

Dmtalon
-
Posts
160 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Dmtalon
-
Thanks for this... I've gone out and tried to figure a way to get my MBA M1 to print to my Brother MFC, never managing to get it working until tonight after installing this Docker. Pretty straight forward setup.
-
 Good evening all, I've just gotten a notice of a parity check running as well as a notice from fix common problems that errors were found (on my phone). Server is pretty new, however has been ROCK solid since going live. Replaced old hardware about 10 months ago. The fix common problems suggest installing 'mcelog' via NerdPack which I *just* did. So, I guess if it happens again I'll have additional logging. Server's been back up for ~2h now, all green dots, and parity hasn't found any errors yet. My signature has my current build specs. That said, I do see the following in the syslog, but that appears to have appeared *at* boot, and not the cause? I assume the logs were wiped at reboot which is what the mcelog will protect if this happens again? Mar 15 19:01:13 NAS1 kernel: ACPI: Early table checksum verification disabled Mar 15 19:01:13 NAS1 kernel: IOAPIC[0]: apic_id 25, version 33, address 0xfec00000, GSI 0-23 Mar 15 19:01:13 NAS1 kernel: IOAPIC[1]: apic_id 26, version 33, address 0xfec01000, GSI 24-55 Mar 15 19:01:13 NAS1 kernel: Kernel command line: BOOT_IMAGE=/bzimage initrd=/bzroot Mar 15 19:01:13 NAS1 kernel: Memory: 65630376K/67017592K available (10242K kernel code, 1183K rwdata, 2348K rodata, 1120K init, 1596K bss, 1386960K reserved, 0K cma-reserved) Mar 15 19:01:13 NAS1 kernel: Console: colour VGA+ 80x25 Mar 15 19:01:13 NAS1 kernel: Calibrating delay loop (skipped), value calculated using timer frequency.. 7585.67 BogoMIPS (lpj=3792837) Mar 15 19:01:13 NAS1 kernel: smpboot: CPU0: AMD Ryzen 9 3900X 12-Core Processor (family: 0x17, model: 0x71, stepping: 0x0) Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: Machine check events logged Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 7: bea020000004017b Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: TSC 0 ADDR 100a05f20 MISC d012000500000000 SYND 9e3f1d470707 IPID 700b020350000 Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: PROCESSOR 2:870f10 TIME 1647385258 SOCKET 0 APIC 0 microcode 8701021 Any help / advice would be greatly appreciated. nas1-diagnostics-20220315-2049.zip
Good evening all, I've just gotten a notice of a parity check running as well as a notice from fix common problems that errors were found (on my phone). Server is pretty new, however has been ROCK solid since going live. Replaced old hardware about 10 months ago. The fix common problems suggest installing 'mcelog' via NerdPack which I *just* did. So, I guess if it happens again I'll have additional logging. Server's been back up for ~2h now, all green dots, and parity hasn't found any errors yet. My signature has my current build specs. That said, I do see the following in the syslog, but that appears to have appeared *at* boot, and not the cause? I assume the logs were wiped at reboot which is what the mcelog will protect if this happens again? Mar 15 19:01:13 NAS1 kernel: ACPI: Early table checksum verification disabled Mar 15 19:01:13 NAS1 kernel: IOAPIC[0]: apic_id 25, version 33, address 0xfec00000, GSI 0-23 Mar 15 19:01:13 NAS1 kernel: IOAPIC[1]: apic_id 26, version 33, address 0xfec01000, GSI 24-55 Mar 15 19:01:13 NAS1 kernel: Kernel command line: BOOT_IMAGE=/bzimage initrd=/bzroot Mar 15 19:01:13 NAS1 kernel: Memory: 65630376K/67017592K available (10242K kernel code, 1183K rwdata, 2348K rodata, 1120K init, 1596K bss, 1386960K reserved, 0K cma-reserved) Mar 15 19:01:13 NAS1 kernel: Console: colour VGA+ 80x25 Mar 15 19:01:13 NAS1 kernel: Calibrating delay loop (skipped), value calculated using timer frequency.. 7585.67 BogoMIPS (lpj=3792837) Mar 15 19:01:13 NAS1 kernel: smpboot: CPU0: AMD Ryzen 9 3900X 12-Core Processor (family: 0x17, model: 0x71, stepping: 0x0) Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: Machine check events logged Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: CPU 0: Machine Check: 0 Bank 7: bea020000004017b Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: TSC 0 ADDR 100a05f20 MISC d012000500000000 SYND 9e3f1d470707 IPID 700b020350000 Mar 15 19:01:13 NAS1 kernel: mce: [Hardware Error]: PROCESSOR 2:870f10 TIME 1647385258 SOCKET 0 APIC 0 microcode 8701021 Any help / advice would be greatly appreciated. nas1-diagnostics-20220315-2049.zip -
Old HW unRAID Pro: 6.8.3 | FLASH: Sandisk 4GB Cruiser Fit | CASE: Rosewill RSV-L4411 | MOBO: Asus Sabertooth 990FX R2.0 | CPU: AMD FX-8320 Black | MEMORY: Crucial 8GB DDR3 10600 ECC x3 | VIDEO: XFX ATI HD5450 PCIe | AUDIO: Casatunes XLI (Creative HD PCIe) | CACHE|APP DRIVE: Samsung 860 EVO 1TB SSD | PARITY DRIVE: 4TB WD Red| DATA DRIVES: 5x2TB WD Greens + 2x4TB WD Reds New HW: Asus TUF x570-Plus, Ryzen 9 3900X, Kingston 64GB ECC Ram, Nvidia P400 GPU, M.2 Samsung cache drive (and original plan, a new Samsung Bar Plus USB) I spent the last week or so running new hardware on trial key, mem testing, passing through GPU to plex (Nvidia Drivers) etc.. Just general checking/running. Started the swap last night, moved all the new HW into my rack case, with the original Flash drive. But no matter what, I received the below error while booting. (I tried bring the flash drive up to my PC, scanning it, putting it in a different usb slot) I don't boot UEFI, and one thing I did was take off the - in the EFI name folder, but I forgot to try UEFI on the original usb. I didn't want to boot UEFI so I guess I just forgot. So, next... Since I'd tested the new Samsung in the temporary case, and had planned to swap it in to replace my old USB anyway (just not at first boot). I restored my flash backup onto it and attempted to boot it. All I got was that standard message saying it's not a boot device, replace it and hit any key to continue. (this USB had booted on this MB earlier in the week). I did run make_bootable. I tried reformatting it, reinstalling unRAID, running make_bootable and nothing. It just would not boot. Now, while not in full panic, I was not in a good place. I've got random flash drives all over so I took the one I was actually using with the trial key (USB 2.0 8gb PNY of unknown age but certainly not new) which already had 6.9.2 on it. I just copied my backed up config folder over to it. This drive booted up, and of course had my pro.key. I validated all the drives were in the right slots, transferred the license to this old PNY drive, and started the array. On the bright side, the physical swap went smooth, everything came up (dockers/ VMs). My windows 10 VM seems to even still be activated which I won't complain about. Parity check is at 83% with no errors. So that is all good Googling the above Initramfs above wasn't turning up much help at all, and since it was pretty late (11-11:30pm) I didn't spend a ton of time trying to figure it out. I don't think I had any hits with that error from this forum unfortunately. In any case, I'm running on all new HW with an unknown old PNY USB drive. Once the Parity check finishes, and everything it stable, I'll swap my old SSD cache drive onto the M.2. and be done for a while I hope.

-
Anyone here running this docker successfully? I've got a PC running beside my current OLD unRAID build, but was considering trying to use this on my new build (AMD FX chip from 2014) to a Ryzen 9 3900x (testing now) Would be nice to move BI into unraid and decommission the extra PC, but I don't see a lot of talk in here. Also, can the latest BI.exe be moved in to keep it updated?
-
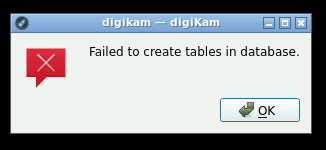
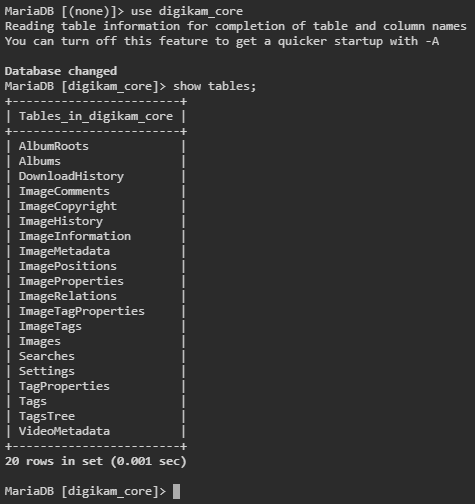
Anyone get this working using mysql remote (MariaDB)? I keep getting "Failed to create tables in database" I've tried using the suggested single database (selecting defaults fills the 4 databases with the name digikam) and I just tried naming them separately by using digikam_core, digikam_face etc... The database connection test passes, and database tables are created, but then I get the message. My latest attempt did create tables in digikam_core the other ones blank (digikam_thumbs, digikam_face, and digikam_similar). When I used the same db "digikam" for all 4 database the same 20 tables were created.
-
I don't understand this reply? I had a docker update and it is now no longer starting with the same error(s) EDIT: Neverminded. I found the post above that shows how to fix. 2021-03-30 13:18:28.402298 [info] WEBUI_CONSOLE_TITLE defined as 'Minecraft Java' 2021-03-30 13:18:28.442013 [info] CUSTOM_JAR_PATH not defined,(via -e CUSTOM_JAR_PATH), defaulting to '/config/minecraft/minecraft_server.jar' (Mojang Minecraft Java) 2021-03-30 13:18:28.479940 [info] JAVA_VERSION not defined,(via -e JAVA_VERSION), defaulting to '8' '/usr/lib/jvm/java-8-openjdk/jre' is not a valid Java environment path
-
Well, what do ya know. I could have fixed this by actually swapping the right cable on try #1. In a lame attempt to redeem myself, the cables I use are hard to get off when there's two because of the metal clips. Both popped off at the same time, causing me to somehow lose track of the right cable. I have no excuse, lame or otherwise, as to why I didn't verify once I moved it <sigh> Thanks @johnnie.black root@:~# fstrim -v /mnt/cache /mnt/cache: 820.5 GiB (880946581504 bytes) trimmed
-
oh man... maybe I moved the wrong cable. I'll walk back down there. I hope that's it, but what a silly mistake.
-
Recently upgraded to 6.8.0 (12/28) I have had The "Dynamix SSD Trim" plugin installed for a long time w/o any issues/email warnings. Since the install of 6.8.0 I've started getting the error message in the subject. fstrim: /mnt/cache: the discard operation is not supported The only recent hardware changes was adding an external controller card so I could expand unRAID by adding two more drives. I did not move the Cache SSD to the external controller, so it should not have been impacted at least AFAIK. As a troubleshooting step I had one free port on the MB controller so I swapped my Cache SSD to that, but no change in error. Just for information, the card I bought is: https://www.ebay.com/itm/162958581156?ViewItem=&item=162958581156 (but only two 4TB Red's attached). This was installed ~1mo before upgrading to 6.8.0 from 6.7.2 Cache/App Drive is a Samsung 860 1TB The Motherboard has 6 Brown SATA and two Grey SATA connectors. The SSD was connected to the ASmedia Grey, but currently I swapped it to the Brown. AMD SB950 controller : 6 x SATA 6Gb/s port(s), brown Support Raid 0, 1, 5, 10 ASMedia® PCIe SATA controller : 2 x SATA 6Gb/s port(s), gray 2 x eSATA 6Gb/s port(s), red, I am attaching diagnostics, however the server was just rebooted, and I attempted to run the fstrim command manually after the starting it back up. Any help would be appreciated. diagnostics-20200113-1336.zip

-
I'd already started that process just to see. It appears it did not change anything. ~# fstrim -v /mnt/cache fstrim: /mnt/cache: the discard operation is not supported
-
my SSD is definately not plugged into the external. I just verified. It's plugged into 1 of the two SATA ports labeled as "ASMedia® PCIe SATA controller". I'm 99.85% sure I didn't touch any existing drives when installing the card. Just for the two new 4TB Red's I added. I have 1 spot open on the other set labeled "AMD SB950 controller : 6 x SATA 6Gb/s port(s), brown" I could swap too.
-
This may or may not be related, but it seems since installing 6.8.0 (12/27). I have been getting the following email from unRAID. fstrim: /mnt/cache: the discard operation is not supported I have had the Dynamix SSD Trim for some time w/o issues. Could anything related to 6.8.0 cause this? The only other thing I've done to my server recently is install this expansion card to add two more HDD's but I did not move my SSD off the MB controller. https://www.ebay.com/itm/162958581156?ViewItem=&item=162958581156

-
[DEPRECATED] Linuxserver.io - Rutorrent
Dmtalon replied to linuxserver.io's topic in Docker Containers
look back like 3 posts on how to roll back. Something in the latest release(s) removed unpack portion of the settings. Also for those that want to roll back DO NOT copy/paste that tag into Repository, type it in. Copy/Paste (at least for me) broke this docker. Clearly something was getting captured in the copy. -
I actually do for the HDD's but I don't an enclosure for my SSD to slide it into one of them so it's inside the case
-
OK, this is why I hate opening my unRAID case It appears that this was just cabling. I have again swapped a cable and double/triple checked everything was fully seated. Re-seated the HDD's, and booted up. Been up for about 40 minutes w/o any SATA errors/issues. Lets hope this continues. Thanks for the insight/help.
-
Oh wait... I guess I might be confused here what is what (looking at my own diagnostic I see my SSD is ATA10)
-
I moved the SATA to the empty port on the Asmedia controller Attached latest diagnostic nas1-diagnostics-20181204-1052.zip
-
Ack, I didn't even notice I had ATA9 in there. I was copying/pasting and managed to overlook that. The current connectors have fat heads and are pushing the release spring of the bottom cable. SO I swapped in two of the original ones for the bottom and replaced the SSD with a third brand cable and moved it to the ASMedia port that was open. I think I got a clean boot!! I also took this time to look up and see there was a newer BIOS for my MB, and updated that while I was at it. Why not The highest messages I got on this boot were yellow/orange warnings, no errors and not related to SATA. Dec 4 05:12:32 NAS1 kernel: ACPI: Early table checksum verification disabled Dec 4 05:12:32 NAS1 kernel: ACPI BIOS Warning (bug): Optional FADT field Pm2ControlBlock has valid Length but zero Address: 0x0000000000000000/0x1 (20170728/tbfadt-658) Dec 4 05:12:32 NAS1 kernel: acpi PNP0A03:00: _OSC failed (AE_NOT_FOUND); disabling ASPM Dec 4 05:12:32 NAS1 kernel: floppy0: no floppy controllers found Dec 4 05:12:32 NAS1 kernel: random: 7 urandom warning(s) missed due to ratelimiting Dec 4 05:12:33 NAS1 rpc.statd[1659]: Failed to read /var/lib/nfs/state: Success Dec 4 05:12:37 NAS1 avahi-daemon[2809]: WARNING: No NSS support for mDNS detected, consider installing nss-mdns! AND... There it is again. While typing up this message ATA1 (SSD) just barked again. <sigh> Dec 4 10:18:53 NAS1 kernel: ata1.00: exception Emask 0x10 SAct 0x0 SErr 0x400000 action 0x6 frozen Dec 4 10:18:53 NAS1 kernel: ata1.00: irq_stat 0x08000000, interface fatal error Dec 4 10:18:53 NAS1 kernel: ata1: SError: { Handshk } Dec 4 10:18:53 NAS1 kernel: ata1.00: failed command: WRITE DMA EXT Dec 4 10:18:53 NAS1 kernel: ata1.00: cmd 35/00:40:d0:a6:37/00:01:04:00:00/e0 tag 16 dma 163840 out Dec 4 10:18:53 NAS1 kernel: res 50/00:00:cf:a6:37/00:00:04:00:00/e0 Emask 0x10 (ATA bus error) Dec 4 10:18:53 NAS1 kernel: ata1.00: status: { DRDY } Dec 4 10:18:53 NAS1 kernel: ata1: hard resetting link Dec 4 10:18:53 NAS1 kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 4 10:18:53 NAS1 kernel: ata1.00: configured for UDMA/133 Dec 4 10:18:53 NAS1 kernel: ata1: EH complete
-
Attached! Thanks nas1-diagnostics-20181203-1848.zip
-
Last week I took advantage of the low price of the a Samsung 860 1TB SSD so I could replace my quite old WD Black 1TB cache drive and an older 128GB Samsung SSD used as an apps drive (from SNAP days) The cutover to the new SSD when very smooth and I was able to move my VM/Dockers off my app drive without any issue. My end result was removing two drives and replacing them with the new SSD. The problem is I keep getting errors at boot and in the log every so often. I *thought* it had something to do with NCQ (which is forced off) but it's still error hours later. Below, notice the SATA link up at 1.5 Gbps. Everything seems to work, I've used plex docker quite a bit and have a Windows VM running on this drive too. No user/noticeable issues Also, I'm on SATA Cable #3. The last I opened the case last night I replaced all 7 of them with brand new Monoprice 18" cables. Any help would be greatly appreciated. Let me know if I should attach diagnostics. Dec 3 15:19:36 NAS1 kernel: ata5.00: exception Emask 0x10 SAct 0x7fffefff SErr 0x0 action 0x6 frozen Dec 3 15:19:36 NAS1 kernel: ata5.00: irq_stat 0x08000000, interface fatal error ~ <lots of entries> Dec 3 15:19:36 NAS1 kernel: ata5.00: status: { DRDY } Dec 3 15:19:36 NAS1 kernel: ata5.00: failed command: WRITE FPDMA QUEUED Dec 3 15:19:36 NAS1 kernel: ata5.00: cmd 61/10:e8:70:4d:1c/00:00:1d:00:00/40 tag 29 ncq dma 8192 out Dec 3 15:19:36 NAS1 kernel: res 40/00:68:70:46:1c/00:00:1d:00:00/40 Emask 0x10 (ATA bus error) Dec 3 15:19:36 NAS1 kernel: ata5.00: status: { DRDY } Dec 3 15:19:36 NAS1 kernel: ata5.00: failed command: WRITE FPDMA QUEUED Dec 3 15:19:36 NAS1 kernel: ata5.00: cmd 61/a8:f0:c0:4d:1c/00:00:1d:00:00/40 tag 30 ncq dma 86016 out Dec 3 15:19:36 NAS1 kernel: res 40/00:68:70:46:1c/00:00:1d:00:00/40 Emask 0x10 (ATA bus error) Dec 3 15:19:36 NAS1 kernel: ata5.00: status: { DRDY } Dec 3 15:19:36 NAS1 kernel: ata5: hard resetting link Dec 3 15:19:36 NAS1 kernel: ata5: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Dec 3 15:19:36 NAS1 kernel: ata5.00: supports DRM functions and may not be fully accessible Dec 3 15:19:36 NAS1 kernel: ata5.00: supports DRM functions and may not be fully accessible Dec 3 15:19:36 NAS1 kernel: ata5.00: configured for UDMA/133 Dec 3 15:19:36 NAS1 kernel: ata5: EH complete Dec 3 15:19:36 NAS1 kernel: ata5.00: Enabling discard_zeroes_data Here's from earlier today. (notice the 6.0 Gbps) Dec 2 20:45:33 NAS1 kernel: ata9.00: exception Emask 0x10 SAct 0x0 SErr 0x400000 action 0x6 frozen Dec 2 20:45:33 NAS1 kernel: ata9.00: irq_stat 0x08000000, interface fatal error Dec 2 20:45:33 NAS1 kernel: ata9: SError: { Handshk } Dec 2 20:45:33 NAS1 kernel: ata9.00: failed command: WRITE DMA EXT Dec 2 20:45:33 NAS1 kernel: ata9.00: cmd 35/00:40:b8:2e:89/00:05:14:00:00/e0 tag 10 dma 688128 out Dec 2 20:45:33 NAS1 kernel: res 50/00:00:b7:2e:89/00:00:14:00:00/e0 Emask 0x10 (ATA bus error) Dec 2 20:45:33 NAS1 kernel: ata9.00: status: { DRDY } Dec 2 20:45:33 NAS1 kernel: ata9: hard resetting link Dec 2 20:45:34 NAS1 kernel: ata9: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 2 20:45:34 NAS1 kernel: ata9.00: configured for UDMA/133 Dec 2 20:45:34 NAS1 kernel: ata9: EH complete No errors shown here, passes smart test During boot up things SEEM to come up ok. then ~23 seconds later it errors out, comes back up, errors out, comes up, gets limited to 3.0, errors out. At one point over night it made it like 4 hours w/o erroring (no activity I guess) Dec 2 20:10:22 NAS1 kernel: EDAC MC0: Giving out device to module amd64_edac controller F15h: DEV 0000:00:18.3 (INTERRUPT) Dec 2 20:10:22 NAS1 kernel: EDAC PCI0: Giving out device to module amd64_edac controller EDAC PCI controller: DEV 0000:00:18.2 (POLLED) Dec 2 20:10:22 NAS1 kernel: AMD64 EDAC driver v3.5.0 Dec 2 20:10:22 NAS1 kernel: ata7: SATA link down (SStatus 0 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata9: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata5: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata2: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata4: SATA link up 3.0 Gbps (SStatus 123 SControl 300) Dec 2 20:10:22 NAS1 kernel: ata5.00: supports DRM functions and may not be fully accessible Dec 2 20:10:22 NAS1 kernel: ata9.00: ATA-9: WDC WD40EFRX-68WT0N0, WD-WCC4E0ELT95A, 82.00A82, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata9.00: 7814037168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata1.00: ATA-9: WDC WD20EZRX-00DC0B0, WD-WCC1T0586104, 80.00A80, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata1.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata9.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata5.00: ATA-11: Samsung SSD 860 EVO 1TB, S3Z8NB0KB64216A, RVT02B6Q, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata5.00: 1953525168 sectors, multi 1: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata1.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: scsi 1:0:0:0: Direct-Access ATA WDC WD20EZRX-00D 0A80 PQ: 0 ANSI: 5 Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: Attached scsi generic sg1 type 0 Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: [sdb] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB) Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: [sdb] 4096-byte physical blocks Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: [sdb] Write Protect is off Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: [sdb] Mode Sense: 00 3a 00 00 Dec 2 20:10:22 NAS1 kernel: sd 1:0:0:0: [sdb] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 2 20:10:22 NAS1 kernel: ata5.00: supports DRM functions and may not be fully accessible Dec 2 20:10:22 NAS1 kernel: ata4.00: ATA-8: WDC WD20EARS-00MVWB0, WD-WMAZA3795145, 51.0AB51, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata4.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata3.00: ATA-8: WDC WD20EARS-00MVWB0, WD-WMAZA3812777, 51.0AB51, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata3.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata2.00: ATA-8: WDC WD20EARS-00MVWB0, WD-WMAZA3745610, 51.0AB51, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata2.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata5.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata6.00: ATA-8: WDC WD20EARX-00PASB0, WD-WCAZAC344236, 51.0AB51, max UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata6.00: 3907029168 sectors, multi 16: LBA48 NCQ (depth 31/32), AA Dec 2 20:10:22 NAS1 kernel: ata4.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata3.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: ata2.00: configured for UDMA/133 Dec 2 20:10:22 NAS1 kernel: scsi 2:0:0:0: Direct-Access ATA WDC WD20EARS-00M AB51 PQ: 0 ANSI: 5 Dec 2 20:10:22 NAS1 kernel: sd 2:0:0:0: Attached scsi generic sg2 type 0 Dec 2 20:10:22 NAS1 kernel: sd 2:0:0:0: [sdc] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB) Dec 2 20:10:22 NAS1 kernel: sd 2:0:0:0: [sdc] Write Protect is off Dec 2 20:10:22 NAS1 kernel: sd 2:0:0:0: [sdc] Mode Sense: 00 3a 00 00 Dec 2 20:10:22 NAS1 kernel: sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 2 20:10:22 NAS1 kernel: scsi 3:0:0:0: Direct-Access ATA WDC WD20EARS-00M AB51 PQ: 0 ANSI: 5 Dec 2 20:10:22 NAS1 kernel: sd 3:0:0:0: Attached scsi generic sg3 type 0 Dec 2 20:10:22 NAS1 kernel: sd 3:0:0:0: [sdd] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB) Dec 2 20:10:22 NAS1 kernel: sd 3:0:0:0: [sdd] Write Protect is off Dec 2 20:10:22 NAS1 kernel: sd 3:0:0:0: [sdd] Mode Sense: 00 3a 00 00 Dec 2 20:10:22 NAS1 kernel: sd 3:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 2 20:10:22 NAS1 kernel: scsi 4:0:0:0: Direct-Access ATA WDC WD20EARS-00M AB51 PQ: 0 ANSI: 5 Dec 2 20:10:22 NAS1 kernel: sd 4:0:0:0: [sde] 3907029168 512-byte logical blocks: (2.00 TB/1.82 TiB) Dec 2 20:10:22 NAS1 kernel: sd 4:0:0:0: Attached scsi generic sg4 type 0 Dec 2 20:10:22 NAS1 kernel: sd 4:0:0:0: [sde] Write Protect is off Dec 2 20:10:22 NAS1 kernel: sd 4:0:0:0: [sde] Mode Sense: 00 3a 00 00 Dec 2 20:10:22 NAS1 kernel: sd 4:0:0:0: [sde] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 2 20:10:22 NAS1 kernel: scsi 5:0:0:0: Direct-Access ATA Samsung SSD 860 2B6Q PQ: 0 ANSI: 5 Dec 2 20:10:22 NAS1 kernel: ata5.00: Enabling discard_zeroes_data Dec 2 20:10:22 NAS1 kernel: sd 5:0:0:0: [sdf] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB) Dec 2 20:10:22 NAS1 kernel: sd 5:0:0:0: [sdf] Write Protect is off Dec 2 20:10:22 NAS1 kernel: sd 5:0:0:0: [sdf] Mode Sense: 00 3a 00 00 Dec 2 20:10:22 NAS1 kernel: sd 5:0:0:0: [sdf] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Dec 2 20:10:22 NAS1 kernel: sd 5:0:0:0: Attached scsi generic sg5 type 0 Dec 2 20:10:22 NAS1 kernel: ata5.00: Enabling discard_zeroes_data

-
Thanks, that is my opinion as well. After reseating the connectors, The Parity Sync did complete w/o errors. Fingers crossed it was a one time issue.
-
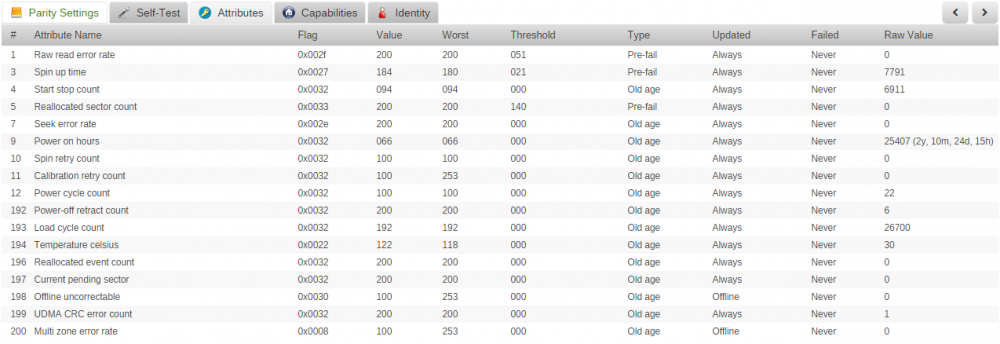
At about 9am this morning I got an email saying that my parity drive was down. Event: unRAID Parity disk error Subject: Alert [NAS1] - Parity disk in error state (disk dsbl) Description: WDC_WD40EFRX-68WT0N0_WD-WCC4E0ELT95A (sdh) Importance: alert I'm home today, so I logged in to see a red x over parity. I downloaded diagnostics, and tried looking at smart/running smartctl from the command, but no luck. root@NAS1:/boot# smartctl -a -A -T permissive /dev/sdh > /boot/paritySMART.txt root@NAS1:/boot# cat paritySMART.txt smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.9.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org Short INQUIRY response, skip product id === START OF READ SMART DATA SECTION === SMART Health Status: OK Current Drive Temperature: 0 C Drive Trip Temperature: 0 C Read defect list: asked for grown list but didn't get it Error Counter logging not supported Device does not support Self Test logging not getting anything from smart I then shut the array down, walked down and opened/reseated the connectors to the Parity drive (and all drives) and looked around not seeing anything obviously wrong, so I started it back up. The drive powered up and appears to be error free from a smart perspective. smartctl runs and I can see attributes in the UI Because of this, my opinion was to just unassign, reassign the drive and let it rebuild, but that doesn't seem to be working. And that's what I'm doing now. But I'm curious if anyone has any opinion on what might have happened? Parity rebuild is just over 30% now and no errors detected. unRaid had been up 31 days, and 0 erros found on 8/1 parity check. One thing I forgot to check was if the drive was spinning/powered up. I am wondering if somehow it was not spinning which is why smartctl wasn't working, and even trying to through the UI (spin up drive) was failing. nas1-diagnostics-20180814-0906_preboot.zip nas1-diagnostics-20180814-0952_rebooted.zip
-
[DEPRECATED] Linuxserver.io - Rutorrent
Dmtalon replied to linuxserver.io's topic in Docker Containers
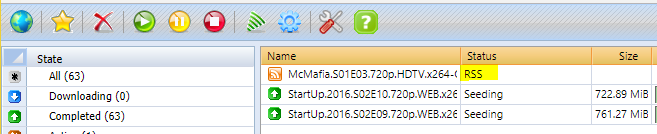
should RSS be able to auto-download? I thought I had this setup working but now it's doesn't seem to. Torrents come in via RSS as a status of RSS and I have to manually click on them to load them.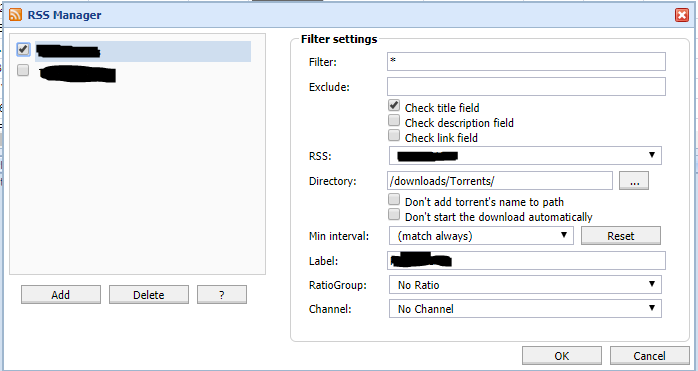
-
Stable unRAID started having issues (corrupt cache/app)
Dmtalon replied to Dmtalon's topic in General Support
So, as an update. I let memtest run 4 tests (about 19 hours) and it found no errors. I've decided to try going back to my previous build of unRAID (6.3.5) (did a full restore of the zip I took before upgrading). Put my app drive and cache spinner back in, and rebooted. I copied off the date from the app drive, cleaned it up by reformatting it, then moved my VM/Dockers back on. Things seem back up, and no errors in the log(yet). I'm about 20% through a parity check now. Once that completes I'll try some tests load tests within the VM to see if the problem returns. I'm starting to wonder if it's a 6.5.0 issues, but time will tell I guess.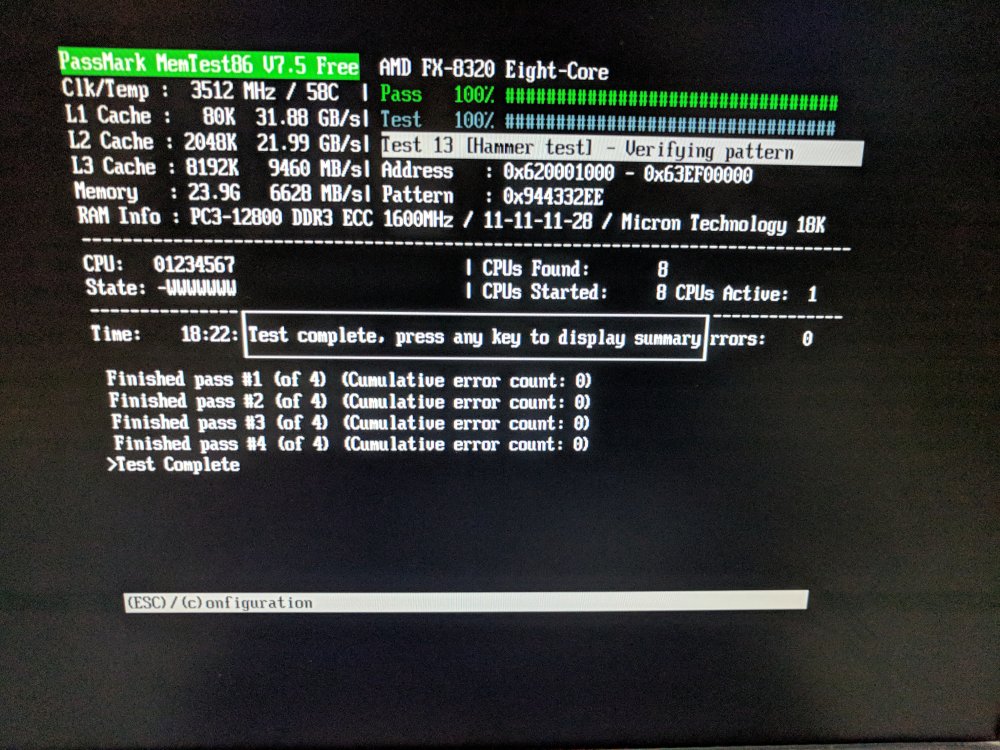
-
Stable unRAID started having issues (corrupt cache/app)
Dmtalon replied to Dmtalon's topic in General Support
So, I cleaned up the cache drive, formatted it clean and deleted the libvirt image and started fresh. Started installing windows again fresh. While trying to install a service pack I see this pop up in the logs. No indication there were any issues until just now. (no errors in log) I shut everything down, and reseated the ram, and am running memtest86 on it. We'll see what happens I guess. MB/Build is from 9/2014 ASUS SABERTOOTH 990FX R2.0 AMD BOX AMD FX-8320 BLACK ED CRUCIAL 8GB D3 1333 ECC x3 XFX HD5450 1GB D3 DVH PCIE Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): Metadata CRC error detected at xfs_buf_ioend+0x49/0x9c [xfs], xfs_bmbt block 0xdc5be0 Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): Unmount and run xfs_repair Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): First 64 bytes of corrupted metadata buffer: Apr 1 14:48:10 NAS1 kernel: ffff8805eaa44000: 42 4d 41 33 00 00 00 fb 00 00 00 00 02 04 96 d8 BMA3............ Apr 1 14:48:10 NAS1 kernel: ffff8805eaa44010: 00 00 00 00 02 04 85 2e 00 00 00 00 00 dc 5b e0 ..............[. Apr 1 14:48:10 NAS1 kernel: ffff8805eaa44020: 00 00 00 01 00 03 40 4c 87 94 a5 6c 31 ae 4b 35 [email protected] Apr 1 14:48:10 NAS1 kernel: ffff8805eaa44030: 9c 4c 12 72 8e 1b 67 1c 00 00 00 00 00 00 00 65 .L.r..g........e Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): metadata I/O error: block 0xdc5be0 ("xfs_trans_read_buf_map") error 74 numblks 8 Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): xfs_do_force_shutdown(0x1) called from line 315 of file fs/xfs/xfs_trans_buf.c. Return address = 0xffffffffa0254bea Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): I/O Error Detected. Shutting down filesystem Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): Please umount the filesystem and rectify the problem(s) Apr 1 14:48:10 NAS1 kernel: XFS (sdh1): writeback error on sector 246627368












