can actually access the login page.
I deleted the My Servers plugin from unRAID and turned off SSL for the web UI in Settings/Management Access. And then I was able to access the unRAID dashboard on my phone via Tailscale while on LTE.
My questions are:
1) Is turning off SSL for the web UI required to be able to access the dashboard via Tailscale? If not, I'd be interested to hear if you had to do anything special to get the web UI SSL and Tailscale to play nicely together.
2) Assuming I only access the web UI remotely via Tailscale (i.e. NOT via exposing directly to internet or reverse proxy), is using SSL on the web UI even necessary?
3) Would I be missing out on something by not using SSL (other than a nice lock icon in the browser)? Is there any appreciable security risk (either in theory or in practice)?
Thanks!