

Arcaeus
-
Posts
172 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Arcaeus
-
-
Hello,
I have PiHole running in a small Ubuntu VM on my Unraid server (6.12.4) and have run out of space on the root vdisk. As I was watching the SpaceInvaderOne video that was in the guides section of the forum, after he showed how to increase the disk size in the Unraid GUI, he talked about extending the partition (although his video showed Windows).
I looked up a guide on how to do it in Linux, but it shows that I would have to unmount the disk first. Since this is the root disk that the OS and everything is running off of, I can't unmount it, and I can't change anything if the VM is shut down of course.
So, how would I go about increasing the partition size? Or clone this disk to a larger one?
-
Yep, dead drive. switched connections and no dice. I'll order and install one, thanks for your help.
-
 1
1
-
-
40 minutes ago, JorgeB said:
If you've really power cycled the server, and not just rebooted, disk might be dead, but it's worth first swapping slots with a different one to confirm.
Ok server has been shut down completely, then rebooted. These are the diags from that. Disk still not showing in UD.
-
Ah, apologies I misunderstood. I just rebooted, so I'll do a full shutdown then post the diags when it starts back up.
-
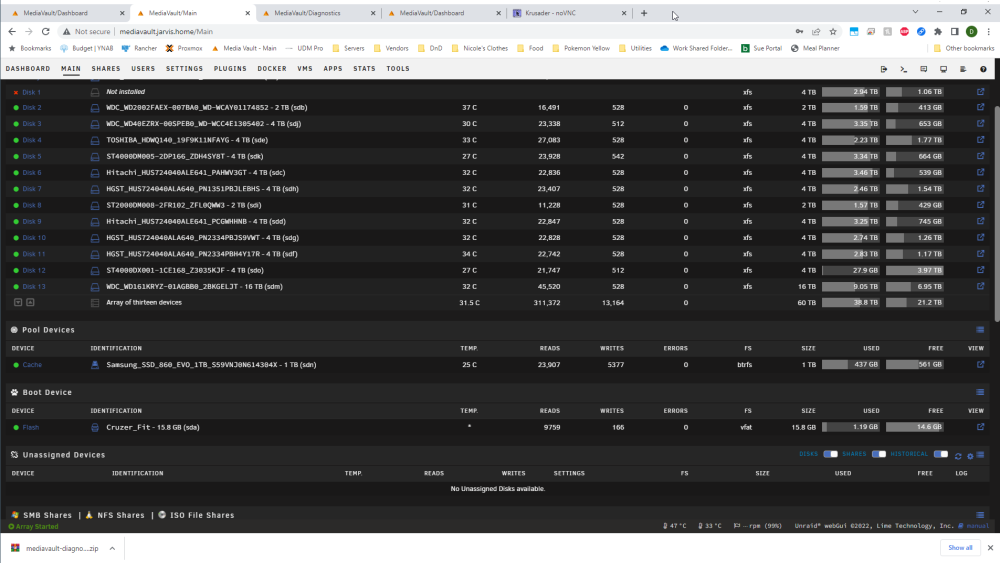
Power cycled server, new diags are posted. sdi is showing in the CLI when the server was booting up, but not showing up in UD:
-
Hello,
Woke up this morning to my disk1 showing as disabled. I've had no issues with it for the last few months and haven't touched any of the cables. My server is currently in a server rack in the basement so highly unlikely that it got bumped or anything. Checking the disk log information, I'm seeing a lot of bad sectors (log attached). I stopped the array and unassigned the disk, then when trying to re-assign it the disk was not in the drop down menu.
Looking through some previous posts on here, I think the disk may be dying. Attempting to run a smart report immediately fails (whether it was in the array or not) and iirc that is one of the older disks in the array. Diags attached below are from when the array was stopped.
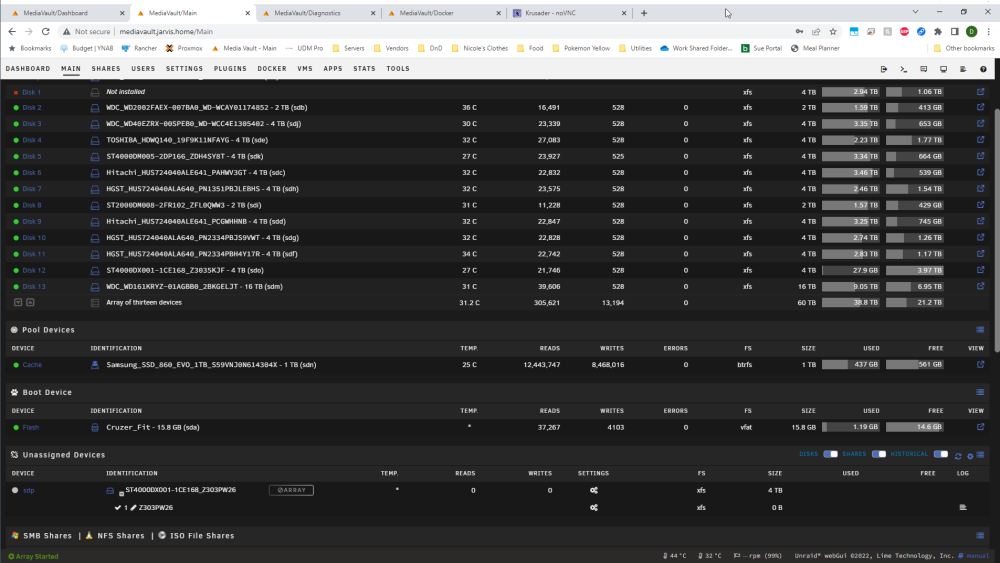
I started the array with the disk removed, and the files from disk1 are emulated. Diags from running array are also attached. It looks like the disk (sdp) in UD is unmountable or otherwise can't be added to the array?
I had some other disk show similar errors in the past which ended up being some data corruption. I wanted to just check with you guys to see if there was anything I could do before replacing the disk, or if there was a way to get this disk back up and running. Even if this disk can be fixed, should I be looking into replacing it anyways as it's already on its way out?
log.txt mediavault-diagnostics-20221212-1045.zip [array-started] mediavault-diagnostics-20221212-1045.zip
-
Hey there,
I'm trying to get your DayZ container running on my k3s cluster. It's up and running well, and just had a question on modding the server.
Where do I put the mod files that I've downloaded from the Steam Workshop? I've seen documentation from Nitrado for setting up mods on their servers that say to put it in the main parent game folder. I see that your container has an addons folder already, so do I take all the .pbo and .bisign files for each mod and throw them in there, then put the respective "keys" files in the keys folder?
Do you have any documentation on how to do this?
-
2 minutes ago, JorgeB said:
Yes, the mover will never overwrite any files, you need to delete one of the copies.
Ok sweet. And deleting the appdata folders is all good? Or is that going to screw with the like 'previously installed apps' thing of CA?
-
Hello,
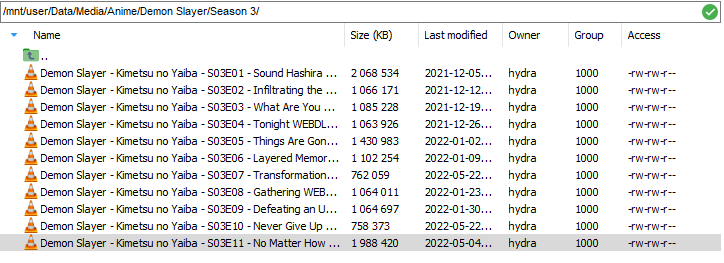
I have certain folders in the Media share are staying on the cache drive after Mover has ran. Everything else has no problem moving off of the cache disk to the array, except for these folders. I believe it is because the same file already exists on the array so Mover is skipping it or something. If I look in /mnt/user0 vs. /mnt/user vs. /mnt/cache, I can find the same file in the same folder structure (see attached screenshots).
Media share is set to Cache:Yes
File permissions of cache folders almost match folders on array, and the user0 file is owned by 'nobody' instead of the rest being 'hydra'
Is there any issue with me deleting the files off of the cache drive directly via CLI/Krusader? Or what is the best way to resolve this?
While I'm in here, I see folders in /mnt/cache/appdata of containers that I've since deleted. Can I delete that appdata folder if I know I'm never going to use that again? Or is there a better way to clean that up?
Diags attached.

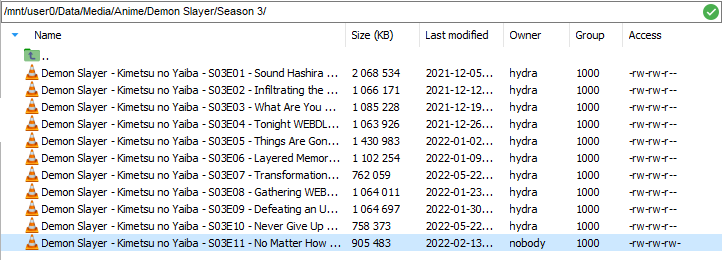
-
16TB drive is in and parity is rebuilding. This time I put "no disk" on parity, then selected the 16TB. Guess it just got hung up somewhere.
Thanks for your help.-
1
-
-
Alright looks like we're back online. Do I have the process right or is there something else I should be doing?
-
Hello,
I recently got a pair of 16TB WD Golds and wanted to put one as my parity disk (upgrading from a 4TB) and then once that is completed, add in the other 16TB as a data disk plus move the old 4TB as another data disk. I have precleared both 16TB disks and had them mounted in unassigned devices as a local backup while I was figuring out some file system issues and waiting for my cloud backup to finish.
Searching through the forum I found this process from @Squid which states:
QuoteStop the array
Assign the 12TB as parity drive
Start the Array and let it build the parity drive
After that's done, stop the array and add the original 8TB as a data drive 5. Unraid will clear it in the background and when that's done (hours), then the storage space is available.
The standard way does give you a fall back, as the original parity drive is available for you to reinstall if something terrible goes wrong.
I stopped the array and in Main clicked to select the 16TB disk to replace the existing parity drive. Once I did, the screen changed and now none of the disks are showing up:
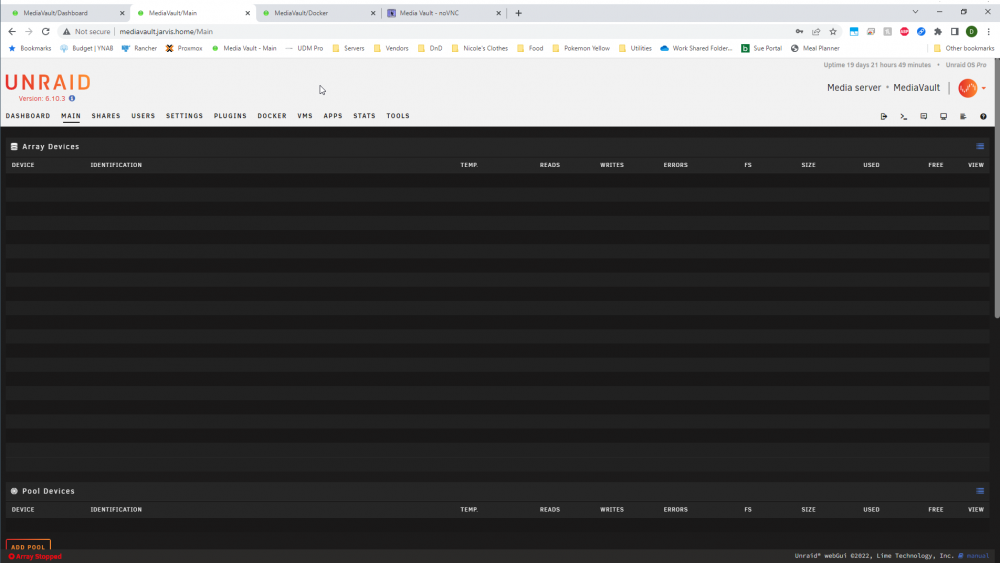
Refreshing the page does nothing, and switching back and forth to another page does nothing. Trying to open the log in the top right shows the window for a second and then closes without displaying any info. The unassigned devices section on main is just spinning with the wavy Unraid logo. Attempted to download diagnostics file, but it's just sitting there after clicking download.
I wanted to post in here before I did anything else to not potentially mess something up. Thanks for your help.
Unraid Pro v6.10.3
SOLUTION: This ended up being a DNS issue. I run PiHole as an Ubuntu VM on Unraid, as use that for local DNS resolution. When I stopped the array, it shut down the VM so Unraid would only display the cached webpage data. Once I changed the DNS info on Windows and went to the IP address of my server, the problem resolved itself.
-
Recently I have set up some Proxmox VMs that use an Unraid NFS share as their main disk. On Unraid 6.9.2, having the 'Support Hard Links'=Yes would cause stale file handle errors when Mover ran (from what I can determine) on Proxmox and in the VMs, causing them to crash or need a hard reboot. Since turning that to 'no', they've been fine.
However, I am in the process of setting up Sonarr and Radarr and in diagnosing some issues their documentation recommends Hard Links to be enabled. Has this issue been resolved in the new 6.10.2 version? Or is that something to do with Unraid itself?
-
Hello everyone,
I have 5 NFS shares coming from my Unraid server into my Proxmox cluster of 4 nodes (named Prox-1 through 4 respectively). These shares are:
- AppData
- Archives
- Backups
- ISOs
- VM-Datastore
They connect on Proxmox fine, but the "Backups" share will error out partway through a backup operation run on Proxmox, and the Archives share will randomly disconnect. Attached are the backup operation logs for a couple of the VMs. As you can see, the write info goes to zero after a point and generally stays there.
I've posted over there as well, but wanted to check with you guys to confirm that it's not something on the Unraid side causing issues.
Is Unraid erroring out? or is something being overloaded? Diags attached if needed.
VMID 100 backup error log.txt VMID 201 backup error log.txt fstab and config.cfg info.txt mediavault-diagnostics-20220511-1439.zip
-
Had corruption in my array. Once that was fixed and the array restarted, the shares returned.
-
This has been resolved. One of my drives had been disabled and once that was back up it started working.
-
12 minutes ago, JorgeB said:
Just restart the array, parity is valid.
Ok array is started with disk 7 mounted now, thank you. It looks like there are a lot of files in the lost+found folder, and Main - Array also shows a lot of free space on the disk, much more than was there before.
What's my next step? Do I need to go through lost+found on the drive and move files back to where they should be or will Unraid put back what was there before? Or do it from the lost+found share? I know moving files from a specific disk was not recommended on Unraid but not sure if that applies here.
-
12 minutes ago, JorgeB said:
Run it again without -n and without -L, if it didn't finish before and asks for -L again use it.
Ok it looks like it completed, here is the output:
root@MediaVault:~# xfs_repair -v /dev/md7 Phase 1 - find and verify superblock... - block cache size set to 542384 entries Phase 2 - using internal log - zero log... zero_log: head block 0 tail block 0 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... XFS_REPAIR Summary Tue May 10 11:15:48 2022 Phase Start End Duration Phase 1: 05/10 11:15:48 05/10 11:15:48 Phase 2: 05/10 11:15:48 05/10 11:15:48 Phase 3: 05/10 11:15:48 05/10 11:15:48 Phase 4: 05/10 11:15:48 05/10 11:15:48 Phase 5: 05/10 11:15:48 05/10 11:15:48 Phase 6: 05/10 11:15:48 05/10 11:15:48 Phase 7: 05/10 11:15:48 05/10 11:15:48 Total run time: doneWhat's next? Restart the array and rebuild parity?
-
17 minutes ago, JorgeB said:
Use -L
Ok ran it with that flag, but my computer (not Unraid Server) crashed midway through and killed the SSH session. Is there a way to check on the progress? Maybe run the same command but with the -n flag to check?
-
Restarted system while working on another issue and the shares are showing up again? Why would they randomly disappear?
-
Just now, JorgeB said:
No need to rebuild since the disk is enable, but you do need to run xfs_repair without -n to fix the current corruptions.
Attempted to repair the file system as I was getting local errors on the monitor attached to the bare metal computer. When trying to run 'xfs_repair -v /dev/md7' received this error:
root@MediaVault:~# xfs_repair -v /dev/md7 Phase 1 - find and verify superblock... - block cache size set to 542376 entries Phase 2 - using internal log - zero log... zero_log: head block 159593 tail block 159588 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.Restarted the array regularly, and now disk 7 is showing 'Unmountable: not mounted' in Main - Array (attached).

-
On 5/6/2022 at 12:46 PM, JorgeB said:
Correct.
Hey Jorge, I'm trying to figure out some share errors that aren't showing up now. When I ran 'ls -lah /mnt' it's showing question marks for disk 7 despite it showing ok in Main:
root@MediaVault:~# ls -lah /mnt /bin/ls: cannot access '/mnt/disk7': Input/output error total 16K drwxr-xr-x 19 root root 380 May 6 10:54 ./ drwxr-xr-x 21 root root 480 May 10 09:58 ../ drwxrwxrwx 1 nobody users 80 May 6 11:04 cache/ drwxrwxrwx 9 nobody users 138 May 6 11:04 disk1/ drwxrwxrwx 8 nobody users 133 May 7 16:10 disk10/ drwxrwxrwx 5 nobody users 75 May 7 16:10 disk11/ drwxrwxrwx 6 nobody users 67 May 6 11:04 disk2/ drwxrwxrwx 9 nobody users 148 May 6 11:04 disk3/ drwxrwxrwx 4 nobody users 41 May 6 11:04 disk4/ drwxrwxrwx 10 nobody users 166 May 6 11:04 disk5/ drwxrwxrwx 7 nobody users 106 May 6 11:04 disk6/ d????????? ? ? ? ? ? disk7/ drwxrwxrwx 6 nobody users 73 May 7 16:10 disk8/ drwxrwxrwx 6 nobody users 67 May 6 11:04 disk9/ drwxrwxrwt 5 nobody users 100 May 6 13:41 disks/ drwxrwxrwt 2 nobody users 40 May 6 10:52 remotes/ drwxrwxrwt 2 nobody users 40 May 6 10:52 rootshare/ drwxrwxrwx 1 nobody users 138 May 6 11:04 user/ drwxrwxrwx 1 nobody users 138 May 6 11:04 user0/I ran the file system check on disk 7 and got this output:
entry ".." at block 0 offset 80 in directory inode 282079658 references non-existent inode 6460593193 entry ".." at block 0 offset 80 in directory inode 282079665 references non-existent inode 4315820253 entry "Season 1" in shortform directory 322311173 references non-existent inode 2234721490 would have junked entry "Season 1" in directory inode 322311173 entry "Season 2" in shortform directory 322311173 references non-existent inode 4579464692 would have junked entry "Season 2" in directory inode 322311173 entry "Season 3" in shortform directory 322311173 references non-existent inode 6453739819 would have junked entry "Season 3" in directory inode 322311173 entry "Season 5" in shortform directory 322311173 references non-existent inode 2234721518 would have junked entry "Season 5" in directory inode 322311173 entry "Season 6" in shortform directory 322311173 references non-existent inode 4760222352 would have junked entry "Season 6" in directory inode 322311173 would have corrected i8 count in directory 322311173 from 3 to 0 entry ".." at block 0 offset 80 in directory inode 322311206 references non-existent inode 6453779144 entry ".." at block 0 offset 80 in directory inode 322311221 references non-existent inode 6460505325 No modify flag set, skipping phase 5 Inode allocation btrees are too corrupted, skipping phases 6 and 7 No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Tue May 10 10:06:15 2022 Phase Start End Duration Phase 1: 05/10 10:06:11 05/10 10:06:11 Phase 2: 05/10 10:06:11 05/10 10:06:11 Phase 3: 05/10 10:06:11 05/10 10:06:15 4 seconds Phase 4: 05/10 10:06:15 05/10 10:06:15 Phase 5: Skipped Phase 6: Skipped Phase 7: Skipped Total run time: 4 secondsIs there any reason to not run the file system check without the -n flag now? After that completes would I rebuild the drive like we did before or how does that work?
New diags attached if needed.

-
I have Unraid exporting a few NFS shares to my Proxmox cluster, which are:
- Archives
- appdata
- ISOs
- Proxmox-VMs
- Proxmox-Backups
Recently I've been having issues with the shares disconnecting on Proxmox. Research indicated that there was an issue with Mover, that when it runs it disconnects the NFS shares on Proxmox. So I made some of these shares either completely use the cache disk or never use it, 'Proxmox-VMs' being an example of the former and 'Proxmox-Backups' an example of the latter. I set up these shares, connected them to Proxmox, and they worked great.
I checked them now after 24 hours and the Backups, ISOs, and VMs shares are disconnected in Proxmox. Archives and appdata are still connected no problem despite coming from the same location. When I check on the Unraid Dashboard, the shares are gone (see attached). However, when I open up the files on the cache disk, I see the 'Proxmox-VMs' folder right there.
What would be causing these to not show up as shares?
Diags attached.


-
Hey binhex,
I just updated my HBA card firmware to the latest version and fixed some disk issues (noted in this thread: https://forums.unraid.net/topic/123025-chasing-down-disabled-drive-crc-errors/#comments) and now I'm receiving IO errors in SABnzbd:
Failed making (/data/usenet_incomplete/*****) Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/filesystem.py", line 719, in create_all_dirs os.mkdir(path_part_combined) OSError: [Errno 5] Input/output error: '/data/usenet_incomplete/*****'I changed nothing on my docker config or folders,and tried deleting and reinstalling the container (loading from template). When trying to change the file permissions in Krusader, it will just error out on a specific folder and wont let me move it elsewhere either.
SABnzbd error log attached. Let me know what else you may need.












Increase root disk size on Linux
in VM Engine (KVM)
Posted · Edited by Arcaeus
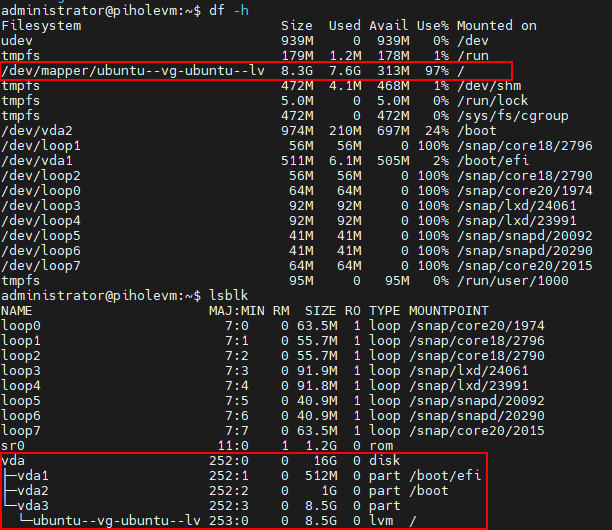
Ok, figured it out. Here is what worked for me:
df -hlsblklvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lvresize2fs /dev/mapper/ubuntu--vg-ubuntu--lv